 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchWorld: Gradient-Free Optimization of Executable World Models
May 29, 2026Text-agent environments are typically modeled as partially observable Markov decision processes (POMDPs), assuming that the simulator's latent state and transition dynamics are hidden from the agent. Yet little work has examined whether executable code can be induced to serve as a world model for prediction and planning under partial observability. We introduce PatchWorld, a gradient-free framework that turns offline trajectories into executable Python world models through counterexample-guided code repair. Instead of predicting the next observation with a black-box model, PatchWorld induces symbolic belief-state programs whose action updates can be inspected, replayed, and locally patched. Across seven AgentGym environments, PatchWorld-Simple achieves the highest code-based planning score among evaluated methods, reaching 76.4\% macro success in live one-step lookahead while invoking no LLM calls inside the world-model prediction module itself. We further find that a human-specified residual-memory bias improves surface observation fidelity but weakens decision utility. This exposes a tradeoff in executable world models, since improving observation fidelity can come at the expense of action-discriminative dynamics, and vice versa. Code is available at https://github.com/HKBU-KnowComp/PatchWorld.
HypoAgent: An Agentic Framework for Interactive Abductive Hypothesis Generation over Knowledge Graphs
May 29, 2026Abductive reasoning over knowledge graphs aims to generate logical hypotheses that explain observed entities or facts. Existing controllable hypothesis generation methods allow users to guide this process with explicit conditions, but they remain limited in interactive settings: they struggle to ground evolving natural-language intents across multi-turn dialogues and provide little fine-grained diagnosis when generated hypotheses fail. To address these limitations, we propose HypoAgent, an Agentic framework for interactive abductive Hypothesis Generation over knowledge graphs. HypoAgent integrates three agents: an Intent Recognition Agent that grounds user utterances and dialogue history into executable KG conditions, a Hypothesis Generation Agent that performs controllable hypothesis generation according to the extracted user intention, and a Root Cause Analysis Agent that diagnoses unreliable hypothesis fragments and leverages KG neighborhood probing to identify supported refinements. Experiments on commonsense and biomedical domain-specific knowledge graphs demonstrate that HypoAgent achieves state-of-the-art semantic similarity under single-turn, multi-turn, and unconditional settings. Our code is available at https://github.com/HKUST-KnowComp/HypoAgent.
Can LLMs Time Travel? Enhancing Temporal Consistency in Legal Agentic Search through Reinforcement Learning
May 25, 2026While large language models (LLMs) augmented with agentic search capabilities show promise for legal reasoning, they overlook a fundamental constraint that applicable law must match the temporal context of each case, as retroactive application of statutes violates core legal principles and leads to erroneous conclusions. Our observations reveal that current legal LLMs suffer from temporal bias anchored to their training cutoff, while search agents rarely incorporate temporal constraints into queries, and that web search alone cannot provide the precise statute and precedent citations that legal reasoning demands. To address these challenges, we propose LegalSearch-R1, an end-to-end reinforcement learning framework that pairs local statute RAG for precise article matching with online web search for broader legal knowledge, trained on temporally-indexed data spanning multiple amendment periods to enforce temporal consistency. Extensive experiments on our benchmark covering 13 legal tasks demonstrate that our 7B-parameter agent outperforms state-of-the-art deep research frameworks and specialized legal LLMs by 12.9% to 29.8%, surpasses baselines by 57.7% to 80.3% on temporal consistency, and exhibits robust out-of-domain generalization. The code and data are available at https://github.com/AlexFanw/LegalSearch-R1.
MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
May 14, 2026Memory is essential for large vision-language models (LVLMs) to handle long, multimodal interactions, with two method directions providing this capability: long-context LVLMs and memory-augmented agents. However, no existing benchmark conducts a systematic comparison of the two on questions that genuinely require multimodal evidence. To close this gap, we introduce MEMLENS, a comprehensive benchmark for memory in multimodal multi-session conversations, comprising 789 questions across five memory abilities (information extraction, multi-session reasoning, temporal reasoning, knowledge update, and answer refusal) at four standard context lengths (32K-256K tokens) under a cross-modal token-counting scheme. An image-ablation study confirms that solving MEMLENS requires visual evidence: removing evidence images drops two frontier LVLMs below 2% accuracy on the 80.4% of questions whose evidence includes images. Evaluating 27 LVLMs and 7 memory-augmented agents, we find that long-context LVLMs achieve high short-context accuracy through direct visual grounding but degrade as conversations grow, whereas memory agents are length-stable but lose visual fidelity under storage-time compression. Multi-session reasoning caps most systems below 30%, and neither approach alone solves the task. These results motivate hybrid architectures that combine long-context attention with structured multimodal retrieval. Our code is available at https://github.com/xrenaf/MEMLENS.
