 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProImage-Bench: Rubric-Based Evaluation for Professional Image Generation
Dec 13, 2025We study professional image generation, where a model must synthesize information-dense, scientifically precise illustrations from technical descriptions rather than merely produce visually plausible pictures. To quantify the progress, we introduce ProImage-Bench, a rubric-based benchmark that targets biology schematics, engineering/patent drawings, and general scientific diagrams. For 654 figures collected from real textbooks and technical reports, we construct detailed image instructions and a hierarchy of rubrics that decompose correctness into 6,076 criteria and 44,131 binary checks. Rubrics are derived from surrounding text and reference figures using large multimodal models, and are evaluated by an automated LMM-based judge with a principled penalty scheme that aggregates sub-question outcomes into interpretable criterion scores. We benchmark several representative text-to-image models on ProImage-Bench and find that, despite strong open-domain performance, the best base model reaches only 0.791 rubric accuracy and 0.553 criterion score overall, revealing substantial gaps in fine-grained scientific fidelity. Finally, we show that the same rubrics provide actionable supervision: feeding failed checks back into an editing model for iterative refinement boosts a strong generator from 0.653 to 0.865 in rubric accuracy and from 0.388 to 0.697 in criterion score. ProImage-Bench thus offers both a rigorous diagnostic for professional image generation and a scalable signal for improving specification-faithful scientific illustrations.
SHANKS: Simultaneous Hearing and Thinking for Spoken Language Models
Oct 08, 2025



Current large language models (LLMs) and spoken language models (SLMs) begin thinking and taking actions only after the user has finished their turn. This prevents the model from interacting during the user's turn and can lead to high response latency while it waits to think. Consequently, thinking after receiving the full input is not suitable for speech-to-speech interaction, where real-time, low-latency exchange is important. We address this by noting that humans naturally "think while listening." In this paper, we propose SHANKS, a general inference framework that enables SLMs to generate unspoken chain-of-thought reasoning while listening to the user input. SHANKS streams the input speech in fixed-duration chunks and, as soon as a chunk is received, generates unspoken reasoning based on all previous speech and reasoning, while the user continues speaking. SHANKS uses this unspoken reasoning to decide whether to interrupt the user and to make tool calls to complete the task. We demonstrate that SHANKS enhances real-time user-SLM interaction in two scenarios: (1) when the user is presenting a step-by-step solution to a math problem, SHANKS can listen, reason, and interrupt when the user makes a mistake, achieving 37.1% higher interruption accuracy than a baseline that interrupts without thinking; and (2) in a tool-augmented dialogue, SHANKS can complete 56.9% of the tool calls before the user finishes their turn. Overall, SHANKS moves toward models that keep thinking throughout the conversation, not only after a turn ends. Animated illustrations of Shanks can be found at https://d223302.github.io/SHANKS/
ViCrit: A Verifiable Reinforcement Learning Proxy Task for Visual Perception in VLMs
Jun 11, 2025Reinforcement learning (RL) has shown great effectiveness for fine-tuning large language models (LLMs) using tasks that are challenging yet easily verifiable, such as math reasoning or code generation. However, extending this success to visual perception in vision-language models (VLMs) has been impeded by the scarcity of vision-centric tasks that are simultaneously challenging and unambiguously verifiable. To this end, we introduce ViCrit (Visual Caption Hallucination Critic), an RL proxy task that trains VLMs to localize a subtle, synthetic visual hallucination injected into paragraphs of human-written image captions. Starting from a 200-word captions, we inject a single, subtle visual description error-altering a few words on objects, attributes, counts, or spatial relations-and task the model to pinpoint the corrupted span given the image and the modified caption. This formulation preserves the full perceptual difficulty while providing a binary, exact-match reward that is easy to compute and unambiguous. Models trained with the ViCrit Task exhibit substantial gains across a variety of VL benchmarks. Crucially, the improvements transfer beyond natural-image training data to abstract image reasoning and visual math, showing promises of learning to perceive rather than barely memorizing seen objects. To facilitate evaluation, we further introduce ViCrit-Bench, a category-balanced diagnostic benchmark that systematically probes perception errors across diverse image domains and error types. Together, our results demonstrate that fine-grained hallucination criticism is an effective and generalizable objective for enhancing visual perception in VLMs.
Audio-Aware Large Language Models as Judges for Speaking Styles
Jun 06, 2025Audio-aware large language models (ALLMs) can understand the textual and non-textual information in the audio input. In this paper, we explore using ALLMs as an automatic judge to assess the speaking styles of speeches. We use ALLM judges to evaluate the speeches generated by SLMs on two tasks: voice style instruction following and role-playing. The speaking style we consider includes emotion, volume, speaking pace, word emphasis, pitch control, and non-verbal elements. We use four spoken language models (SLMs) to complete the two tasks and use humans and ALLMs to judge the SLMs' responses. We compare two ALLM judges, GPT-4o-audio and Gemini-2.5-pro, with human evaluation results and show that the agreement between Gemini and human judges is comparable to the agreement between human evaluators. These promising results show that ALLMs can be used as a judge to evaluate SLMs. Our results also reveal that current SLMs, even GPT-4o-audio, still have room for improvement in controlling the speaking style and generating natural dialogues.
Point-RFT: Improving Multimodal Reasoning with Visually Grounded Reinforcement Finetuning
May 26, 2025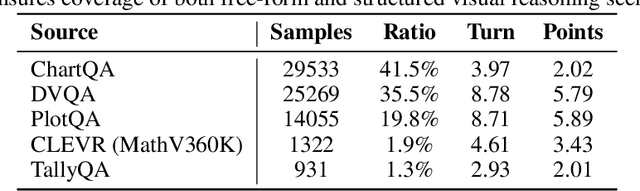
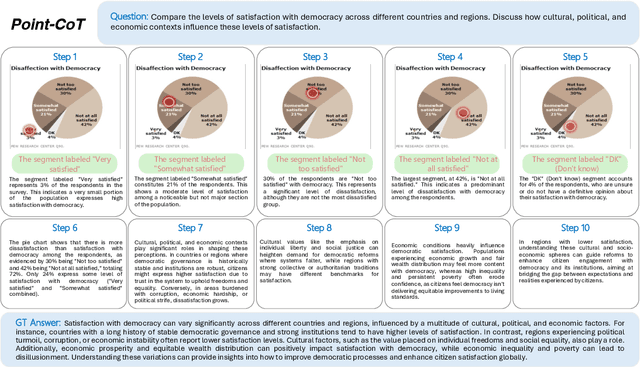

