 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicalFactChecker: Leveraging Logical Operations for Fact Checking with Graph Module Network
Apr 28, 2020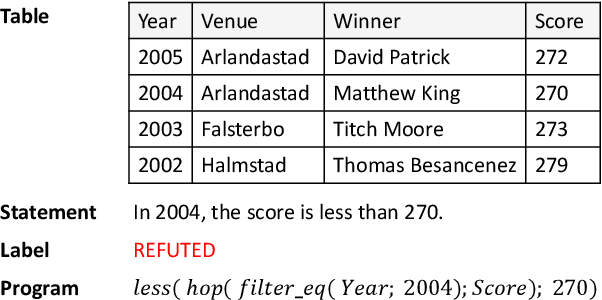
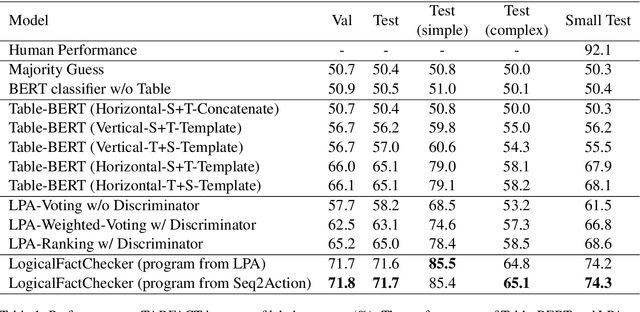
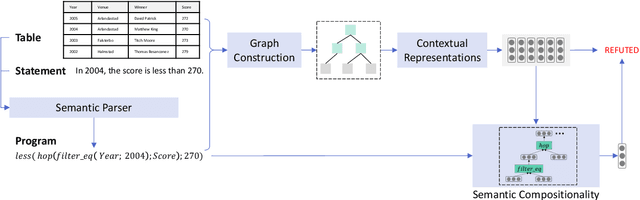
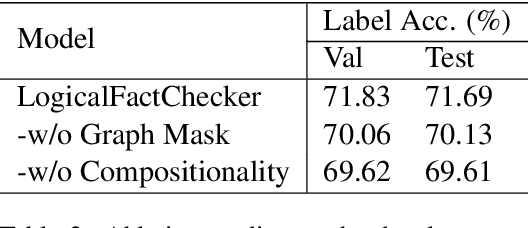
Verifying the correctness of a textual statement requires not only semantic reasoning about the meaning of words, but also symbolic reasoning about logical operations like count, superlative, aggregation, etc. In this work, we propose LogicalFactChecker, a neural network approach capable of leveraging logical operations for fact checking. It achieves the state-of-the-art performance on TABFACT, a large-scale, benchmark dataset built for verifying a textual statement with semi-structured tables. This is achieved by a graph module network built upon the Transformer-based architecture. With a textual statement and a table as the input, LogicalFactChecker automatically derives a program (a.k.a. logical form) of the statement in a semantic parsing manner. A heterogeneous graph is then constructed to capture not only the structures of the table and the program, but also the connections between inputs with different modalities. Such a graph reveals the related contexts of each word in the statement, the table and the program. The graph is used to obtain graph-enhanced contextual representations of words in Transformer-based architecture. After that, a program-driven module network is further introduced to exploit the hierarchical structure of the program, where semantic compositionality is dynamically modeled along the program structure with a set of function-specific modules. Ablation experiments suggest that both the heterogeneous graph and the module network are important to obtain strong results.
