 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Distance Field Demonstration of Imaging-Free Drone Identification in Intracity Environments
Apr 26, 2025



Detecting small objects, such as drones, over long distances presents a significant challenge with broad implications for security, surveillance, environmental monitoring, and autonomous systems. Traditional imaging-based methods rely on high-resolution image acquisition, but are often constrained by range, power consumption, and cost. In contrast, data-driven single-photon-single-pixel light detection and ranging (\text{D\textsuperscript{2}SP\textsuperscript{2}-LiDAR}) provides an imaging-free alternative, directly enabling target identification while reducing system complexity and cost. However, its detection range has been limited to a few hundred meters. Here, we introduce a novel integration of residual neural networks (ResNet) with \text{D\textsuperscript{2}SP\textsuperscript{2}-LiDAR}, incorporating a refined observation model to extend the detection range to 5~\si{\kilo\meter} in an intracity environment while enabling high-accuracy identification of drone poses and types. Experimental results demonstrate that our approach not only outperforms conventional imaging-based recognition systems, but also achieves 94.93\% pose identification accuracy and 97.99\% type classification accuracy, even under weak signal conditions with long distances and low signal-to-noise ratios (SNRs). These findings highlight the potential of imaging-free methods for robust long-range detection of small targets in real-world scenarios.
XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020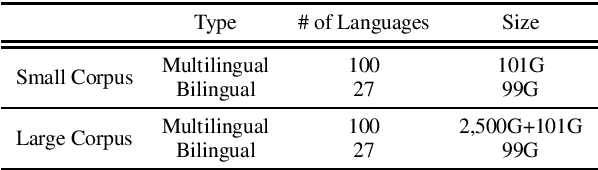
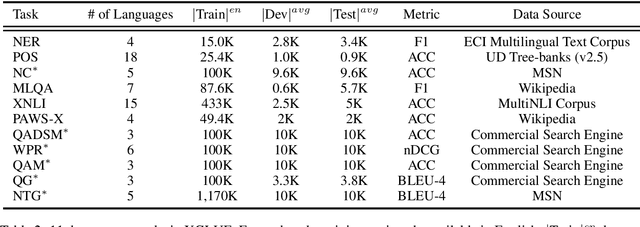
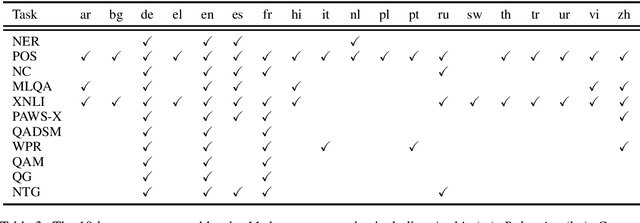
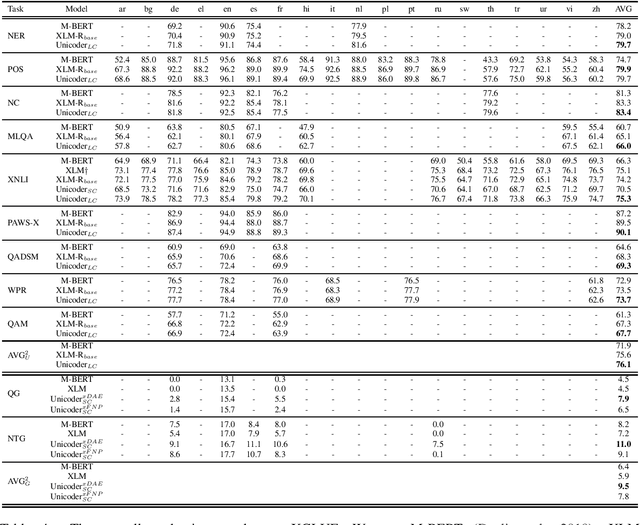
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.