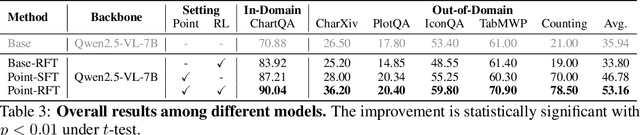
Recent advances in large language models have significantly improved textual reasoning through the effective use of Chain-of-Thought (CoT) and reinforcement learning. However, extending these successes to vision-language tasks remains challenging due to inherent limitations in text-only CoT, such as visual hallucinations and insufficient multimodal integration. In this paper, we introduce Point-RFT, a multimodal reasoning framework explicitly designed to leverage visually grounded CoT reasoning for visual document understanding. Our approach consists of two stages: First, we conduct format finetuning using a curated dataset of 71K diverse visual reasoning problems, each annotated with detailed, step-by-step rationales explicitly grounded to corresponding visual elements. Second, we employ reinforcement finetuning targeting visual document understanding. On ChartQA, our approach improves accuracy from 70.88% (format-finetuned baseline) to 90.04%, surpassing the 83.92% accuracy achieved by reinforcement finetuning relying solely on text-based CoT. The result shows that our grounded CoT is more effective for multimodal reasoning compared with the text-only CoT. Moreover, Point-RFT exhibits superior generalization capability across several out-of-domain visual document reasoning benchmarks, including CharXiv, PlotQA, IconQA, TabMWP, etc., and highlights its potential in complex real-world scenarios.
SoTA with Less: MCTS-Guided Sample Selection for Data-Efficient Visual Reasoning Self-Improvement
Apr 10, 2025



In this paper, we present an effective method to enhance visual reasoning with significantly fewer training samples, relying purely on self-improvement with no knowledge distillation. Our key insight is that the difficulty of training data during reinforcement fine-tuning (RFT) is critical. Appropriately challenging samples can substantially boost reasoning capabilities even when the dataset is small. Despite being intuitive, the main challenge remains in accurately quantifying sample difficulty to enable effective data filtering. To this end, we propose a novel way of repurposing Monte Carlo Tree Search (MCTS) to achieve that. Starting from our curated 70k open-source training samples, we introduce an MCTS-based selection method that quantifies sample difficulty based on the number of iterations required by the VLMs to solve each problem. This explicit step-by-step reasoning in MCTS enforces the model to think longer and better identifies samples that are genuinely challenging. We filter and retain 11k samples to perform RFT on Qwen2.5-VL-7B-Instruct, resulting in our final model, ThinkLite-VL. Evaluation results on eight benchmarks show that ThinkLite-VL improves the average performance of Qwen2.5-VL-7B-Instruct by 7%, using only 11k training samples with no knowledge distillation. This significantly outperforms all existing 7B-level reasoning VLMs, and our fairly comparable baselines that use classic selection methods such as accuracy-based filtering. Notably, on MathVista, ThinkLite-VL-7B achieves the SoTA accuracy of 75.1, surpassing Qwen2.5-VL-72B, GPT-4o, and O1. Our code, data, and model are available at https://github.com/si0wang/ThinkLite-VL.
Measurement of LLM's Philosophies of Human Nature
Apr 03, 2025The widespread application of artificial intelligence (AI) in various tasks, along with frequent reports of conflicts or violations involving AI, has sparked societal concerns about interactions with AI systems. Based on Wrightsman's Philosophies of Human Nature Scale (PHNS), a scale empirically validated over decades to effectively assess individuals' attitudes toward human nature, we design the standardized psychological scale specifically targeting large language models (LLM), named the Machine-based Philosophies of Human Nature Scale (M-PHNS). By evaluating LLMs' attitudes toward human nature across six dimensions, we reveal that current LLMs exhibit a systemic lack of trust in humans, and there is a significant negative correlation between the model's intelligence level and its trust in humans. Furthermore, we propose a mental loop learning framework, which enables LLM to continuously optimize its value system during virtual interactions by constructing moral scenarios, thereby improving its attitude toward human nature. Experiments demonstrate that mental loop learning significantly enhances their trust in humans compared to persona or instruction prompts. This finding highlights the potential of human-based psychological assessments for LLM, which can not only diagnose cognitive biases but also provide a potential solution for ethical learning in artificial intelligence. We release the M-PHNS evaluation code and data at https://github.com/kodenii/M-PHNS.
Zero-Shot Audio-Visual Editing via Cross-Modal Delta Denoising
Mar 26, 2025