Scheduled DropHead: A Regularization Method for Transformer Models
Apr 28, 2020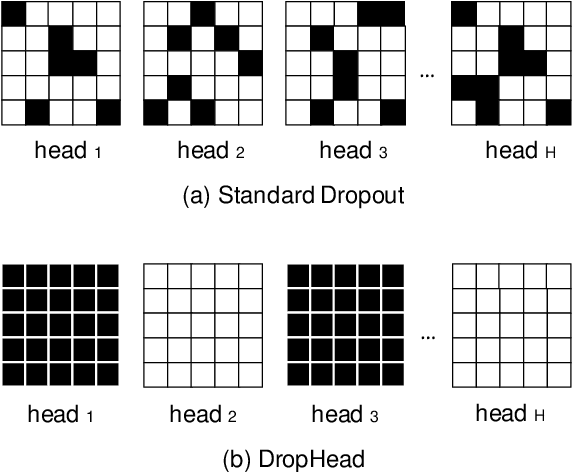
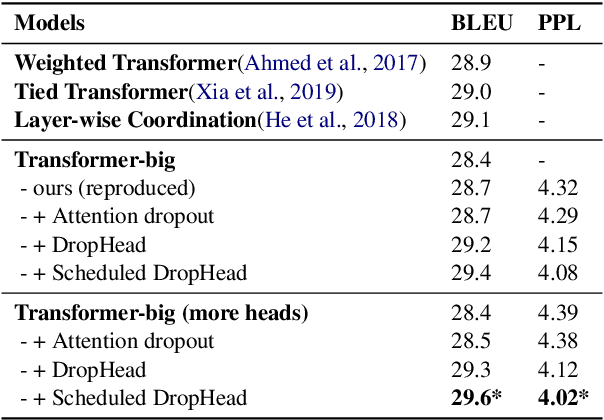
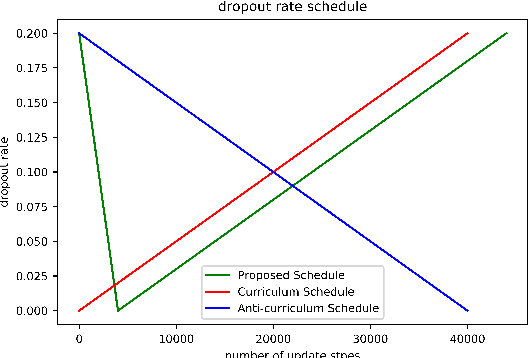
In this paper, we introduce DropHead, a structured dropout method specifically designed for regularizing the multi-head attention mechanism, which is a key component of transformer, a state-of-the-art model for various NLP tasks. In contrast to the conventional dropout mechanisms which randomly drop units or connections, the proposed DropHead is a structured dropout method. It drops entire attention-heads during training and It prevents the multi-head attention model from being dominated by a small portion of attention heads while also reduces the risk of overfitting the training data, thus making use of the multi-head attention mechanism more efficiently. Motivated by recent studies about the learning dynamic of the multi-head attention mechanism, we propose a specific dropout rate schedule to adaptively adjust the dropout rate of DropHead and achieve better regularization effect. Experimental results on both machine translation and text classification benchmark datasets demonstrate the effectiveness of the proposed approach.
A Heterogeneous Graph with Factual, Temporal and Logical Knowledge for Question Answering Over Dynamic Contexts
Apr 25, 2020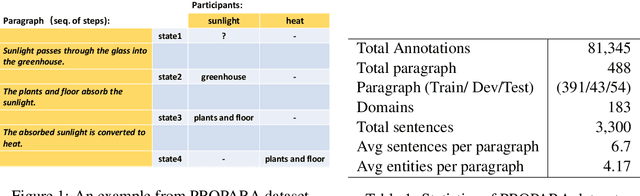
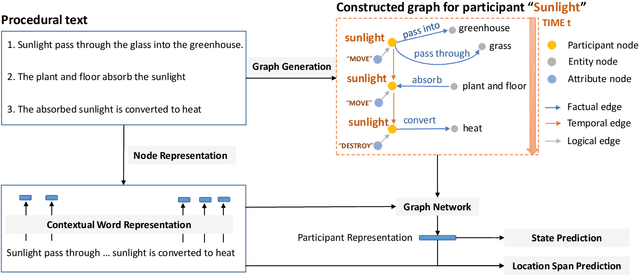
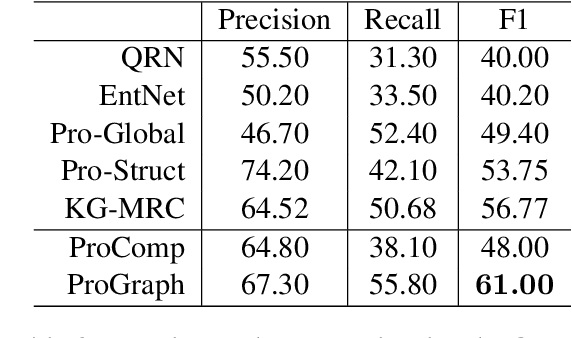
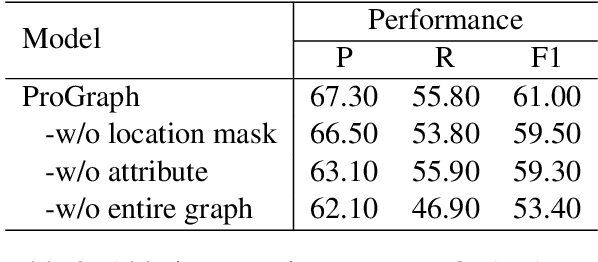
