 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrans2Occ: Voxel Occupancy Estimation and Grasp for Transparent Objects from Simulation to Reality
Jun 01, 2026Transparent objects remain challenging for robotic perception due to unreliable depth sensing caused by refraction and reflection. While prior approaches rely on multi-view reconstruction or depth completion, they are often difficult to scale or deploy in real-world robotic systems. In this paper, we present a practical framework for transparent object perception and manipulation based on single-view RGB input. Our approach predicts voxel-space occupancy directly from a single image, providing a geometry-aware representation that supports downstream robotic grasping. To enable large-scale training, we construct a simulation pipeline that generates paired RGB images and voxel occupancy annotations under diverse materials and lighting conditions. We demonstrate that the predicted occupancy representation is robust to domain shifts and transfers effectively from simulation to real-world robotic setups without fine-tuning. A simple rule-based grasping strategy built on top of the occupancy further achieves reliable grasp performance on transparent objects. Extensive experiments in both simulation and real-world environments show that our framework provides accurate 3D understanding and enables practical manipulation of transparent objects. These results suggest that single-view occupancy prediction offers a scalable and effective solution for transparent object perception in robotics.
LabBuilder: Protocol-Grounded 3D Layout Generation for Interactable and Safe Laboratory
May 04, 2026Automated laboratories hold the promise of accelerating scientific discovery, yet their deployment is bottlenecked by the difficulty of designing safe and executable environments. While simulator-based design offers scalability, existing 3D scene generation methods are primarily tailored for household settings, optimizing for visual plausibility while neglecting the rigorous functional semantics and safety constraints essential for scientific experimentation. We present LabBuilder, an end-to-end system that generates and verifies 3D laboratory layouts from concise textual specifications. It operates through three tightly coupled components: LabForge first curates a meta-dataset of annotated assets and chemical knowledge, translating natural language specifications into structured protocols; building on these protocols, LabGen synthesizes laboratory layouts via an iterative, constraint-aware optimization strategy; finally, LabTouchstone evaluates the resulting layouts as a unified benchmark. Extensive experiments demonstrate that LabBuilder significantly outperforms existing state-of-the-art methods, producing laboratory environments that are not only realistic but also functionally valid and safe for complex experimental workflows.
GA-GS: Generation-Assisted Gaussian Splatting for Static Scene Reconstruction
Apr 06, 2026Reconstructing static 3D scene from monocular video with dynamic objects is important for numerous applications such as virtual reality and autonomous driving. Current approaches typically rely on background for static scene reconstruction, limiting the ability to recover regions occluded by dynamic objects. In this paper, we propose GA-GS, a Generation-Assisted Gaussian Splatting method for Static Scene Reconstruction. The key innovation of our work lies in leveraging generation to assist in reconstructing occluded regions. We employ a motion-aware module to segment and remove dynamic regions, and thenuse a diffusion model to inpaint the occluded areas, providing pseudo-ground-truth supervision. To balance contributions from real background and generated region, we introduce a learnable authenticity scalar for each Gaussian primitive, which dynamically modulates opacity during splatting for authenticity-aware rendering and supervision. Since no existing dataset provides ground-truth static scene of video with dynamic objects, we construct a dataset named Trajectory-Match, using a fixed-path robot to record each scene with/without dynamic objects, enabling quantitative evaluation in reconstruction of occluded regions. Extensive experiments on both the DAVIS and our dataset show that GA-GS achieves state-of-the-art performance in static scene reconstruction, especially in challenging scenarios with large-scale, persistent occlusions.
VLMPlanner: Integrating Visual Language Models with Motion Planning
Jul 27, 2025Integrating large language models (LLMs) into autonomous driving motion planning has recently emerged as a promising direction, offering enhanced interpretability, better controllability, and improved generalization in rare and long-tail scenarios. However, existing methods often rely on abstracted perception or map-based inputs, missing crucial visual context, such as fine-grained road cues, accident aftermath, or unexpected obstacles, which are essential for robust decision-making in complex driving environments. To bridge this gap, we propose VLMPlanner, a hybrid framework that combines a learning-based real-time planner with a vision-language model (VLM) capable of reasoning over raw images. The VLM processes multi-view images to capture rich, detailed visual information and leverages its common-sense reasoning capabilities to guide the real-time planner in generating robust and safe trajectories. Furthermore, we develop the Context-Adaptive Inference Gate (CAI-Gate) mechanism that enables the VLM to mimic human driving behavior by dynamically adjusting its inference frequency based on scene complexity, thereby achieving an optimal balance between planning performance and computational efficiency. We evaluate our approach on the large-scale, challenging nuPlan benchmark, with comprehensive experimental results demonstrating superior planning performance in scenarios with intricate road conditions and dynamic elements. Code will be available.
