 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
VibeVoice Technical Report
Aug 26, 2025This report presents VibeVoice, a novel model designed to synthesize long-form speech with multiple speakers by employing next-token diffusion, which is a unified method for modeling continuous data by autoregressively generating latent vectors via diffusion. To enable this, we introduce a novel continuous speech tokenizer that, when compared to the popular Encodec model, improves data compression by 80 times while maintaining comparable performance. The tokenizer effectively preserves audio fidelity while significantly boosting computational efficiency for processing long sequences. Thus, VibeVoice can synthesize long-form speech for up to 90 minutes (in a 64K context window length) with a maximum of 4 speakers, capturing the authentic conversational ``vibe'' and surpassing open-source and proprietary dialogue models.
Multimodal Latent Language Modeling with Next-Token Diffusion
Dec 11, 2024



Multimodal generative models require a unified approach to handle both discrete data (e.g., text and code) and continuous data (e.g., image, audio, video). In this work, we propose Latent Language Modeling (LatentLM), which seamlessly integrates continuous and discrete data using causal Transformers. Specifically, we employ a variational autoencoder (VAE) to represent continuous data as latent vectors and introduce next-token diffusion for autoregressive generation of these vectors. Additionally, we develop $\sigma$-VAE to address the challenges of variance collapse, which is crucial for autoregressive modeling. Extensive experiments demonstrate the effectiveness of LatentLM across various modalities. In image generation, LatentLM surpasses Diffusion Transformers in both performance and scalability. When integrated into multimodal large language models, LatentLM provides a general-purpose interface that unifies multimodal generation and understanding. Experimental results show that LatentLM achieves favorable performance compared to Transfusion and vector quantized models in the setting of scaling up training tokens. In text-to-speech synthesis, LatentLM outperforms the state-of-the-art VALL-E 2 model in speaker similarity and robustness, while requiring 10x fewer decoding steps. The results establish LatentLM as a highly effective and scalable approach to advance large multimodal models.
A Unified View of Masked Image Modeling
Oct 19, 2022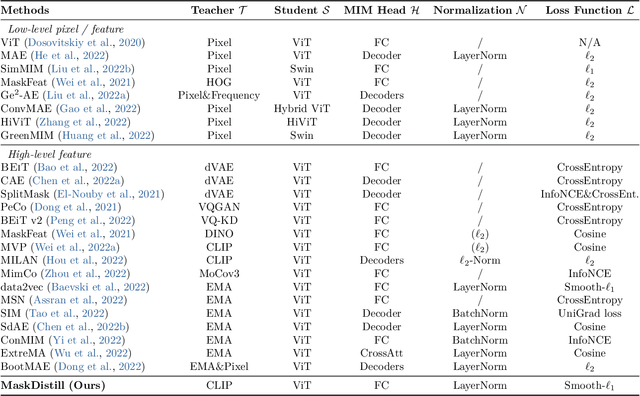
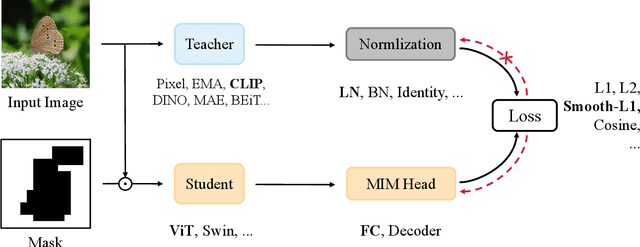


Masked image modeling has demonstrated great potential to eliminate the label-hungry problem of training large-scale vision Transformers, achieving impressive performance on various downstream tasks. In this work, we propose a unified view of masked image modeling after revisiting existing methods. Under the unified view, we introduce a simple yet effective method, termed as MaskDistill, which reconstructs normalized semantic features from teacher models at the masked positions, conditioning on corrupted input images. Experimental results on image classification and semantic segmentation show that MaskDistill achieves comparable or superior performance than state-of-the-art methods. When using the huge vision Transformer and pretraining 300 epochs, MaskDistill obtains 88.3% fine-tuning top-1 accuracy on ImageNet-1k (224 size) and 58.8% semantic segmentation mIoU metric on ADE20k (512 size). The code and pretrained models will be available at https://aka.ms/unimim.