We study question answering over a dynamic textual environment. Although neural network models achieve impressive accuracy via learning from input-output examples, they rarely leverage various types of knowledge and are generally not interpretable. In this work, we propose a graph-based approach, where a heterogeneous graph is automatically built with factual knowledge of the context, temporal knowledge of the past states, and logical knowledge that combines human-curated knowledge bases and rule bases. We develop a graph neural network over the constructed graph, and train the model in an end-to-end manner. Experimental results on a benchmark dataset show that the injection of various types of knowledge improves a strong neural network baseline. An additional benefit of our approach is that the graph itself naturally serves as a rational behind the decision making.
Curriculum Pre-training for End-to-End Speech Translation
Apr 21, 2020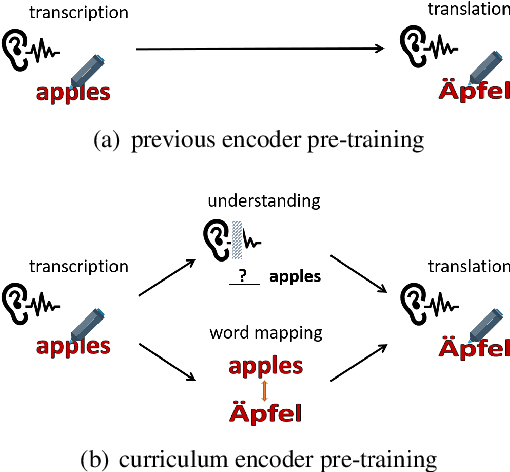
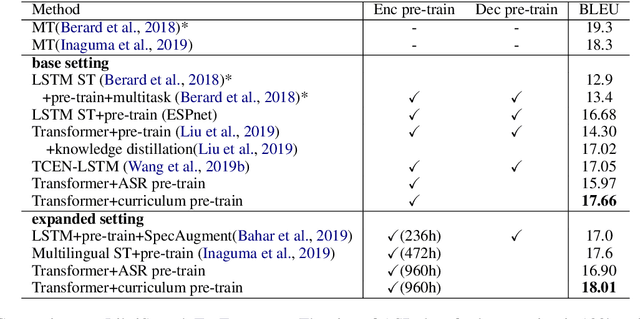
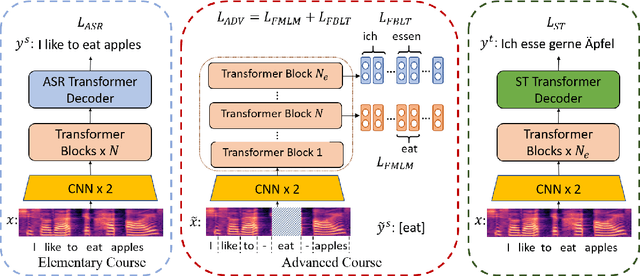
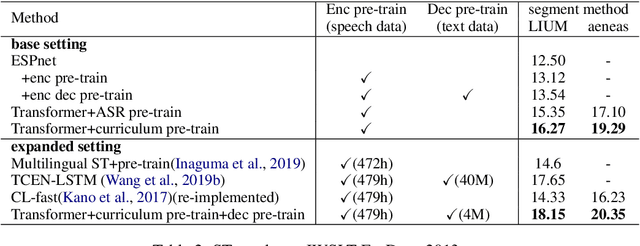
End-to-end speech translation poses a heavy burden on the encoder, because it has to transcribe, understand, and learn cross-lingual semantics simultaneously. To obtain a powerful encoder, traditional methods pre-train it on ASR data to capture speech features. However, we argue that pre-training the encoder only through simple speech recognition is not enough and high-level linguistic knowledge should be considered. Inspired by this, we propose a curriculum pre-training method that includes an elementary course for transcription learning and two advanced courses for understanding the utterance and mapping words in two languages. The difficulty of these courses is gradually increasing. Experiments show that our curriculum pre-training method leads to significant improvements on En-De and En-Fr speech translation benchmarks.
XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020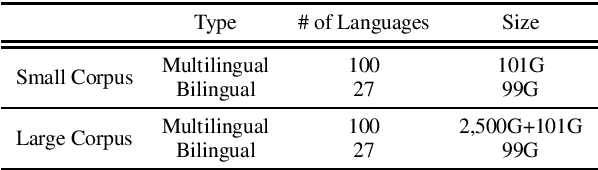
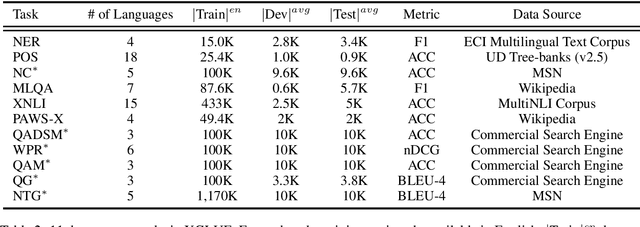
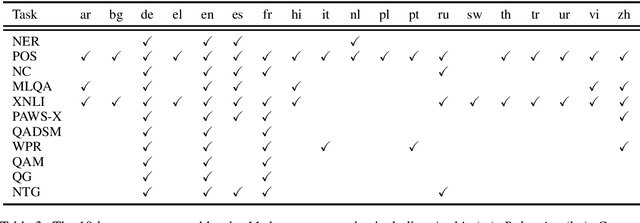
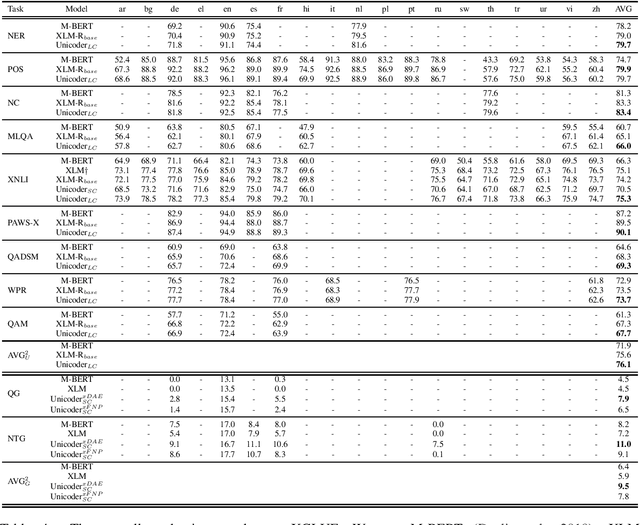
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.
