 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Document Representation Learning for Open-Domain Dense Retrieval
Mar 16, 2022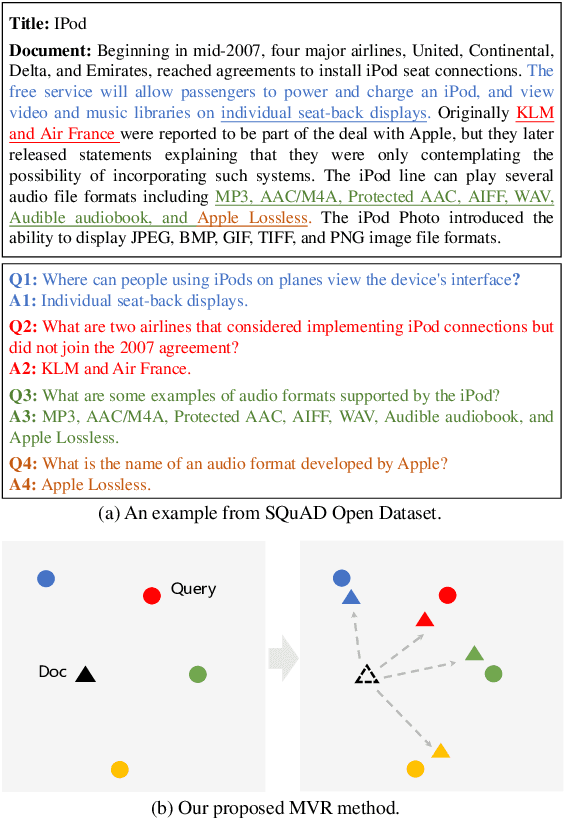
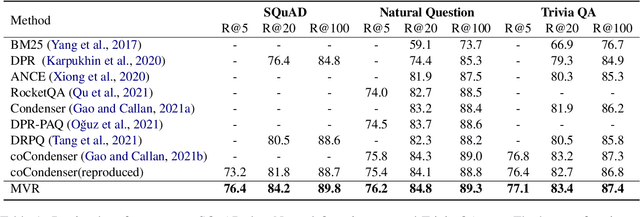
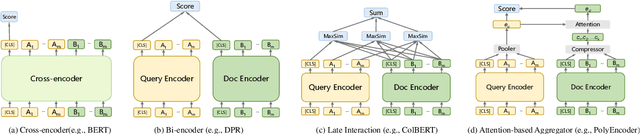
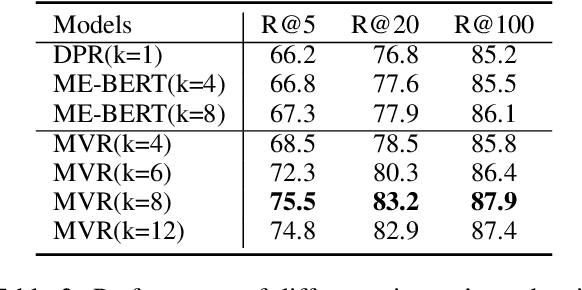
Dense retrieval has achieved impressive advances in first-stage retrieval from a large-scale document collection, which is built on bi-encoder architecture to produce single vector representation of query and document. However, a document can usually answer multiple potential queries from different views. So the single vector representation of a document is hard to match with multi-view queries, and faces a semantic mismatch problem. This paper proposes a multi-view document representation learning framework, aiming to produce multi-view embeddings to represent documents and enforce them to align with different queries. First, we propose a simple yet effective method of generating multiple embeddings through viewers. Second, to prevent multi-view embeddings from collapsing to the same one, we further propose a global-local loss with annealed temperature to encourage the multiple viewers to better align with different potential queries. Experiments show our method outperforms recent works and achieves state-of-the-art results.
