 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Image Aesthetic Assessment: Learning Discriminative Scores from Relative Ranks
Mar 04, 2026Image aesthetic assessment (IAA) has extensive applications in content creation, album management, and recommendation systems, etc. In such applications, it is commonly needed to pick out the most aesthetically pleasing image from a series of images with subtle aesthetic variations, a topic we refer to as fine-grained IAA. Unfortunately, state-of-the-art IAA models are typically designed for coarse-grained evaluation, where images with notable aesthetic differences are evaluated independently on an absolute scale. These models are inherently limited in discriminating fine-grained aesthetic differences. To address the dilemma, we contribute FGAesthetics, a fine-grained IAA database with 32,217 images organized into 10,028 series, which are sourced from diverse categories including Natural, AIGC, and Cropping. Annotations are collected via pairwise comparisons within each series. We also devise Series Refinement and Rank Calibration to ensure the reliability of data and labels. Based on FGAesthetics, we further propose FGAesQ, a novel IAA framework that learns discriminative aesthetic scores from relative ranks through Difference-preserved Tokenization (DiffToken), Comparative Text-assisted Alignment (CTAlign), and Rank-aware Regression (RankReg). FGAesQ enables accurate aesthetic assessment in fine-grained scenarios while still maintains competitive performance in coarse-grained evaluation. Extensive experiments and comparisons demonstrate the superiority of the proposed method.
HyperAlign: Hyperbolic Entailment Cones for Adaptive Text-to-Image Alignment Assessment
Jan 08, 2026With the rapid development of text-to-image generation technology, accurately assessing the alignment between generated images and text prompts has become a critical challenge. Existing methods rely on Euclidean space metrics, neglecting the structured nature of semantic alignment, while lacking adaptive capabilities for different samples. To address these limitations, we propose HyperAlign, an adaptive text-to-image alignment assessment framework based on hyperbolic entailment geometry. First, we extract Euclidean features using CLIP and map them to hyperbolic space. Second, we design a dynamic-supervision entailment modeling mechanism that transforms discrete entailment logic into continuous geometric structure supervision. Finally, we propose an adaptive modulation regressor that utilizes hyperbolic geometric features to generate sample-level modulation parameters, adaptively calibrating Euclidean cosine similarity to predict the final score. HyperAlign achieves highly competitive performance on both single database evaluation and cross-database generalization tasks, fully validating the effectiveness of hyperbolic geometric modeling for image-text alignment assessment.
Towards Syn-to-Real IQA: A Novel Perspective on Reshaping Synthetic Data Distributions
Jan 01, 2026Blind Image Quality Assessment (BIQA) has advanced significantly through deep learning, but the scarcity of large-scale labeled datasets remains a challenge. While synthetic data offers a promising solution, models trained on existing synthetic datasets often show limited generalization ability. In this work, we make a key observation that representations learned from synthetic datasets often exhibit a discrete and clustered pattern that hinders regression performance: features of high-quality images cluster around reference images, while those of low-quality images cluster based on distortion types. Our analysis reveals that this issue stems from the distribution of synthetic data rather than model architecture. Consequently, we introduce a novel framework SynDR-IQA, which reshapes synthetic data distribution to enhance BIQA generalization. Based on theoretical derivations of sample diversity and redundancy's impact on generalization error, SynDR-IQA employs two strategies: distribution-aware diverse content upsampling, which enhances visual diversity while preserving content distribution, and density-aware redundant cluster downsampling, which balances samples by reducing the density of densely clustered areas. Extensive experiments across three cross-dataset settings (synthetic-to-authentic, synthetic-to-algorithmic, and synthetic-to-synthetic) demonstrate the effectiveness of our method. The code is available at https://github.com/Li-aobo/SynDR-IQA.
LongT2IBench: A Benchmark for Evaluating Long Text-to-Image Generation with Graph-structured Annotations
Dec 10, 2025The increasing popularity of long Text-to-Image (T2I) generation has created an urgent need for automatic and interpretable models that can evaluate the image-text alignment in long prompt scenarios. However, the existing T2I alignment benchmarks predominantly focus on short prompt scenarios and only provide MOS or Likert scale annotations. This inherent limitation hinders the development of long T2I evaluators, particularly in terms of the interpretability of alignment. In this study, we contribute LongT2IBench, which comprises 14K long text-image pairs accompanied by graph-structured human annotations. Given the detail-intensive nature of long prompts, we first design a Generate-Refine-Qualify annotation protocol to convert them into textual graph structures that encompass entities, attributes, and relations. Through this transformation, fine-grained alignment annotations are achieved based on these granular elements. Finally, the graph-structed annotations are converted into alignment scores and interpretations to facilitate the design of T2I evaluation models. Based on LongT2IBench, we further propose LongT2IExpert, a LongT2I evaluator that enables multi-modal large language models (MLLMs) to provide both quantitative scores and structured interpretations through an instruction-tuning process with Hierarchical Alignment Chain-of-Thought (CoT). Extensive experiments and comparisons demonstrate the superiority of the proposed LongT2IExpert in alignment evaluation and interpretation. Data and code have been released in https://welldky.github.io/LongT2IBench-Homepage/.
