 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025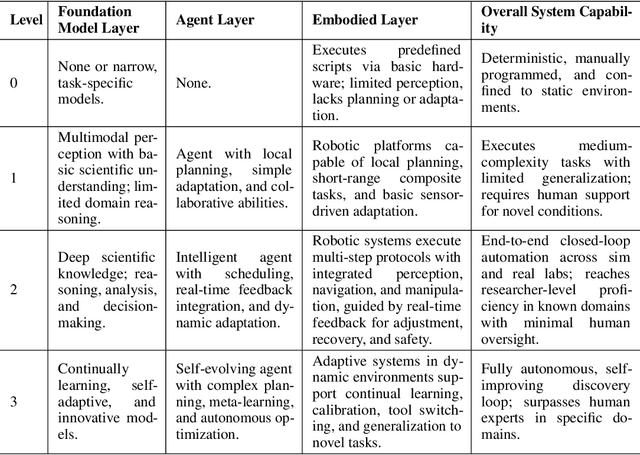
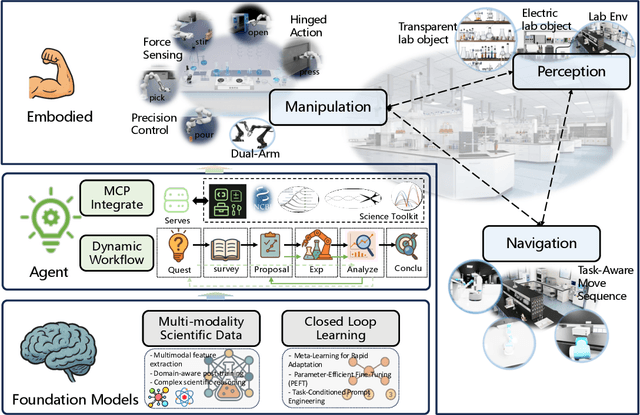
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.
Text to Image for Multi-Label Image Recognition with Joint Prompt-Adapter Learning
Jun 12, 2025



Benefited from image-text contrastive learning, pre-trained vision-language models, e.g., CLIP, allow to direct leverage texts as images (TaI) for parameter-efficient fine-tuning (PEFT). While CLIP is capable of making image features to be similar to the corresponding text features, the modality gap remains a nontrivial issue and limits image recognition performance of TaI. Using multi-label image recognition (MLR) as an example, we present a novel method, called T2I-PAL to tackle the modality gap issue when using only text captions for PEFT. The core design of T2I-PAL is to leverage pre-trained text-to-image generation models to generate photo-realistic and diverse images from text captions, thereby reducing the modality gap. To further enhance MLR, T2I-PAL incorporates a class-wise heatmap and learnable prototypes. This aggregates local similarities, making the representation of local visual features more robust and informative for multi-label recognition. For better PEFT, we further combine both prompt tuning and adapter learning to enhance classification performance. T2I-PAL offers significant advantages: it eliminates the need for fully semantically annotated training images, thereby reducing the manual annotation workload, and it preserves the intrinsic mode of the CLIP model, allowing for seamless integration with any existing CLIP framework. Extensive experiments on multiple benchmarks, including MS-COCO, VOC2007, and NUS-WIDE, show that our T2I-PAL can boost recognition performance by 3.47% in average above the top-ranked state-of-the-art methods.
Image Demoiréing Using Dual Camera Fusion on Mobile Phones
Jun 10, 2025When shooting electronic screens, moir\'e patterns usually appear in captured images, which seriously affects the image quality. Existing image demoir\'eing methods face great challenges in removing large and heavy moir\'e. To address the issue, we propose to utilize Dual Camera fusion for Image Demoir\'eing (DCID), \ie, using the ultra-wide-angle (UW) image to assist the moir\'e removal of wide-angle (W) image. This is inspired by two motivations: (1) the two lenses are commonly equipped with modern smartphones, (2) the UW image generally can provide normal colors and textures when moir\'e exists in the W image mainly due to their different focal lengths. In particular, we propose an efficient DCID method, where a lightweight UW image encoder is integrated into an existing demoir\'eing network and a fast two-stage image alignment manner is present. Moreover, we construct a large-scale real-world dataset with diverse mobile phones and monitors, containing about 9,000 samples. Experiments on the dataset show our method performs better than state-of-the-art methods. Code and dataset are available at https://github.com/Mrduckk/DCID.
Rethinking Cross-Modal Interaction in Multimodal Diffusion Transformers
Jun 09, 2025