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
Aug 31, 2022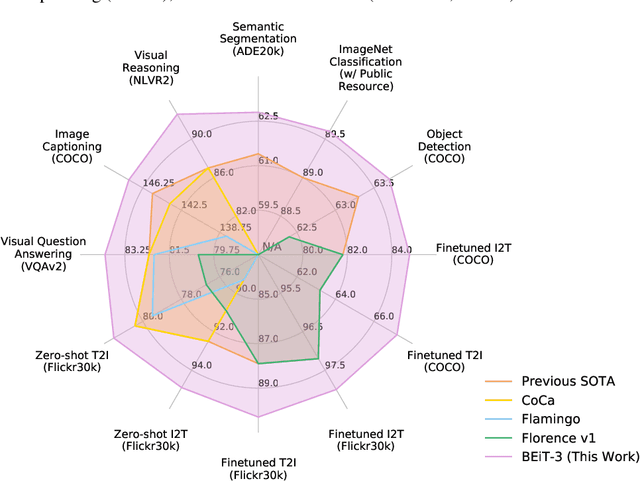
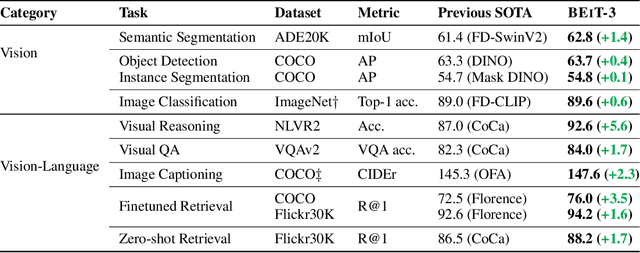
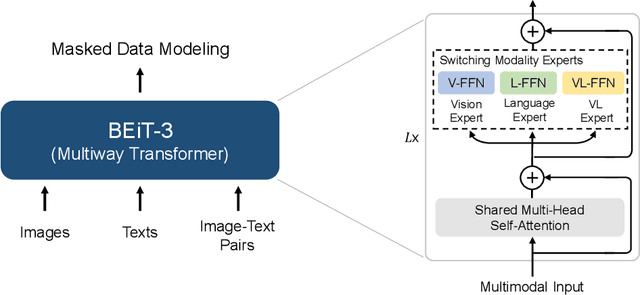

A big convergence of language, vision, and multimodal pretraining is emerging. In this work, we introduce a general-purpose multimodal foundation model BEiT-3, which achieves state-of-the-art transfer performance on both vision and vision-language tasks. Specifically, we advance the big convergence from three aspects: backbone architecture, pretraining task, and model scaling up. We introduce Multiway Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, we perform masked "language" modeling on images (Imglish), texts (English), and image-text pairs ("parallel sentences") in a unified manner. Experimental results show that BEiT-3 obtains state-of-the-art performance on object detection (COCO), semantic segmentation (ADE20K), image classification (ImageNet), visual reasoning (NLVR2), visual question answering (VQAv2), image captioning (COCO), and cross-modal retrieval (Flickr30K, COCO).
BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
Aug 12, 2022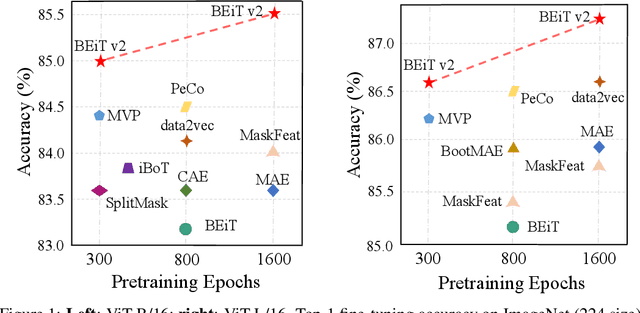
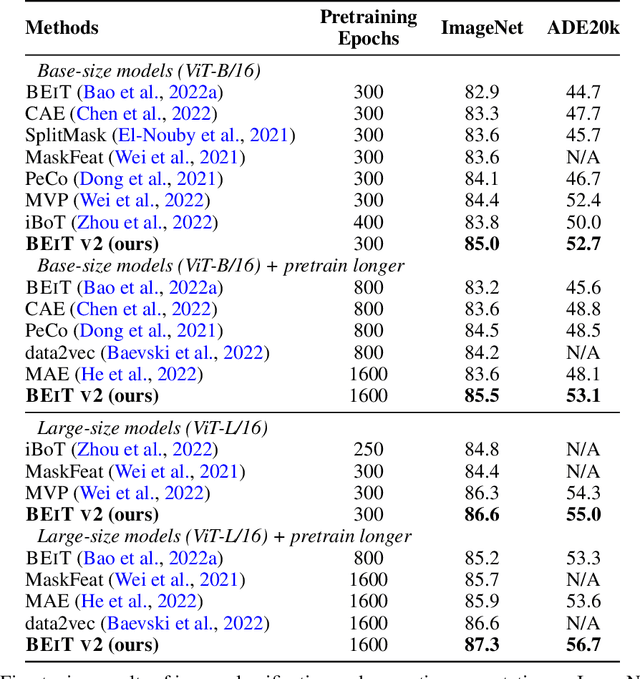
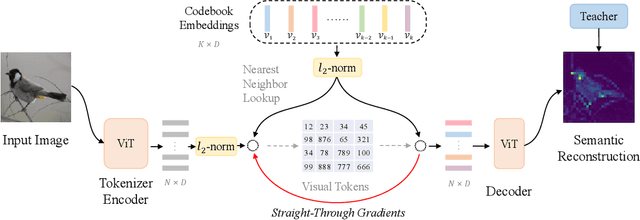

Masked image modeling (MIM) has demonstrated impressive results in self-supervised representation learning by recovering corrupted image patches. However, most methods still operate on low-level image pixels, which hinders the exploitation of high-level semantics for representation models. In this study, we propose to use a semantic-rich visual tokenizer as the reconstruction target for masked prediction, providing a systematic way to promote MIM from pixel-level to semantic-level. Specifically, we introduce vector-quantized knowledge distillation to train the tokenizer, which discretizes a continuous semantic space to compact codes. We then pretrain vision Transformers by predicting the original visual tokens for the masked image patches. Moreover, we encourage the model to explicitly aggregate patch information into a global image representation, which facilities linear probing. Experiments on image classification and semantic segmentation show that our approach outperforms all compared MIM methods. On ImageNet-1K (224 size), the base-size BEiT v2 achieves 85.5% top-1 accuracy for fine-tuning and 80.1% top-1 accuracy for linear probing. The large-size BEiT v2 obtains 87.3% top-1 accuracy for ImageNet-1K (224 size) fine-tuning, and 56.7% mIoU on ADE20K for semantic segmentation. The code and pretrained models are available at https://aka.ms/beit.
VL-BEiT: Generative Vision-Language Pretraining
Jun 02, 2022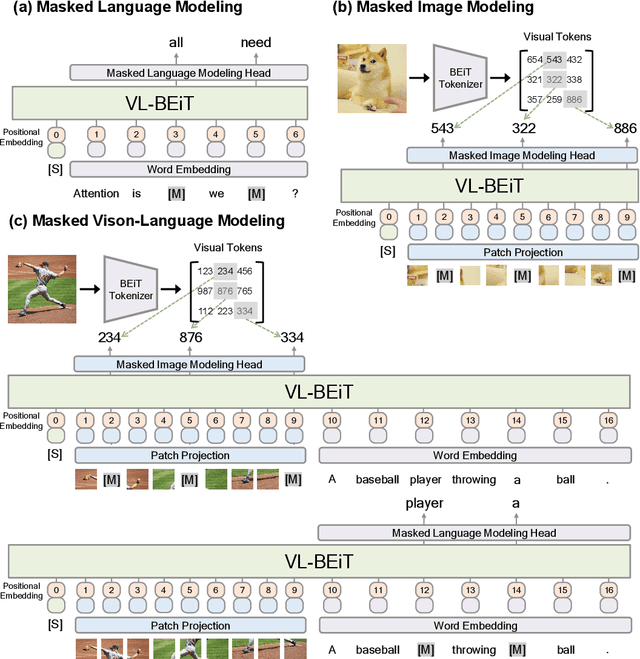
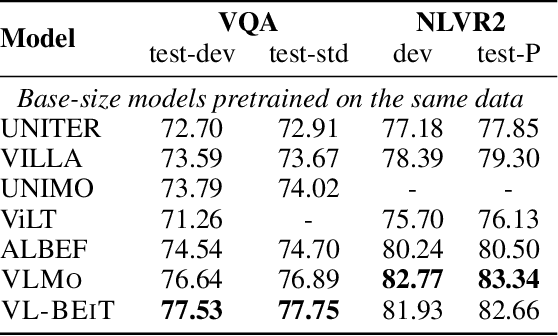
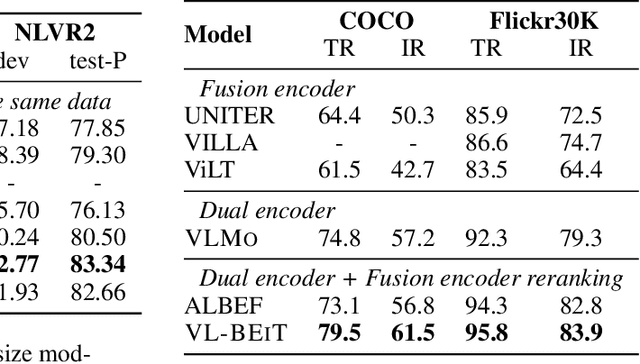
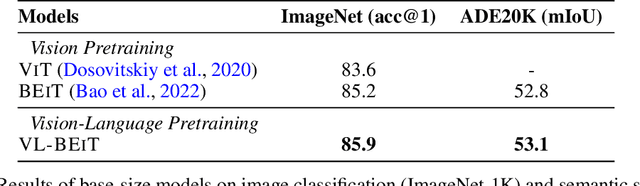
We introduce a vision-language foundation model called VL-BEiT, which is a bidirectional multimodal Transformer learned by generative pretraining. Our minimalist solution conducts masked prediction on both monomodal and multimodal data with a shared Transformer. Specifically, we perform masked vision-language modeling on image-text pairs, masked language modeling on texts, and masked image modeling on images. VL-BEiT is learned from scratch with one unified pretraining task, one shared backbone, and one-stage training. Our method is conceptually simple and empirically effective. Experimental results show that VL-BEiT obtains strong results on various vision-language benchmarks, such as visual question answering, visual reasoning, and image-text retrieval. Moreover, our method learns transferable visual features, achieving competitive performance on image classification, and semantic segmentation.