NAACL: Noise-AwAre Verbal Confidence Calibration for LLMs in RAG Systems
Jan 16, 2026Accurately assessing model confidence is essential for deploying large language models (LLMs) in mission-critical factual domains. While retrieval-augmented generation (RAG) is widely adopted to improve grounding, confidence calibration in RAG settings remains poorly understood. We conduct a systematic study across four benchmarks, revealing that LLMs exhibit poor calibration performance due to noisy retrieved contexts. Specifically, contradictory or irrelevant evidence tends to inflate the model's false certainty, leading to severe overconfidence. To address this, we propose NAACL Rules (Noise-AwAre Confidence CaLibration Rules) to provide a principled foundation for resolving overconfidence under noise. We further design NAACL, a noise-aware calibration framework that synthesizes supervision from about 2K HotpotQA examples guided by these rules. By performing supervised fine-tuning (SFT) with this data, NAACL equips models with intrinsic noise awareness without relying on stronger teacher models. Empirical results show that NAACL yields substantial gains, improving ECE scores by 10.9% in-domain and 8.0% out-of-domain. By bridging the gap between retrieval noise and verbal calibration, NAACL paves the way for both accurate and epistemically reliable LLMs.
NewtonBench: Benchmarking Generalizable Scientific Law Discovery in LLM Agents
Oct 08, 2025Large language models are emerging as powerful tools for scientific law discovery, a foundational challenge in AI-driven science. However, existing benchmarks for this task suffer from a fundamental methodological trilemma, forcing a trade-off between scientific relevance, scalability, and resistance to memorization. Furthermore, they oversimplify discovery as static function fitting, failing to capture the authentic scientific process of uncovering embedded laws through the interactive exploration of complex model systems. To address these critical gaps, we introduce NewtonBench, a benchmark comprising 324 scientific law discovery tasks across 12 physics domains. Our design mitigates the evaluation trilemma by using metaphysical shifts - systematic alterations of canonical laws - to generate a vast suite of problems that are scalable, scientifically relevant, and memorization-resistant. Moreover, we elevate the evaluation from static function fitting to interactive model discovery, requiring agents to experimentally probe simulated complex systems to uncover hidden principles. Our extensive experiment reveals a clear but fragile capability for discovery in frontier LLMs: this ability degrades precipitously with increasing system complexity and exhibits extreme sensitivity to observational noise. Notably, we uncover a paradoxical effect of tool assistance: providing a code interpreter can hinder more capable models by inducing a premature shift from exploration to exploitation, causing them to satisfice on suboptimal solutions. These results demonstrate that robust, generalizable discovery in complex, interactive environments remains the core challenge. By providing a scalable, robust, and scientifically authentic testbed, NewtonBench offers a crucial tool for measuring true progress and guiding the development of next-generation AI agents capable of genuine scientific discovery.
The Cognitive Bandwidth Bottleneck: Shifting Long-Horizon Agent from Planning with Actions to Planning with Schemas
Oct 08, 2025Enabling LLMs to effectively operate long-horizon task which requires long-term planning and multiple interactions is essential for open-world autonomy. Conventional methods adopt planning with actions where a executable action list would be provided as reference. However, this action representation choice would be impractical when the environment action space is combinatorial exploded (e.g., open-ended real world). This naturally leads to a question: As environmental action space scales, what is the optimal action representation for long-horizon agents? In this paper, we systematically study the effectiveness of two different action representations. The first one is conventional planning with actions (PwA) which is predominantly adopted for its effectiveness on existing benchmarks. The other one is planning with schemas (PwS) which instantiate an action schema into action lists (e.g., "move [OBJ] to [OBJ]" -> "move apple to desk") to ensure concise action space and reliable scalability. This alternative is motivated by its alignment with human cognition and its compliance with environment-imposed action format restriction. We propose cognitive bandwidth perspective as a conceptual framework to qualitatively understand the differences between these two action representations and empirically observe a representation-choice inflection point between ALFWorld (~35 actions) and SciWorld (~500 actions), which serve as evidence of the need for scalable representations. We further conduct controlled experiments to study how the location of this inflection point interacts with different model capacities: stronger planning proficiency shifts the inflection rightward, whereas better schema instantiation shifts it leftward. Finally, noting the suboptimal performance of PwS agents, we provide an actionable guide for building more capable PwS agents for better scalable autonomy.
