 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Evaluation of Cost-Aware PoQ for Decentralized LLM Inference
Dec 18, 2025


Decentralized large language model (LLM) inference promises transparent and censorship resistant access to advanced AI, yet existing verification approaches struggle to scale to modern models. Proof of Quality (PoQ) replaces cryptographic verification of computation with consensus over output quality, but the original formulation ignores heterogeneous computational costs across inference and evaluator nodes. This paper introduces a cost-aware PoQ framework that integrates explicit efficiency measurements into the reward mechanism for both types of nodes. The design combines ground truth token level F1, lightweight learned evaluators, and GPT based judgments within a unified evaluation pipeline, and adopts a linear reward function that balances normalized quality and cost. Experiments on extractive question answering and abstractive summarization use five instruction tuned LLMs ranging from TinyLlama-1.1B to Llama-3.2-3B and three evaluation models spanning cross encoder and bi encoder architectures. Results show that a semantic textual similarity bi encoder achieves much higher correlation with both ground truth and GPT scores than cross encoders, indicating that evaluator architecture is a critical design choice for PoQ. Quality-cost analysis further reveals that the largest models in the pool are also the most efficient in terms of quality per unit latency. Monte Carlo simulations over 5\,000 PoQ rounds demonstrate that the cost-aware reward scheme consistently assigns higher average rewards to high quality low cost inference models and to efficient evaluators, while penalizing slow low quality nodes. These findings suggest that cost-aware PoQ provides a practical foundation for economically sustainable decentralized LLM inference.
XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020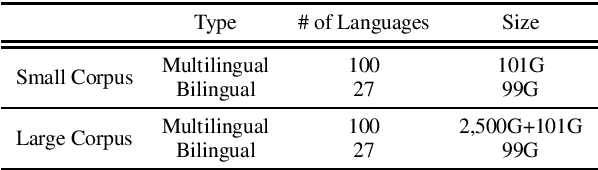
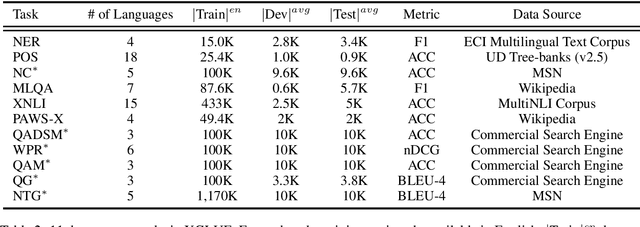
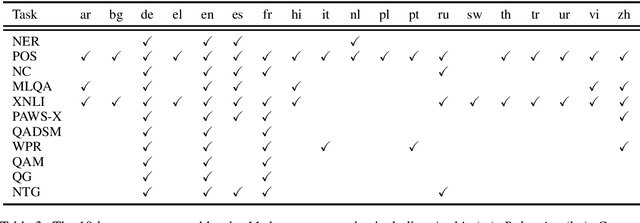
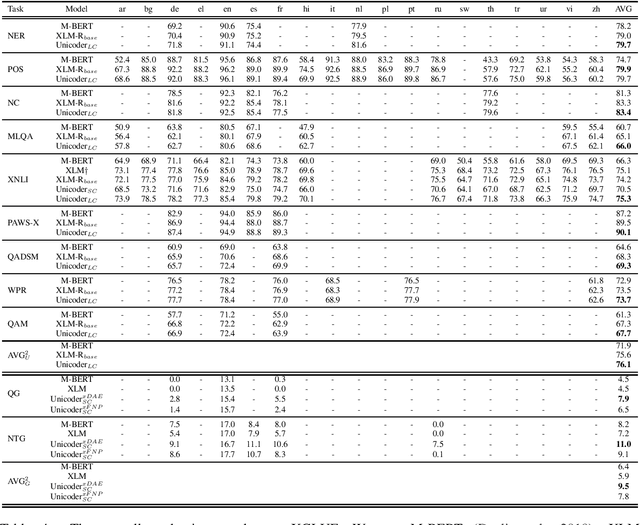
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.