Learning from Multiple Noisy Augmented Data Sets for Better Cross-Lingual Spoken Language Understanding
Sep 03, 2021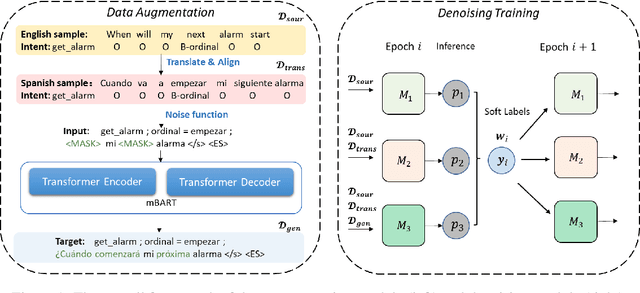
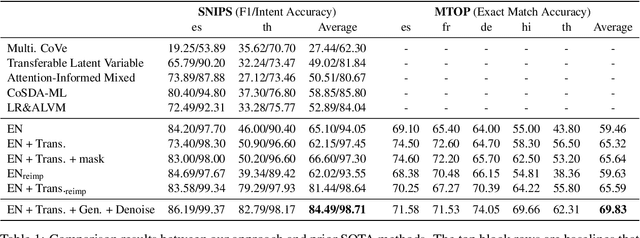
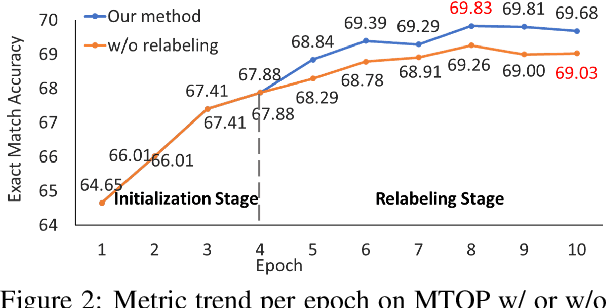
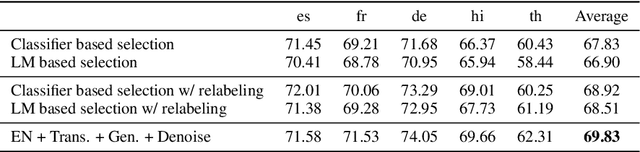
Lack of training data presents a grand challenge to scaling out spoken language understanding (SLU) to low-resource languages. Although various data augmentation approaches have been proposed to synthesize training data in low-resource target languages, the augmented data sets are often noisy, and thus impede the performance of SLU models. In this paper we focus on mitigating noise in augmented data. We develop a denoising training approach. Multiple models are trained with data produced by various augmented methods. Those models provide supervision signals to each other. The experimental results show that our method outperforms the existing state of the art by 3.05 and 4.24 percentage points on two benchmark datasets, respectively. The code will be made open sourced on github.
A Joint and Domain-Adaptive Approach to Spoken Language Understanding
Jul 25, 2021
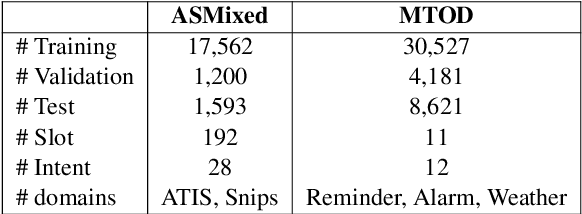
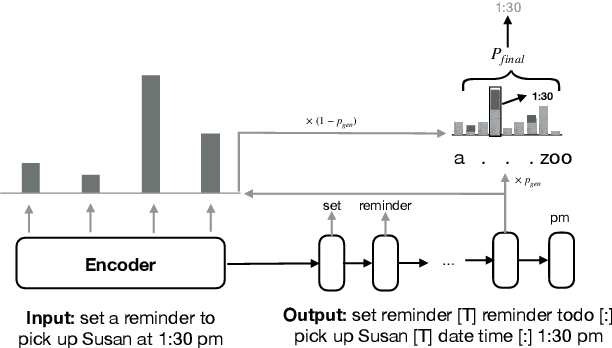
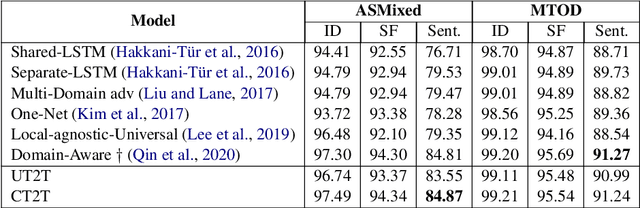
Spoken Language Understanding (SLU) is composed of two subtasks: intent detection (ID) and slot filling (SF). There are two lines of research on SLU. One jointly tackles these two subtasks to improve their prediction accuracy, and the other focuses on the domain-adaptation ability of one of the subtasks. In this paper, we attempt to bridge these two lines of research and propose a joint and domain adaptive approach to SLU. We formulate SLU as a constrained generation task and utilize a dynamic vocabulary based on domain-specific ontology. We conduct experiments on the ASMixed and MTOD datasets and achieve competitive performance with previous state-of-the-art joint models. Besides, results show that our joint model can be effectively adapted to a new domain.