THE-X: Privacy-Preserving Transformer Inference with Homomorphic Encryption
Jun 02, 2022As more and more pre-trained language models adopt on-cloud deployment, the privacy issues grow quickly, mainly for the exposure of plain-text user data (e.g., search history, medical record, bank account). Privacy-preserving inference of transformer models is on the demand of cloud service users. To protect privacy, it is an attractive choice to compute only with ciphertext in homomorphic encryption (HE). However, enabling pre-trained models inference on ciphertext data is difficult due to the complex computations in transformer blocks, which are not supported by current HE tools yet. In this work, we introduce $\textit{THE-X}$, an approximation approach for transformers, which enables privacy-preserving inference of pre-trained models developed by popular frameworks. $\textit{THE-X}$ proposes a workflow to deal with complex computation in transformer networks, including all the non-polynomial functions like GELU, softmax, and LayerNorm. Experiments reveal our proposed $\textit{THE-X}$ can enable transformer inference on encrypted data for different downstream tasks, all with negligible performance drop but enjoying the theory-guaranteed privacy-preserving advantage.
Corrupted Image Modeling for Self-Supervised Visual Pre-Training
Feb 07, 2022



We introduce Corrupted Image Modeling (CIM) for self-supervised visual pre-training. CIM uses an auxiliary generator with a small trainable BEiT to corrupt the input image instead of using artificial mask tokens, where some patches are randomly selected and replaced with plausible alternatives sampled from the BEiT output distribution. Given this corrupted image, an enhancer network learns to either recover all the original image pixels, or predict whether each visual token is replaced by a generator sample or not. The generator and the enhancer are simultaneously trained and synergistically updated. After pre-training, the enhancer can be used as a high-capacity visual encoder for downstream tasks. CIM is a general and flexible visual pre-training framework that is suitable for various network architectures. For the first time, CIM demonstrates that both ViT and CNN can learn rich visual representations using a unified, non-Siamese framework. Experimental results show that our approach achieves compelling results in vision benchmarks, such as ImageNet classification and ADE20K semantic segmentation. For example, 300-epoch CIM pre-trained vanilla ViT-Base/16 and ResNet-50 obtain 83.3 and 80.6 Top-1 fine-tuning accuracy on ImageNet-1K image classification respectively.
