 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMC-InterCPT: Rethinking Biomedical Interleaved Data for Multimodal Continued Pretraining
May 31, 2026Large-scale biomedical image-text datasets extracted from scientific literature provide valuable resources for medical multimodal model training. These datasets are commonly organized as image-caption pairs; however, figure captions are often short, context-dependent, and only partially informative without the surrounding article text. At the same time, large-scale automatic extraction introduces structural noise such as missing captions, residual markup, duplicated context, and incoherent multi-paragraph figure descriptions. We revisit data construction for medical multimodal continued pretraining (CPT) and present PMC-InterCPT, a context-grounded biomedical interleaved corpus that incorporates figure-referencing body text in addition to captions. Our pipeline recovers missing captions, cleans caption and context text, reconstructs coherent interleaved image-text samples, and applies LLM-supervised medical relevance and quality classifiers to filter noisy records. We further reveal strong modality imbalance in the resulting corpus and introduce a four-bucket evidence taxonomy for modality-aware resampling. Through CPT followed by supervised fine-tuning (SFT) on Qwen3.5-4B-Base, PMC-InterCPT effectively improves medical and general multimodal performance while using fewer CPT tokens than the raw source pool. The experimental results also illustrate the complementarity between the data quality and modality for medical multimodal CPT.
ProImage-Bench: Rubric-Based Evaluation for Professional Image Generation
Dec 13, 2025We study professional image generation, where a model must synthesize information-dense, scientifically precise illustrations from technical descriptions rather than merely produce visually plausible pictures. To quantify the progress, we introduce ProImage-Bench, a rubric-based benchmark that targets biology schematics, engineering/patent drawings, and general scientific diagrams. For 654 figures collected from real textbooks and technical reports, we construct detailed image instructions and a hierarchy of rubrics that decompose correctness into 6,076 criteria and 44,131 binary checks. Rubrics are derived from surrounding text and reference figures using large multimodal models, and are evaluated by an automated LMM-based judge with a principled penalty scheme that aggregates sub-question outcomes into interpretable criterion scores. We benchmark several representative text-to-image models on ProImage-Bench and find that, despite strong open-domain performance, the best base model reaches only 0.791 rubric accuracy and 0.553 criterion score overall, revealing substantial gaps in fine-grained scientific fidelity. Finally, we show that the same rubrics provide actionable supervision: feeding failed checks back into an editing model for iterative refinement boosts a strong generator from 0.653 to 0.865 in rubric accuracy and from 0.388 to 0.697 in criterion score. ProImage-Bench thus offers both a rigorous diagnostic for professional image generation and a scalable signal for improving specification-faithful scientific illustrations.
MIRAGE: Assessing Hallucination in Multimodal Reasoning Chains of MLLM
May 30, 2025Multimodal hallucination in multimodal large language models (MLLMs) restricts the correctness of MLLMs. However, multimodal hallucinations are multi-sourced and arise from diverse causes. Existing benchmarks fail to adequately distinguish between perception-induced hallucinations and reasoning-induced hallucinations. This failure constitutes a significant issue and hinders the diagnosis of multimodal reasoning failures within MLLMs. To address this, we propose the {\dataset} benchmark, which isolates reasoning hallucinations by constructing questions where input images are correctly perceived by MLLMs yet reasoning errors persist. {\dataset} introduces multi-granular evaluation metrics: accuracy, factuality, and LLMs hallucination score for hallucination quantification. Our analysis reveals that (1) the model scale, data scale, and training stages significantly affect the degree of logical, fabrication, and factual hallucinations; (2) current MLLMs show no effective improvement on spatial hallucinations caused by misinterpreted spatial relationships, indicating their limited visual reasoning capabilities; and (3) question types correlate with distinct hallucination patterns, highlighting targeted challenges and potential mitigation strategies. To address these challenges, we propose {\method}, a method that combines curriculum reinforcement fine-tuning to encourage models to generate logic-consistent reasoning chains by stepwise reducing learning difficulty, and collaborative hint inference to reduce reasoning complexity. {\method} establishes a baseline on {\dataset}, and reduces the logical hallucinations in original base models.