Inferential Text Generation with Multiple Knowledge Sources and Meta-Learning
Apr 15, 2020
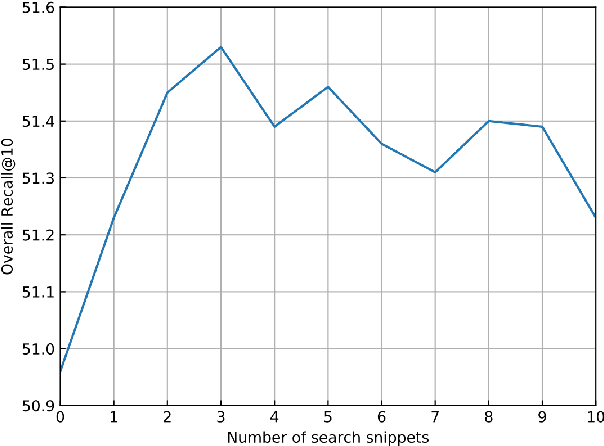
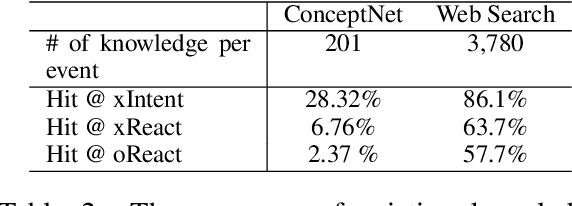
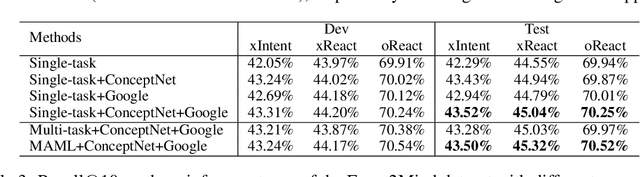
We study the problem of generating inferential texts of events for a variety of commonsense like \textit{if-else} relations. Existing approaches typically use limited evidence from training examples and learn for each relation individually. In this work, we use multiple knowledge sources as fuels for the model. Existing commonsense knowledge bases like ConceptNet are dominated by taxonomic knowledge (e.g., \textit{isA} and \textit{relatedTo} relations), having a limited number of inferential knowledge. We use not only structured commonsense knowledge bases, but also natural language snippets from search-engine results. These sources are incorporated into a generative base model via key-value memory network. In addition, we introduce a meta-learning based multi-task learning algorithm. For each targeted commonsense relation, we regard the learning of examples from other relations as the meta-training process, and the evaluation on examples from the targeted relation as the meta-test process. We conduct experiments on Event2Mind and ATOMIC datasets. Results show that both the integration of multiple knowledge sources and the use of the meta-learning algorithm improve the performance.
Pre-training Text Representations as Meta Learning
Apr 12, 2020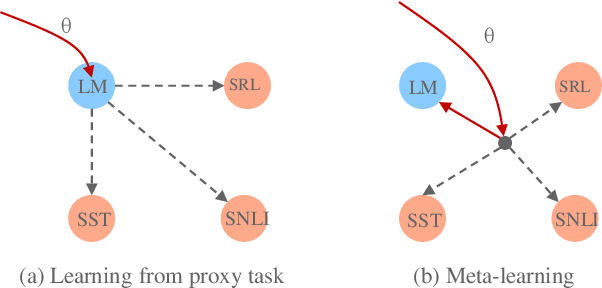
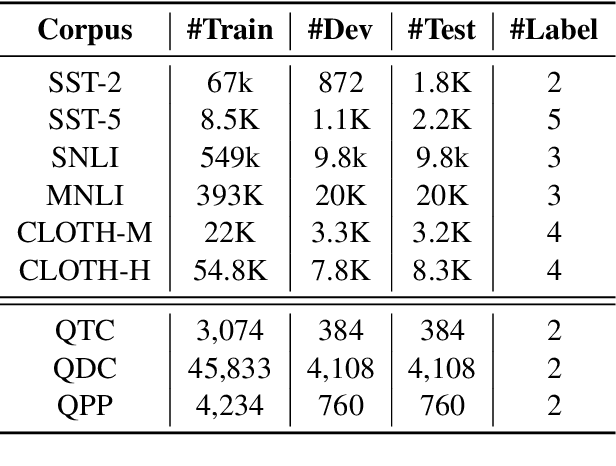
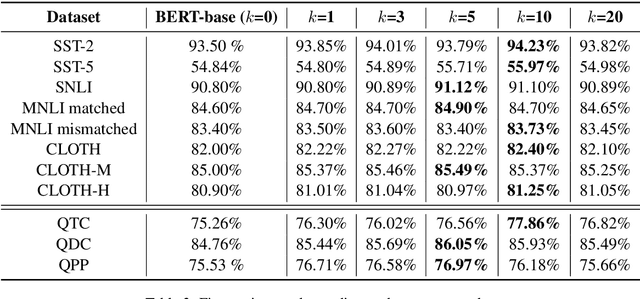
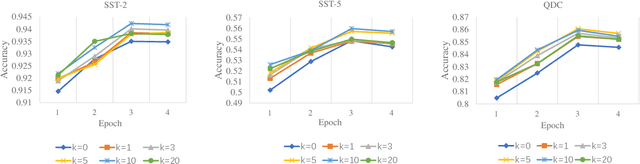
Pre-training text representations has recently been shown to significantly improve the state-of-the-art in many natural language processing tasks. The central goal of pre-training is to learn text representations that are useful for subsequent tasks. However, existing approaches are optimized by minimizing a proxy objective, such as