Reinforced Iterative Knowledge Distillation for Cross-Lingual Named Entity Recognition
Jun 01, 2021
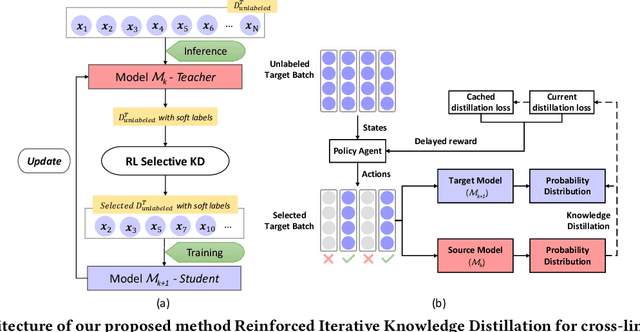

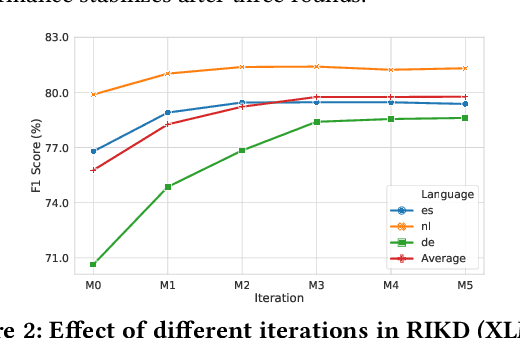
Named entity recognition (NER) is a fundamental component in many applications, such as Web Search and Voice Assistants. Although deep neural networks greatly improve the performance of NER, due to the requirement of large amounts of training data, deep neural networks can hardly scale out to many languages in an industry setting. To tackle this challenge, cross-lingual NER transfers knowledge from a rich-resource language to languages with low resources through pre-trained multilingual language models. Instead of using training data in target languages, cross-lingual NER has to rely on only training data in source languages, and optionally adds the translated training data derived from source languages. However, the existing cross-lingual NER methods do not make good use of rich unlabeled data in target languages, which is relatively easy to collect in industry applications. To address the opportunities and challenges, in this paper we describe our novel practice in Microsoft to leverage such large amounts of unlabeled data in target languages in real production settings. To effectively extract weak supervision signals from the unlabeled data, we develop a novel approach based on the ideas of semi-supervised learning and reinforcement learning. The empirical study on three benchmark data sets verifies that our approach establishes the new state-of-the-art performance with clear edges. Now, the NER techniques reported in this paper are on their way to become a fundamental component for Web ranking, Entity Pane, Answers Triggering, and Question Answering in the Microsoft Bing search engine. Moreover, our techniques will also serve as part of the Spoken Language Understanding module for a commercial voice assistant. We plan to open source the code of the prototype framework after deployment.
CoSQA: 20,000+ Web Queries for Code Search and Question Answering
May 27, 2021
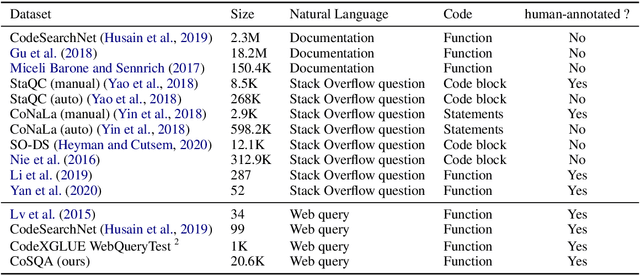

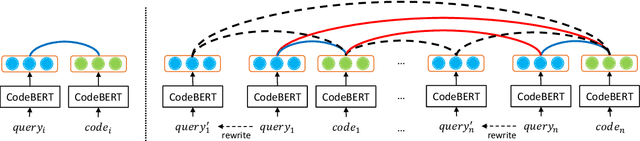
Finding codes given natural language query isb eneficial to the productivity of software developers. Future progress towards better semantic matching between query and code requires richer supervised training resources. To remedy this, we introduce the CoSQA dataset.It includes 20,604 labels for pairs of natural language queries and codes, each annotated by at least 3 human annotators. We further introduce a contrastive learning method dubbed CoCLR to enhance query-code matching, which works as a data augmenter to bring more artificially generated training instances. We show that evaluated on CodeXGLUE with the same CodeBERT model, training on CoSQA improves the accuracy of code question answering by 5.1%, and incorporating CoCLR brings a further improvement of 10.5%.