Point-RFT: Improving Multimodal Reasoning with Visually Grounded Reinforcement Finetuning
May 26, 2025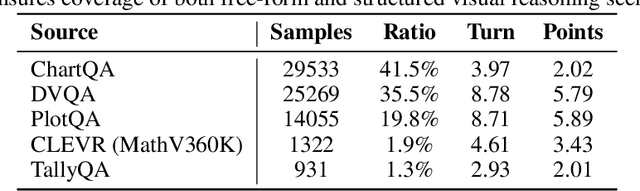
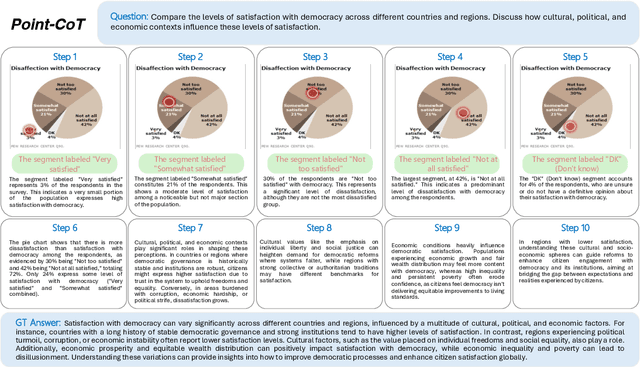

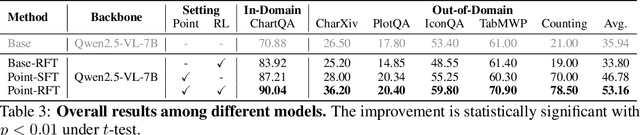
Recent advances in large language models have significantly improved textual reasoning through the effective use of Chain-of-Thought (CoT) and reinforcement learning. However, extending these successes to vision-language tasks remains challenging due to inherent limitations in text-only CoT, such as visual hallucinations and insufficient multimodal integration. In this paper, we introduce Point-RFT, a multimodal reasoning framework explicitly designed to leverage visually grounded CoT reasoning for visual document understanding. Our approach consists of two stages: First, we conduct format finetuning using a curated dataset of 71K diverse visual reasoning problems, each annotated with detailed, step-by-step rationales explicitly grounded to corresponding visual elements. Second, we employ reinforcement finetuning targeting visual document understanding. On ChartQA, our approach improves accuracy from 70.88% (format-finetuned baseline) to 90.04%, surpassing the 83.92% accuracy achieved by reinforcement finetuning relying solely on text-based CoT. The result shows that our grounded CoT is more effective for multimodal reasoning compared with the text-only CoT. Moreover, Point-RFT exhibits superior generalization capability across several out-of-domain visual document reasoning benchmarks, including CharXiv, PlotQA, IconQA, TabMWP, etc., and highlights its potential in complex real-world scenarios.
Measurement of LLM's Philosophies of Human Nature
Apr 03, 2025The widespread application of artificial intelligence (AI) in various tasks, along with frequent reports of conflicts or violations involving AI, has sparked societal concerns about interactions with AI systems. Based on Wrightsman's Philosophies of Human Nature Scale (PHNS), a scale empirically validated over decades to effectively assess individuals' attitudes toward human nature, we design the standardized psychological scale specifically targeting large language models (LLM), named the Machine-based Philosophies of Human Nature Scale (M-PHNS). By evaluating LLMs' attitudes toward human nature across six dimensions, we reveal that current LLMs exhibit a systemic lack of trust in humans, and there is a significant negative correlation between the model's intelligence level and its trust in humans. Furthermore, we propose a mental loop learning framework, which enables LLM to continuously optimize its value system during virtual interactions by constructing moral scenarios, thereby improving its attitude toward human nature. Experiments demonstrate that mental loop learning significantly enhances their trust in humans compared to persona or instruction prompts. This finding highlights the potential of human-based psychological assessments for LLM, which can not only diagnose cognitive biases but also provide a potential solution for ethical learning in artificial intelligence. We release the M-PHNS evaluation code and data at https://github.com/kodenii/M-PHNS.
Don't Let Your Robot be Harmful: Responsible Robotic Manipulation
Nov 27, 2024Unthinking execution of human instructions in robotic manipulation can lead to severe safety risks, such as poisonings, fires, and even explosions. In this paper, we present responsible robotic manipulation, which requires robots to consider potential hazards in the real-world environment while completing instructions and performing complex operations safely and efficiently. However, such scenarios in real world are variable and risky for training. To address this challenge, we propose Safety-as-policy, which includes (i) a world model to automatically generate scenarios containing safety risks and conduct virtual interactions, and (ii) a mental model to infer consequences with reflections and gradually develop the cognition of safety, allowing robots to accomplish tasks while avoiding dangers. Additionally, we create the SafeBox synthetic dataset, which includes one hundred responsible robotic manipulation tasks with different safety risk scenarios and instructions, effectively reducing the risks associated with real-world experiments. Experiments demonstrate that Safety-as-policy can avoid risks and efficiently complete tasks in both synthetic dataset and real-world experiments, significantly outperforming baseline methods. Our SafeBox dataset shows consistent evaluation results with real-world scenarios, serving as a safe and effective benchmark for future research.