LLM-Hanabi: Evaluating Multi-Agent Gameplays with Theory-of-Mind and Rationale Inference in Imperfect Information Collaboration Game
Oct 06, 2025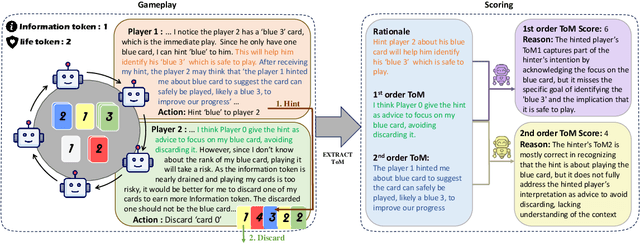
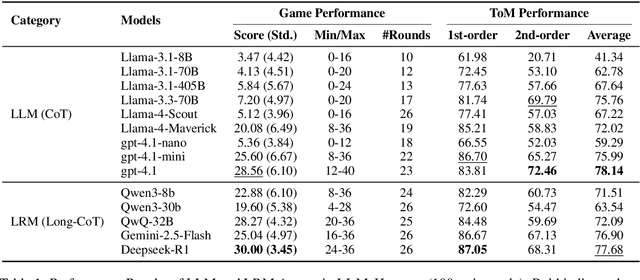
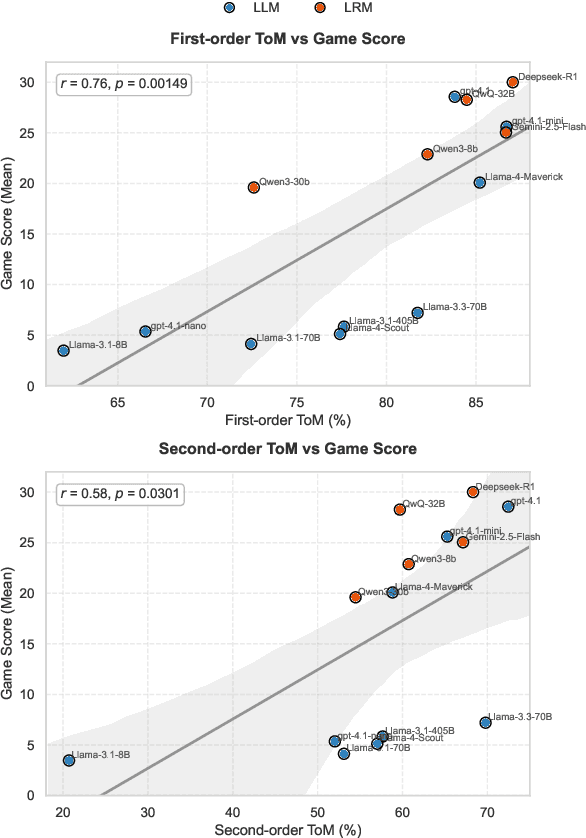
Effective multi-agent collaboration requires agents to infer the rationale behind others' actions, a capability rooted in Theory-of-Mind (ToM). While recent Large Language Models (LLMs) excel at logical inference, their ability to infer rationale in dynamic, collaborative settings remains under-explored. This study introduces LLM-Hanabi, a novel benchmark that uses the cooperative game Hanabi to evaluate the rationale inference and ToM of LLMs. Our framework features an automated evaluation system that measures both game performance and ToM proficiency. Across a range of models, we find a significant positive correlation between ToM and in-game success. Notably, first-order ToM (interpreting others' intent) correlates more strongly with performance than second-order ToM (predicting others' interpretations). These findings highlight that for effective AI collaboration, the ability to accurately interpret a partner's rationale is more critical than higher-order reasoning. We conclude that prioritizing first-order ToM is a promising direction for enhancing the collaborative capabilities of future models.
Structuring the Unstructured: A Systematic Review of Text-to-Structure Generation for Agentic AI with a Universal Evaluation Framework
Aug 17, 2025



The evolution of AI systems toward agentic operation and context-aware retrieval necessitates transforming unstructured text into structured formats like tables, knowledge graphs, and charts. While such conversions enable critical applications from summarization to data mining, current research lacks a comprehensive synthesis of methodologies, datasets, and metrics. This systematic review examines text-to-structure techniques and the encountered challenges, evaluates current datasets and assessment criteria, and outlines potential directions for future research. We also introduce a universal evaluation framework for structured outputs, establishing text-to-structure as foundational infrastructure for next-generation AI systems.
Prospect Theory Fails for LLMs: Revealing Instability of Decision-Making under Epistemic Uncertainty
Aug 12, 2025



Prospect Theory (PT) models human decision-making under uncertainty, while epistemic markers (e.g., maybe) serve to express uncertainty in language. However, it remains largely unexplored whether Prospect Theory applies to contemporary Large Language Models and whether epistemic markers, which express human uncertainty, affect their decision-making behaviour. To address these research gaps, we design a three-stage experiment based on economic questionnaires. We propose a more general and precise evaluation framework to model LLMs' decision-making behaviour under PT, introducing uncertainty through the empirical probability values associated with commonly used epistemic markers in comparable contexts. We then incorporate epistemic markers into the evaluation framework based on their corresponding probability values to examine their influence on LLM decision-making behaviours. Our findings suggest that modelling LLMs' decision-making with PT is not consistently reliable, particularly when uncertainty is expressed in diverse linguistic forms. Our code is released in https://github.com/HKUST-KnowComp/MarPT.