Content-Adaptive Image Retouching Guided by Attribute-Based Text Representation
Dec 10, 2025Image retouching has received significant attention due to its ability to achieve high-quality visual content. Existing approaches mainly rely on uniform pixel-wise color mapping across entire images, neglecting the inherent color variations induced by image content. This limitation hinders existing approaches from achieving adaptive retouching that accommodates both diverse color distributions and user-defined style preferences. To address these challenges, we propose a novel Content-Adaptive image retouching method guided by Attribute-based Text Representation (CA-ATP). Specifically, we propose a content-adaptive curve mapping module, which leverages a series of basis curves to establish multiple color mapping relationships and learns the corresponding weight maps, enabling content-aware color adjustments. The proposed module can capture color diversity within the image content, allowing similar color values to receive distinct transformations based on their spatial context. In addition, we propose an attribute text prediction module that generates text representations from multiple image attributes, which explicitly represent user-defined style preferences. These attribute-based text representations are subsequently integrated with visual features via a multimodal model, providing user-friendly guidance for image retouching. Extensive experiments on several public datasets demonstrate that our method achieves state-of-the-art performance.
TuningIQA: Fine-Grained Blind Image Quality Assessment for Livestreaming Camera Tuning
Aug 25, 2025



Livestreaming has become increasingly prevalent in modern visual communication, where automatic camera quality tuning is essential for delivering superior user Quality of Experience (QoE). Such tuning requires accurate blind image quality assessment (BIQA) to guide parameter optimization decisions. Unfortunately, the existing BIQA models typically only predict an overall coarse-grained quality score, which cannot provide fine-grained perceptual guidance for precise camera parameter tuning. To bridge this gap, we first establish FGLive-10K, a comprehensive fine-grained BIQA database containing 10,185 high-resolution images captured under varying camera parameter configurations across diverse livestreaming scenarios. The dataset features 50,925 multi-attribute quality annotations and 19,234 fine-grained pairwise preference annotations. Based on FGLive-10K, we further develop TuningIQA, a fine-grained BIQA metric for livestreaming camera tuning, which integrates human-aware feature extraction and graph-based camera parameter fusion. Extensive experiments and comparisons demonstrate that TuningIQA significantly outperforms state-of-the-art BIQA methods in both score regression and fine-grained quality ranking, achieving superior performance when deployed for livestreaming camera tuning.
Fine-grained Image Quality Assessment for Perceptual Image Restoration
Aug 20, 2025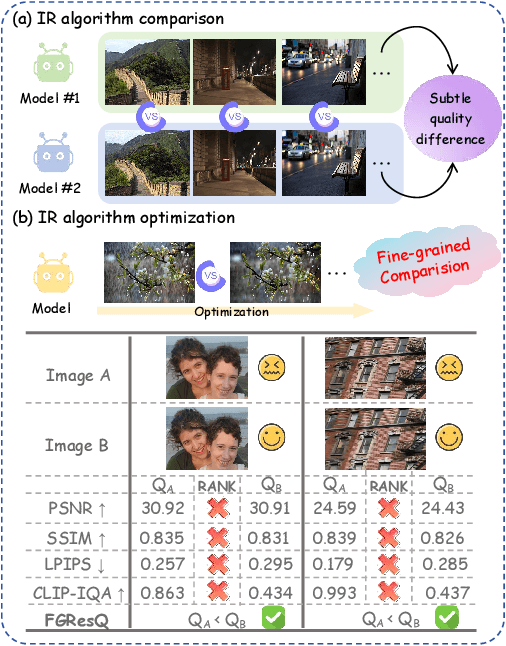

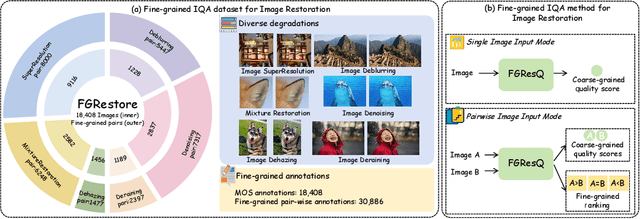

Recent years have witnessed remarkable achievements in perceptual image restoration (IR), creating an urgent demand for accurate image quality assessment (IQA), which is essential for both performance comparison and algorithm optimization. Unfortunately, the existing IQA metrics exhibit inherent weakness for IR task, particularly when distinguishing fine-grained quality differences among restored images. To address this dilemma, we contribute the first-of-its-kind fine-grained image quality assessment dataset for image restoration, termed FGRestore, comprising 18,408 restored images across six common IR tasks. Beyond conventional scalar quality scores, FGRestore was also annotated with 30,886 fine-grained pairwise preferences. Based on FGRestore, a comprehensive benchmark was conducted on the existing IQA metrics, which reveal significant inconsistencies between score-based IQA evaluations and the fine-grained restoration quality. Motivated by these findings, we further propose FGResQ, a new IQA model specifically designed for image restoration, which features both coarse-grained score regression and fine-grained quality ranking. Extensive experiments and comparisons demonstrate that FGResQ significantly outperforms state-of-the-art IQA metrics. Codes and model weights have been released in https://pxf0429.github.io/FGResQ/