Multimodal Diffusion Transformers (MM-DiTs) have achieved remarkable progress in text-driven visual generation. However, even state-of-the-art MM-DiT models like FLUX struggle with achieving precise alignment between text prompts and generated content. We identify two key issues in the attention mechanism of MM-DiT, namely 1) the suppression of cross-modal attention due to token imbalance between visual and textual modalities and 2) the lack of timestep-aware attention weighting, which hinder the alignment. To address these issues, we propose \textbf{Temperature-Adjusted Cross-modal Attention (TACA)}, a parameter-efficient method that dynamically rebalances multimodal interactions through temperature scaling and timestep-dependent adjustment. When combined with LoRA fine-tuning, TACA significantly enhances text-image alignment on the T2I-CompBench benchmark with minimal computational overhead. We tested TACA on state-of-the-art models like FLUX and SD3.5, demonstrating its ability to improve image-text alignment in terms of object appearance, attribute binding, and spatial relationships. Our findings highlight the importance of balancing cross-modal attention in improving semantic fidelity in text-to-image diffusion models. Our codes are publicly available at \href{https://github.com/Vchitect/TACA}
Voyager: Long-Range and World-Consistent Video Diffusion for Explorable 3D Scene Generation
Jun 04, 2025Real-world applications like video gaming and virtual reality often demand the ability to model 3D scenes that users can explore along custom camera trajectories. While significant progress has been made in generating 3D objects from text or images, creating long-range, 3D-consistent, explorable 3D scenes remains a complex and challenging problem. In this work, we present Voyager, a novel video diffusion framework that generates world-consistent 3D point-cloud sequences from a single image with user-defined camera path. Unlike existing approaches, Voyager achieves end-to-end scene generation and reconstruction with inherent consistency across frames, eliminating the need for 3D reconstruction pipelines (e.g., structure-from-motion or multi-view stereo). Our method integrates three key components: 1) World-Consistent Video Diffusion: A unified architecture that jointly generates aligned RGB and depth video sequences, conditioned on existing world observation to ensure global coherence 2) Long-Range World Exploration: An efficient world cache with point culling and an auto-regressive inference with smooth video sampling for iterative scene extension with context-aware consistency, and 3) Scalable Data Engine: A video reconstruction pipeline that automates camera pose estimation and metric depth prediction for arbitrary videos, enabling large-scale, diverse training data curation without manual 3D annotations. Collectively, these designs result in a clear improvement over existing methods in visual quality and geometric accuracy, with versatile applications.
MIRAGE: Assessing Hallucination in Multimodal Reasoning Chains of MLLM
May 30, 2025Multimodal hallucination in multimodal large language models (MLLMs) restricts the correctness of MLLMs. However, multimodal hallucinations are multi-sourced and arise from diverse causes. Existing benchmarks fail to adequately distinguish between perception-induced hallucinations and reasoning-induced hallucinations. This failure constitutes a significant issue and hinders the diagnosis of multimodal reasoning failures within MLLMs. To address this, we propose the {\dataset} benchmark, which isolates reasoning hallucinations by constructing questions where input images are correctly perceived by MLLMs yet reasoning errors persist. {\dataset} introduces multi-granular evaluation metrics: accuracy, factuality, and LLMs hallucination score for hallucination quantification. Our analysis reveals that (1) the model scale, data scale, and training stages significantly affect the degree of logical, fabrication, and factual hallucinations; (2) current MLLMs show no effective improvement on spatial hallucinations caused by misinterpreted spatial relationships, indicating their limited visual reasoning capabilities; and (3) question types correlate with distinct hallucination patterns, highlighting targeted challenges and potential mitigation strategies. To address these challenges, we propose {\method}, a method that combines curriculum reinforcement fine-tuning to encourage models to generate logic-consistent reasoning chains by stepwise reducing learning difficulty, and collaborative hint inference to reduce reasoning complexity. {\method} establishes a baseline on {\dataset}, and reduces the logical hallucinations in original base models.
LabUtopia: High-Fidelity Simulation and Hierarchical Benchmark for Scientific Embodied Agents
May 28, 2025



Scientific embodied agents play a crucial role in modern laboratories by automating complex experimental workflows. Compared to typical household environments, laboratory settings impose significantly higher demands on perception of physical-chemical transformations and long-horizon planning, making them an ideal testbed for advancing embodied intelligence. However, its development has been long hampered by the lack of suitable simulator and benchmarks. In this paper, we address this gap by introducing LabUtopia, a comprehensive simulation and benchmarking suite designed to facilitate the development of generalizable, reasoning-capable embodied agents in laboratory settings. Specifically, it integrates i) LabSim, a high-fidelity simulator supporting multi-physics and chemically meaningful interactions; ii) LabScene, a scalable procedural generator for diverse scientific scenes; and iii) LabBench, a hierarchical benchmark spanning five levels of complexity from atomic actions to long-horizon mobile manipulation. LabUtopia supports 30 distinct tasks and includes more than 200 scene and instrument assets, enabling large-scale training and principled evaluation in high-complexity environments. We demonstrate that LabUtopia offers a powerful platform for advancing the integration of perception, planning, and control in scientific-purpose agents and provides a rigorous testbed for exploring the practical capabilities and generalization limits of embodied intelligence in future research.
Multi-Timescale Motion-Decoupled Spiking Transformer for Audio-Visual Zero-Shot Learning
May 26, 2025