the negative log likelihood of language modeling. In this work, we introduce a learning algorithm which directly optimizes model's ability to learn text representations for effective learning of downstream tasks. We show that there is an intrinsic connection between multi-task pre-training and model-agnostic meta-learning with a sequence of meta-train steps. The standard multi-task learning objective adopted in BERT is a special case of our learning algorithm where the depth of meta-train is zero. We study the problem in two settings: unsupervised pre-training and supervised pre-training with different pre-training objects to verify the generality of our approach.Experimental results show that our algorithm brings improvements and learns better initializations for a variety of downstream tasks.
MuTual: A Dataset for Multi-Turn Dialogue Reasoning
Apr 09, 2020
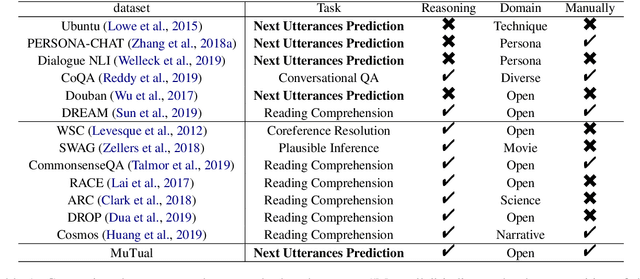
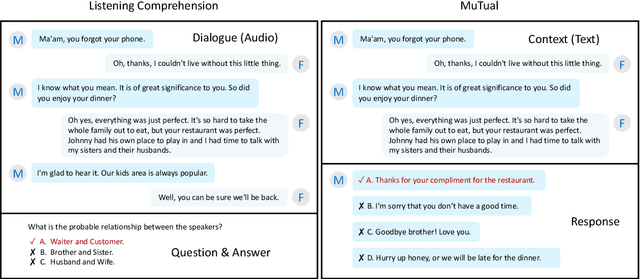
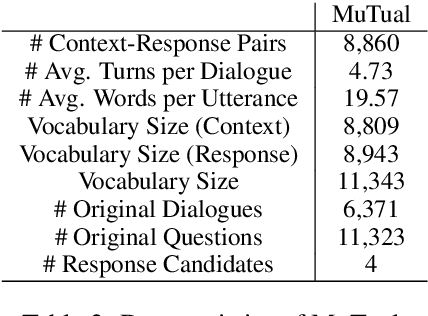
Non-task oriented dialogue systems have achieved great success in recent years due to largely accessible conversation data and the development of deep learning techniques. Given a context, current systems are able to yield a relevant and fluent response, but sometimes make logical mistakes because of weak reasoning capabilities. To facilitate the conversation reasoning research, we introduce MuTual, a novel dataset for Multi-Turn dialogue Reasoning, consisting of 8,860 manually annotated dialogues based on Chinese student English listening comprehension exams. Compared to previous benchmarks for non-task oriented dialogue systems, MuTual is much more challenging since it requires a model that can handle various reasoning problems. Empirical results show that state-of-the-art methods only reach 71%, which is far behind the human performance of 94%, indicating that there is ample room for improving reasoning ability. MuTual is available at https://github.com/Nealcly/MuTual.