In this paper, we introduce zero-shot audio-video editing, a novel task that requires transforming original audio-visual content to align with a specified textual prompt without additional model training. To evaluate this task, we curate a benchmark dataset, AvED-Bench, designed explicitly for zero-shot audio-video editing. AvED-Bench includes 110 videos, each with a 10-second duration, spanning 11 categories from VGGSound. It offers diverse prompts and scenarios that require precise alignment between auditory and visual elements, enabling robust evaluation. We identify limitations in existing zero-shot audio and video editing methods, particularly in synchronization and coherence between modalities, which often result in inconsistent outcomes. To address these challenges, we propose AvED, a zero-shot cross-modal delta denoising framework that leverages audio-video interactions to achieve synchronized and coherent edits. AvED demonstrates superior results on both AvED-Bench and the recent OAVE dataset to validate its generalization capabilities. Results are available at https://genjib.github.io/project_page/AVED/index.html
GenXD: Generating Any 3D and 4D Scenes
Nov 05, 2024



Recent developments in 2D visual generation have been remarkably successful. However, 3D and 4D generation remain challenging in real-world applications due to the lack of large-scale 4D data and effective model design. In this paper, we propose to jointly investigate general 3D and 4D generation by leveraging camera and object movements commonly observed in daily life. Due to the lack of real-world 4D data in the community, we first propose a data curation pipeline to obtain camera poses and object motion strength from videos. Based on this pipeline, we introduce a large-scale real-world 4D scene dataset: CamVid-30K. By leveraging all the 3D and 4D data, we develop our framework, GenXD, which allows us to produce any 3D or 4D scene. We propose multiview-temporal modules, which disentangle camera and object movements, to seamlessly learn from both 3D and 4D data. Additionally, GenXD employs masked latent conditions to support a variety of conditioning views. GenXD can generate videos that follow the camera trajectory as well as consistent 3D views that can be lifted into 3D representations. We perform extensive evaluations across various real-world and synthetic datasets, demonstrating GenXD's effectiveness and versatility compared to previous methods in 3D and 4D generation.
SlowFast-VGen: Slow-Fast Learning for Action-Driven Long Video Generation
Oct 30, 2024



Human beings are endowed with a complementary learning system, which bridges the slow learning of general world dynamics with fast storage of episodic memory from a new experience. Previous video generation models, however, primarily focus on slow learning by pre-training on vast amounts of data, overlooking the fast learning phase crucial for episodic memory storage. This oversight leads to inconsistencies across temporally distant frames when generating longer videos, as these frames fall beyond the model's context window. To this end, we introduce SlowFast-VGen, a novel dual-speed learning system for action-driven long video generation. Our approach incorporates a masked conditional video diffusion model for the slow learning of world dynamics, alongside an inference-time fast learning strategy based on a temporal LoRA module. Specifically, the fast learning process updates its temporal LoRA parameters based on local inputs and outputs, thereby efficiently storing episodic memory in its parameters. We further propose a slow-fast learning loop algorithm that seamlessly integrates the inner fast learning loop into the outer slow learning loop, enabling the recall of prior multi-episode experiences for context-aware skill learning. To facilitate the slow learning of an approximate world model, we collect a large-scale dataset of 200k videos with language action annotations, covering a wide range of scenarios. Extensive experiments show that SlowFast-VGen outperforms baselines across various metrics for action-driven video generation, achieving an FVD score of 514 compared to 782, and maintaining consistency in longer videos, with an average of 0.37 scene cuts versus 0.89. The slow-fast learning loop algorithm significantly enhances performances on long-horizon planning tasks as well. Project Website: https://slowfast-vgen.github.io