Audio-visual zero-shot learning (ZSL) has been extensively researched for its capability to classify video data from unseen classes during training. Nevertheless, current methodologies often struggle with background scene biases and inadequate motion detail. This paper proposes a novel dual-stream Multi-Timescale Motion-Decoupled Spiking Transformer (MDST++), which decouples contextual semantic information and sparse dynamic motion information. The recurrent joint learning unit is proposed to extract contextual semantic information and capture joint knowledge across various modalities to understand the environment of actions. By converting RGB images to events, our method captures motion information more accurately and mitigates background scene biases. Moreover, we introduce a discrepancy analysis block to model audio motion information. To enhance the robustness of SNNs in extracting temporal and motion cues, we dynamically adjust the threshold of Leaky Integrate-and-Fire neurons based on global motion and contextual semantic information. Our experiments validate the effectiveness of MDST++, demonstrating their consistent superiority over state-of-the-art methods on mainstream benchmarks. Additionally, incorporating motion and multi-timescale information significantly improves HM and ZSL accuracy by 26.2\% and 39.9\%.
Point-RFT: Improving Multimodal Reasoning with Visually Grounded Reinforcement Finetuning
May 26, 2025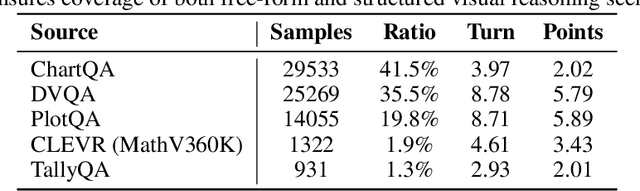
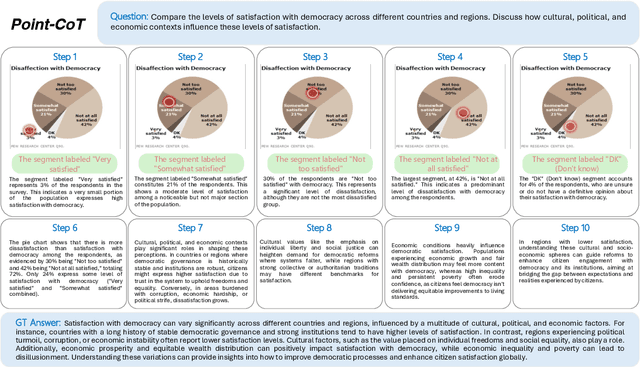

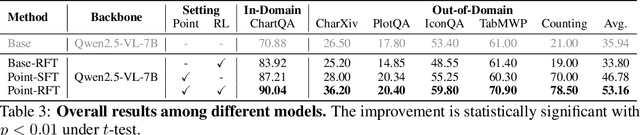
Recent advances in large language models have significantly improved textual reasoning through the effective use of Chain-of-Thought (CoT) and reinforcement learning. However, extending these successes to vision-language tasks remains challenging due to inherent limitations in text-only CoT, such as visual hallucinations and insufficient multimodal integration. In this paper, we introduce Point-RFT, a multimodal reasoning framework explicitly designed to leverage visually grounded CoT reasoning for visual document understanding. Our approach consists of two stages: First, we conduct format finetuning using a curated dataset of 71K diverse visual reasoning problems, each annotated with detailed, step-by-step rationales explicitly grounded to corresponding visual elements. Second, we employ reinforcement finetuning targeting visual document understanding. On ChartQA, our approach improves accuracy from 70.88% (format-finetuned baseline) to 90.04%, surpassing the 83.92% accuracy achieved by reinforcement finetuning relying solely on text-based CoT. The result shows that our grounded CoT is more effective for multimodal reasoning compared with the text-only CoT. Moreover, Point-RFT exhibits superior generalization capability across several out-of-domain visual document reasoning benchmarks, including CharXiv, PlotQA, IconQA, TabMWP, etc., and highlights its potential in complex real-world scenarios.
Decoupled Visual Interpretation and Linguistic Reasoning for Math Problem Solving
May 23, 2025Current large vision-language models (LVLMs) typically employ a connector module to link visual features with text embeddings of large language models (LLMs) and use end-to-end training to achieve multi-modal understanding in a unified process. Well alignment needs high-quality pre-training data and a carefully designed training process. Current LVLMs face challenges when addressing complex vision-language reasoning tasks, with their reasoning capabilities notably lagging behind those of LLMs. This paper proposes a paradigm shift: instead of training end-to-end vision-language reasoning models, we advocate for developing a decoupled reasoning framework based on existing visual interpretation specialists and text-based reasoning LLMs. Our approach leverages (1) a dedicated vision-language model to transform the visual content of images into textual descriptions and (2) an LLM to perform reasoning according to the visual-derived text and the original question. This method presents a cost-efficient solution for multi-modal model development by optimizing existing models to work collaboratively, avoiding end-to-end development of vision-language models from scratch. By transforming images into language model-compatible text representations, it facilitates future low-cost and flexible upgrades to upcoming powerful LLMs. We introduce an outcome-rewarded joint-tuning strategy to optimize the cooperation between the visual interpretation and linguistic reasoning model. Evaluation results on vision-language benchmarks demonstrate that the decoupled reasoning framework outperforms recent LVLMs. Our approach yields particularly significant performance gains on visually intensive geometric mathematics problems. The code is available: https://github.com/guozix/DVLR.