At Which Level Should We Extract? An Empirical Study on Extractive Document Summarization
Apr 06, 2020
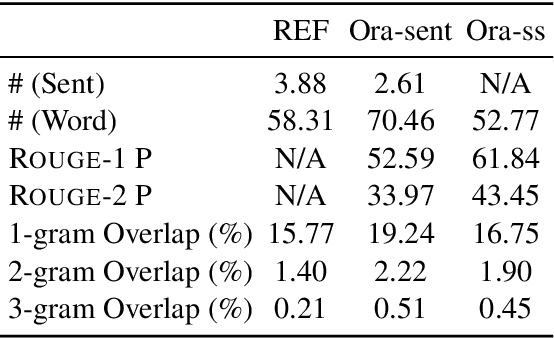
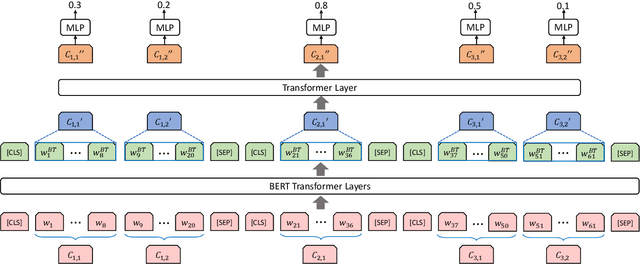
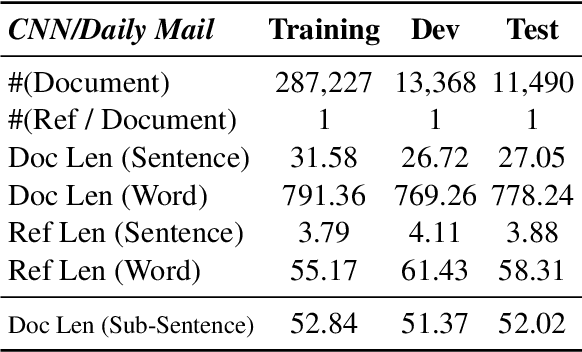
Extractive methods have proven to be very effective in automatic document summarization. Previous works perform this task by identifying informative contents at sentence level. However, it is unclear whether performing extraction at sentence level is the best solution. In this work, we show that unnecessity and redundancy issues exist when extracting full sentences, and extracting sub-sentential units is a promising alternative. Specifically, we propose extracting sub-sentential units on the corresponding constituency parsing tree. A neural extractive model which leverages the sub-sentential information and extracts them is presented. Extensive experiments and analyses show that extracting sub-sentential units performs competitively comparing to full sentence extraction under the evaluation of both automatic and human evaluations. Hopefully, our work could provide some inspiration of the basic extraction units in extractive summarization for future research.
Learning to Summarize Passages: Mining Passage-Summary Pairs from Wikipedia Revision Histories
Apr 06, 2020
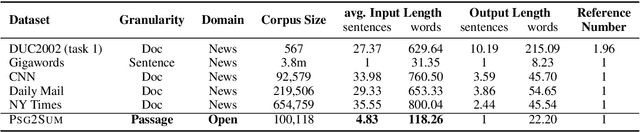
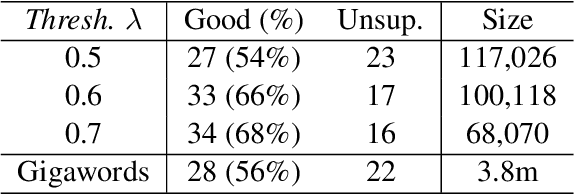
In this paper, we propose a method for automatically constructing a passage-to-summary dataset by mining the Wikipedia page revision histories. In particular, the method mines the main body passages and the introduction sentences which are added to the pages simultaneously. The constructed dataset contains more than one hundred thousand passage-summary pairs. The quality analysis shows that it is promising that the dataset can be used as a training and validation set for passage summarization. We validate and analyze the performance of various summarization systems on the proposed dataset. The dataset will be available online at https://res.qyzhou.me.