Visual-O1: Understanding Ambiguous Instructions via Multi-modal Multi-turn Chain-of-thoughts Reasoning
Oct 04, 2024



As large-scale models evolve, language instructions are increasingly utilized in multi-modal tasks. Due to human language habits, these instructions often contain ambiguities in real-world scenarios, necessitating the integration of visual context or common sense for accurate interpretation. However, even highly intelligent large models exhibit significant performance limitations on ambiguous instructions, where weak reasoning abilities of disambiguation can lead to catastrophic errors. To address this issue, this paper proposes Visual-O1, a multi-modal multi-turn chain-of-thought reasoning framework. It simulates human multi-modal multi-turn reasoning, providing instantial experience for highly intelligent models or empirical experience for generally intelligent models to understand ambiguous instructions. Unlike traditional methods that require models to possess high intelligence to understand long texts or perform lengthy complex reasoning, our framework does not significantly increase computational overhead and is more general and effective, even for generally intelligent models. Experiments show that our method not only significantly enhances the performance of models of different intelligence levels on ambiguous instructions but also improves their performance on general datasets. Our work highlights the potential of artificial intelligence to work like humans in real-world scenarios with uncertainty and ambiguity. We will release our data and code.
AutoDirector: Online Auto-scheduling Agents for Multi-sensory Composition
Aug 21, 2024



With the advancement of generative models, the synthesis of different sensory elements such as music, visuals, and speech has achieved significant realism. However, the approach to generate multi-sensory outputs has not been fully explored, limiting the application on high-value scenarios such as of directing a film. Developing a movie director agent faces two major challenges: (1) Lack of parallelism and online scheduling with production steps: In the production of multi-sensory films, there are complex dependencies between different sensory elements, and the production time for each element varies. (2) Diverse needs and clear communication demands with users: Users often cannot clearly express their needs until they see a draft, which requires human-computer interaction and iteration to continually adjust and optimize the film content based on user feedback. To address these issues, we introduce AutoDirector, an interactive multi-sensory composition framework that supports long shots, special effects, music scoring, dubbing, and lip-syncing. This framework improves the efficiency of multi-sensory film production through automatic scheduling and supports the modification and improvement of interactive tasks to meet user needs. AutoDirector not only expands the application scope of human-machine collaboration but also demonstrates the potential of AI in collaborating with humans in the role of a film director to complete multi-sensory films.
Responsible Visual Editing
Apr 08, 2024



With recent advancements in visual synthesis, there is a growing risk of encountering images with detrimental effects, such as hate, discrimination, or privacy violations. The research on transforming harmful images into responsible ones remains unexplored. In this paper, we formulate a new task, responsible visual editing, which entails modifying specific concepts within an image to render it more responsible while minimizing changes. However, the concept that needs to be edited is often abstract, making it challenging to locate what needs to be modified and plan how to modify it. To tackle these challenges, we propose a Cognitive Editor (CoEditor) that harnesses the large multimodal model through a two-stage cognitive process: (1) a perceptual cognitive process to focus on what needs to be modified and (2) a behavioral cognitive process to strategize how to modify. To mitigate the negative implications of harmful images on research, we create a transparent and public dataset, AltBear, which expresses harmful information using teddy bears instead of humans. Experiments demonstrate that CoEditor can effectively comprehend abstract concepts within complex scenes and significantly surpass the performance of baseline models for responsible visual editing. We find that the AltBear dataset corresponds well to the harmful content found in real images, offering a consistent experimental evaluation, thereby providing a safer benchmark for future research. Moreover, CoEditor also shows great results in general editing. We release our code and dataset at https://github.com/kodenii/Responsible-Visual-Editing.
Ref-Diff: Zero-shot Referring Image Segmentation with Generative Models
Sep 01, 2023Zero-shot referring image segmentation is a challenging task because it aims to find an instance segmentation mask based on the given referring descriptions, without training on this type of paired data. Current zero-shot methods mainly focus on using pre-trained discriminative models (e.g., CLIP). However, we have observed that generative models (e.g., Stable Diffusion) have potentially understood the relationships between various visual elements and text descriptions, which are rarely investigated in this task. In this work, we introduce a novel Referring Diffusional segmentor (Ref-Diff) for this task, which leverages the fine-grained multi-modal information from generative models. We demonstrate that without a proposal generator, a generative model alone can achieve comparable performance to existing SOTA weakly-supervised models. When we combine both generative and discriminative models, our Ref-Diff outperforms these competing methods by a significant margin. This indicates that generative models are also beneficial for this task and can complement discriminative models for better referring segmentation. Our code is publicly available at https://github.com/kodenii/Ref-Diff.