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
Nov 03, 2021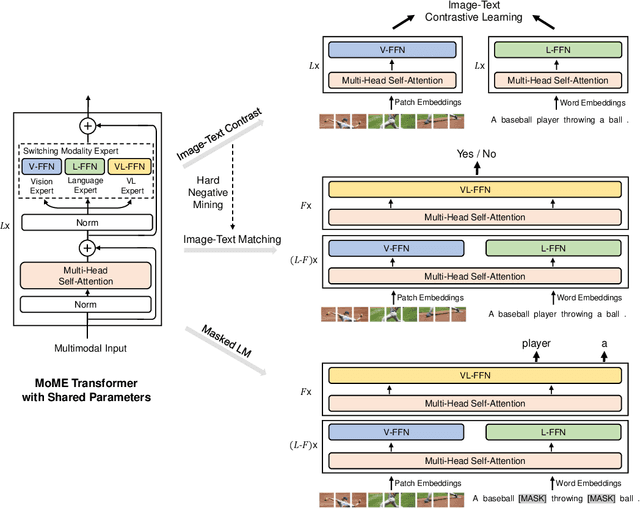
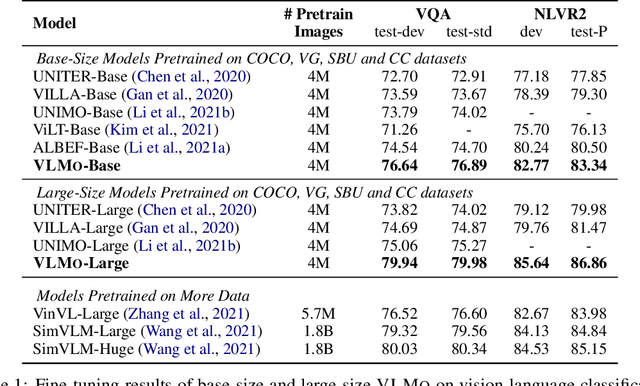
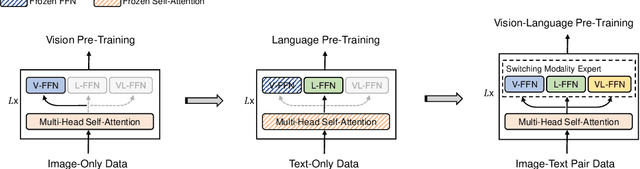
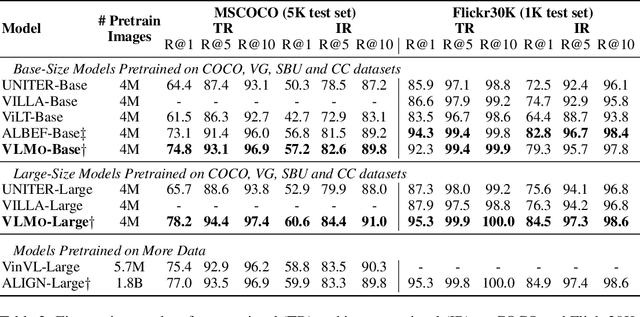
We present a unified Vision-Language pretrained Model (VLMo) that jointly learns a dual encoder and a fusion encoder with a modular Transformer network. Specifically, we introduce Mixture-of-Modality-Experts (MoME) Transformer, where each block contains a pool of modality-specific experts and a shared self-attention layer. Because of the modeling flexibility of MoME, pretrained VLMo can be fine-tuned as a fusion encoder for vision-language classification tasks, or used as a dual encoder for efficient image-text retrieval. Moreover, we propose a stagewise pre-training strategy, which effectively leverages large-scale image-only and text-only data besides image-text pairs. Experimental results show that VLMo achieves state-of-the-art results on various vision-language tasks, including VQA and NLVR2. The code and pretrained models are available at https://aka.ms/vlmo.