Language-Guided Visual Perception Disentanglement for Image Quality Assessment and Conditional Image Generation
Mar 04, 2025Contrastive vision-language models, such as CLIP, have demonstrated excellent zero-shot capability across semantic recognition tasks, mainly attributed to the training on a large-scale I&1T (one Image with one Text) dataset. This kind of multimodal representations often blend semantic and perceptual elements, placing a particular emphasis on semantics. However, this could be problematic for popular tasks like image quality assessment (IQA) and conditional image generation (CIG), which typically need to have fine control on perceptual and semantic features. Motivated by the above facts, this paper presents a new multimodal disentangled representation learning framework, which leverages disentangled text to guide image disentanglement. To this end, we first build an I&2T (one Image with a perceptual Text and a semantic Text) dataset, which consists of disentangled perceptual and semantic text descriptions for an image. Then, the disentangled text descriptions are utilized as supervisory signals to disentangle pure perceptual representations from CLIP's original `coarse' feature space, dubbed DeCLIP. Finally, the decoupled feature representations are used for both image quality assessment (technical quality and aesthetic quality) and conditional image generation. Extensive experiments and comparisons have demonstrated the advantages of the proposed method on the two popular tasks. The dataset, code, and model will be available.
A Multi-annotated and Multi-modal Dataset for Wide-angle Video Quality Assessment
Jan 21, 2025Wide-angle video is favored for its wide viewing angle and ability to capture a large area of scenery, making it an ideal choice for sports and adventure recording. However, wide-angle video is prone to deformation, exposure and other distortions, resulting in poor video quality and affecting the perception and experience, which may seriously hinder its application in fields such as competitive sports. Up to now, few explorations focus on the quality assessment issue of wide-angle video. This deficiency primarily stems from the absence of a specialized dataset for wide-angle videos. To bridge this gap, we construct the first Multi-annotated and multi-modal Wide-angle Video quality assessment (MWV) dataset. Then, the performances of state-of-the-art video quality methods on the MWV dataset are investigated by inter-dataset testing and intra-dataset testing. Experimental results show that these methods impose significant limitations on their applicability.
AI-Generated Image Quality Assessment Based on Task-Specific Prompt and Multi-Granularity Similarity
Nov 25, 2024



Recently, AI-generated images (AIGIs) created by given prompts (initial prompts) have garnered widespread attention. Nevertheless, due to technical nonproficiency, they often suffer from poor perception quality and Text-to-Image misalignment. Therefore, assessing the perception quality and alignment quality of AIGIs is crucial to improving the generative model's performance. Existing assessment methods overly rely on the initial prompts in the task prompt design and use the same prompts to guide both perceptual and alignment quality evaluation, overlooking the distinctions between the two tasks. To address this limitation, we propose a novel quality assessment method for AIGIs named TSP-MGS, which designs task-specific prompts and measures multi-granularity similarity between AIGIs and the prompts. Specifically, task-specific prompts are first constructed to describe perception and alignment quality degrees separately, and the initial prompt is introduced for detailed quality perception. Then, the coarse-grained similarity between AIGIs and task-specific prompts is calculated, which facilitates holistic quality awareness. In addition, to improve the understanding of AIGI details, the fine-grained similarity between the image and the initial prompt is measured. Finally, precise quality prediction is acquired by integrating the multi-granularity similarities. Experiments on the commonly used AGIQA-1K and AGIQA-3K benchmarks demonstrate the superiority of the proposed TSP-MGS.