Position: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025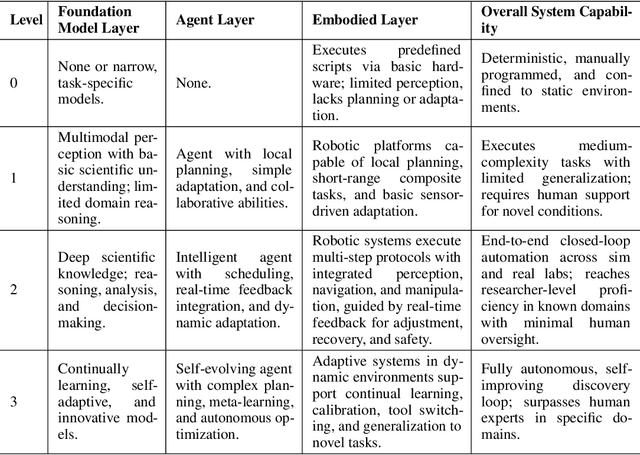
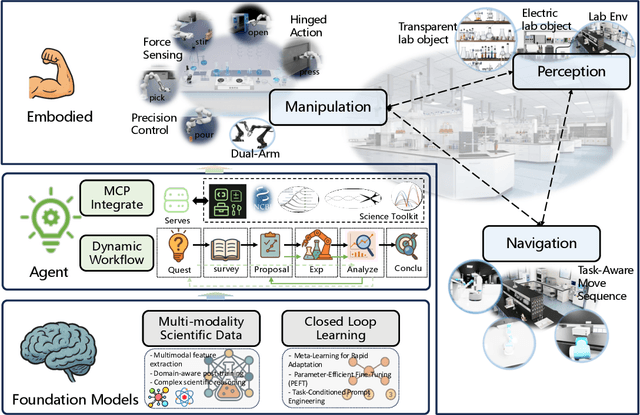
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.
LabUtopia: High-Fidelity Simulation and Hierarchical Benchmark for Scientific Embodied Agents
May 28, 2025



Scientific embodied agents play a crucial role in modern laboratories by automating complex experimental workflows. Compared to typical household environments, laboratory settings impose significantly higher demands on perception of physical-chemical transformations and long-horizon planning, making them an ideal testbed for advancing embodied intelligence. However, its development has been long hampered by the lack of suitable simulator and benchmarks. In this paper, we address this gap by introducing LabUtopia, a comprehensive simulation and benchmarking suite designed to facilitate the development of generalizable, reasoning-capable embodied agents in laboratory settings. Specifically, it integrates i) LabSim, a high-fidelity simulator supporting multi-physics and chemically meaningful interactions; ii) LabScene, a scalable procedural generator for diverse scientific scenes; and iii) LabBench, a hierarchical benchmark spanning five levels of complexity from atomic actions to long-horizon mobile manipulation. LabUtopia supports 30 distinct tasks and includes more than 200 scene and instrument assets, enabling large-scale training and principled evaluation in high-complexity environments. We demonstrate that LabUtopia offers a powerful platform for advancing the integration of perception, planning, and control in scientific-purpose agents and provides a rigorous testbed for exploring the practical capabilities and generalization limits of embodied intelligence in future research.
Self-Supervised Pre-training with Combined Datasets for 3D Perception in Autonomous Driving
Apr 17, 2025



The significant achievements of pre-trained models leveraging large volumes of data in the field of NLP and 2D vision inspire us to explore the potential of extensive data pre-training for 3D perception in autonomous driving. Toward this goal, this paper proposes to utilize massive unlabeled data from heterogeneous datasets to pre-train 3D perception models. We introduce a self-supervised pre-training framework that learns effective 3D representations from scratch on unlabeled data, combined with a prompt adapter based domain adaptation strategy to reduce dataset bias. The approach significantly improves model performance on downstream tasks such as 3D object detection, BEV segmentation, 3D object tracking, and occupancy prediction, and shows steady performance increase as the training data volume scales up, demonstrating the potential of continually benefit 3D perception models for autonomous driving. We will release the source code to inspire further investigations in the community.
LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion
Sep 21, 2024



Multi-modal systems enhance performance in autonomous driving but face inefficiencies due to indiscriminate processing within each modality. Additionally, the independent feature learning of each modality lacks interaction, which results in extracted features that do not possess the complementary characteristics. These issue increases the cost of fusing redundant information across modalities. To address these challenges, we propose targeting driving-relevant elements, which reduces the volume of LiDAR features while preserving critical information. This approach enhances lane level interaction between the image and LiDAR branches, allowing for the extraction and fusion of their respective advantageous features. Building upon the camera-only framework PHP, we introduce the Lane-level camera-LiDAR Fusion Planning (LFP) method, which balances efficiency with performance by using lanes as the unit for sensor fusion. Specifically, we design three modules to enhance efficiency and performance. For efficiency, we propose an image-guided coarse lane prior generation module that forecasts the region of interest (ROI) for lanes and assigns a confidence score, guiding LiDAR processing. The LiDAR feature extraction modules leverages lane-aware priors from the image branch to guide sampling for pillar, retaining essential pillars. For performance, the lane-level cross-modal query integration and feature enhancement module uses confidence score from ROI to combine low-confidence image queries with LiDAR queries, extracting complementary depth features. These features enhance the low-confidence image features, compensating for the lack of depth. Experiments on the Carla benchmarks show that our method achieves state-of-the-art performance in both driving score and infraction score, with maximum improvement of 15% and 14% over existing algorithms, respectively, maintaining high frame rate of 19.27 FPS.
Perception Helps Planning: Facilitating Multi-Stage Lane-Level Integration via Double-Edge Structures
Jul 16, 2024



When planning for autonomous driving, it is crucial to consider essential traffic elements such as lanes, intersections, traffic regulations, and dynamic agents. However, they are often overlooked by the traditional end-to-end planning methods, likely leading to inefficiencies and non-compliance with traffic regulations. In this work, we endeavor to integrate the perception of these elements into the planning task. To this end, we propose Perception Helps Planning (PHP), a novel framework that reconciles lane-level planning with perception. This integration ensures that planning is inherently aligned with traffic constraints, thus facilitating safe and efficient driving. Specifically, PHP focuses on both edges of a lane for planning and perception purposes, taking into consideration the 3D positions of both lane edges and attributes for lane intersections, lane directions, lane occupancy, and planning. In the algorithmic design, the process begins with the transformer encoding multi-camera images to extract the above features and predicting lane-level perception results. Next, the hierarchical feature early fusion module refines the features for predicting planning attributes. Finally, the double-edge interpreter utilizes a late-fusion process specifically designed to integrate lane-level perception and planning information, culminating in the generation of vehicle control signals. Experiments on three Carla benchmarks show significant improvements in driving score of 27.20%, 33.47%, and 15.54% over existing algorithms, respectively, achieving the state-of-the-art performance, with the system operating up to 22.57 FPS.
HVDistill: Transferring Knowledge from Images to Point Clouds via Unsupervised Hybrid-View Distillation
Mar 18, 2024We present a hybrid-view-based knowledge distillation framework, termed HVDistill, to guide the feature learning of a point cloud neural network with a pre-trained image network in an unsupervised manner. By exploiting the geometric relationship between RGB cameras and LiDAR sensors, the correspondence between the two modalities based on both image-plane view and bird-eye view can be established, which facilitates representation learning. Specifically, the image-plane correspondences can be simply obtained by projecting the point clouds, while the bird-eye-view correspondences can be achieved by lifting pixels to the 3D space with the predicted depths under the supervision of projected point clouds. The image teacher networks provide rich semantics from the image-plane view and meanwhile acquire geometric information from the bird-eye view. Indeed, image features from the two views naturally complement each other and together can ameliorate the learned feature representation of the point cloud student networks. Moreover, with a self-supervised pre-trained 2D network, HVDistill requires neither 2D nor 3D annotations. We pre-train our model on nuScenes dataset and transfer it to several downstream tasks on nuScenes, SemanticKITTI, and KITTI datasets for evaluation. Extensive experimental results show that our method achieves consistent improvements over the baseline trained from scratch and significantly outperforms the existing schemes. Codes are available at git@github.com:zhangsha1024/HVDistill.git.