 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
Paper and Code
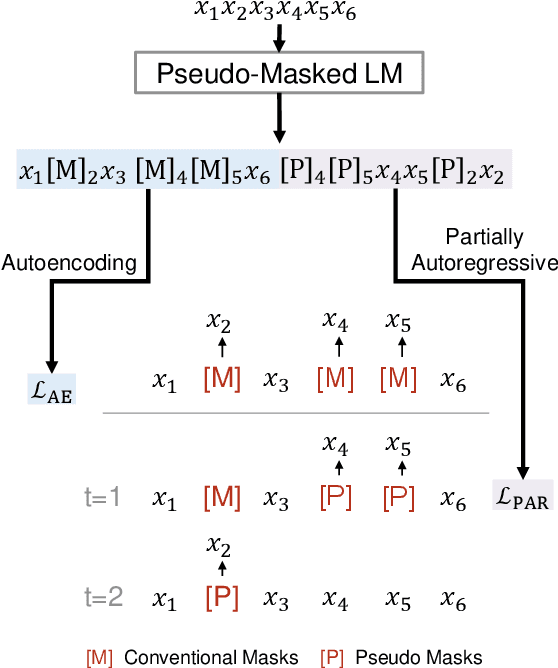

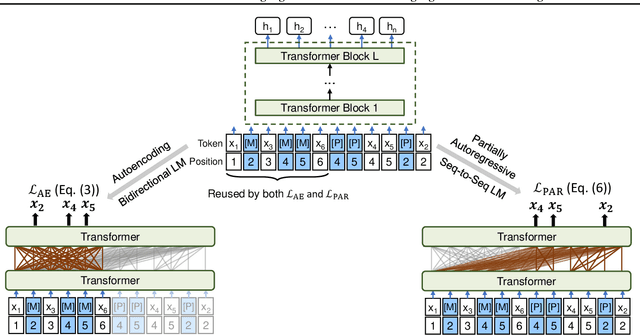
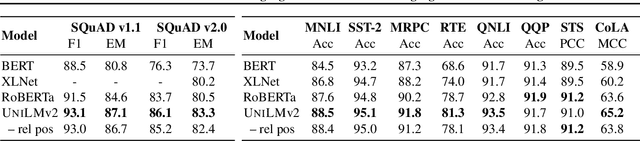
We propose to pre-train a unified language model for both autoencoding and partially autoregressive language modeling tasks using a novel training procedure, referred to as a pseudo-masked language model (PMLM). Given an input text with masked tokens, we rely on conventional masks to learn inter-relations between corrupted tokens and context via autoencoding, and pseudo masks to learn intra-relations between masked spans via partially autoregressive modeling. With well-designed position embeddings and self-attention masks, the context encodings are reused to avoid redundant computation. Moreover, conventional masks used for autoencoding provide global masking information, so that all the position embeddings are accessible in partially autoregressive language modeling. In addition, the two tasks pre-train a unified language model as a bidirectional encoder and a sequence-to-sequence decoder, respectively. Our experiments show that the unified language models pre-trained using PMLM achieve new state-of-the-art results on a wide range of natural language understanding and generation tasks across several widely used benchmarks.