Retrieval Enhanced Model for Commonsense Generation
May 24, 2021
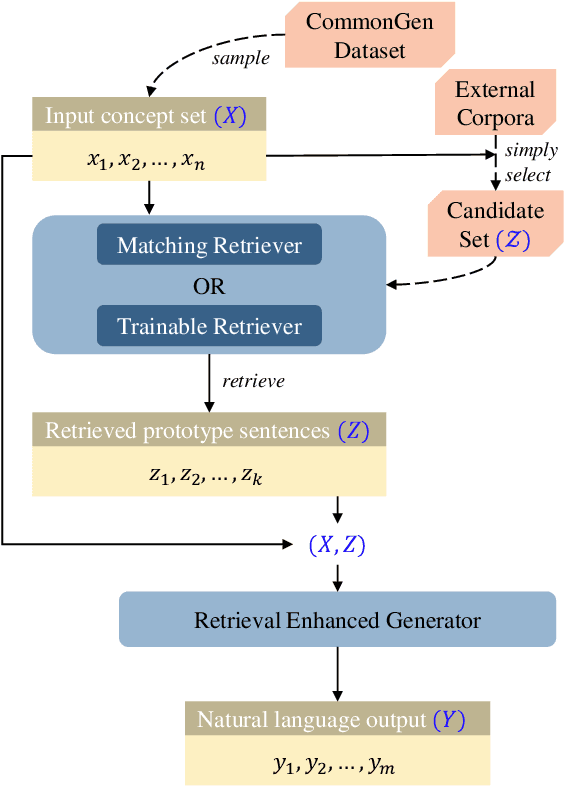
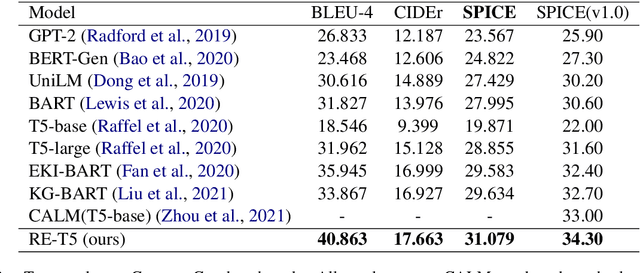

Commonsense generation is a challenging task of generating a plausible sentence describing an everyday scenario using provided concepts. Its requirement of reasoning over commonsense knowledge and compositional generalization ability even puzzles strong pre-trained language generation models. We propose a novel framework using retrieval methods to enhance both the pre-training and fine-tuning for commonsense generation. We retrieve prototype sentence candidates by concept matching and use them as auxiliary input. For fine-tuning, we further boost its performance with a trainable sentence retriever. We demonstrate experimentally on the large-scale CommonGen benchmark that our approach achieves new state-of-the-art results.
WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach
Apr 09, 2021
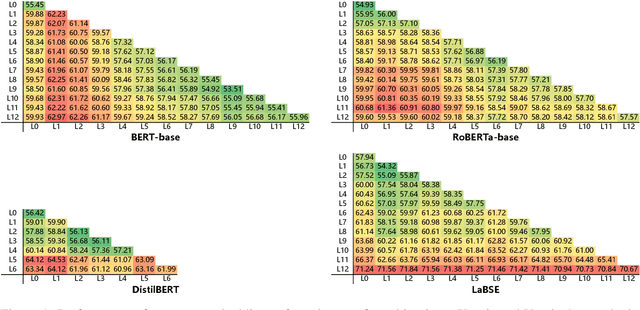
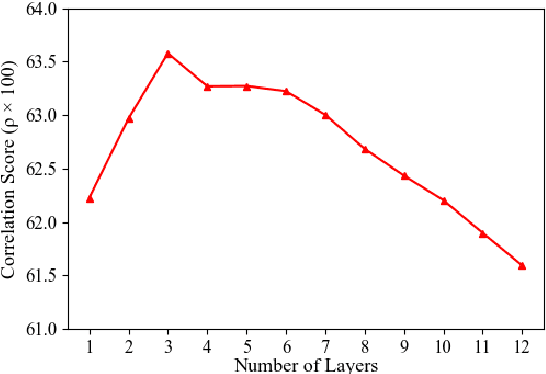
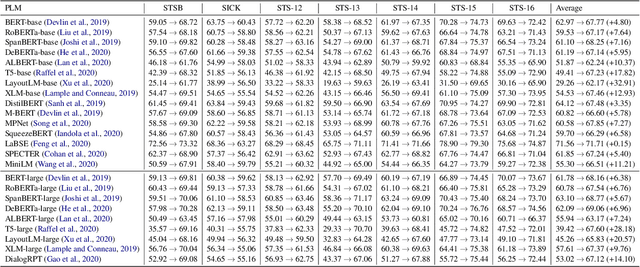
Producing the embedding of a sentence in an unsupervised way is valuable to natural language matching and retrieval problems in practice. In this work, we conduct a thorough examination of pretrained model based unsupervised sentence embeddings. We study on four pretrained models and conduct massive experiments on seven datasets regarding sentence semantics. We have there main findings. First, averaging all tokens is better than only using [CLS] vector. Second, combining both top andbottom layers is better than only using top layers. Lastly, an easy whitening-based vector normalization strategy with less than 10 lines of code consistently boosts the performance.
Generating Human Readable Transcript for Automatic Speech Recognition with Pre-trained Language Model
Feb 22, 2021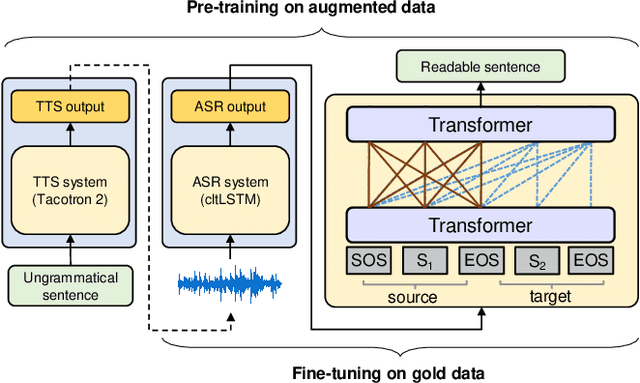
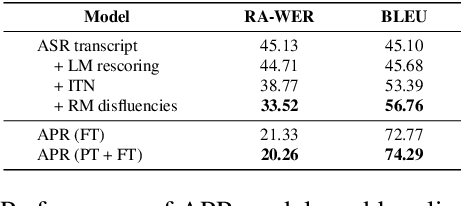

Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to disfluency, filter words, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline. In this work, we propose an ASR post-processing model that aims to transform the incorrect and noisy ASR output into a readable text for humans and downstream tasks. We leverage the Metadata Extraction (MDE) corpus to construct a task-specific dataset for our study. Since the dataset is small, we propose a novel data augmentation method and use a two-stage training strategy to fine-tune the RoBERTa pre-trained model. On the constructed test set, our model outperforms a production two-step pipeline-based post-processing method by a large margin of 13.26 on readability-aware WER (RA-WER) and 17.53 on BLEU metrics. Human evaluation also demonstrates that our method can generate more human-readable transcripts than the baseline method.
Improving Zero-shot Neural Machine Translation on Language-specific Encoders-Decoders
Feb 12, 2021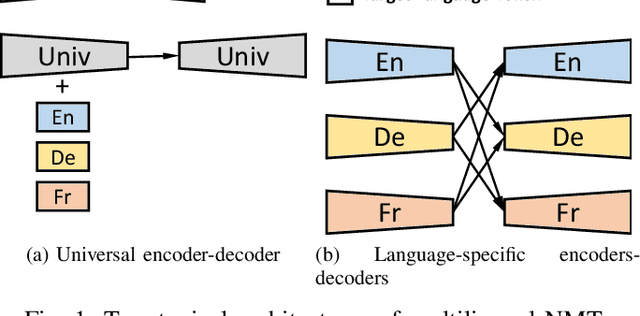

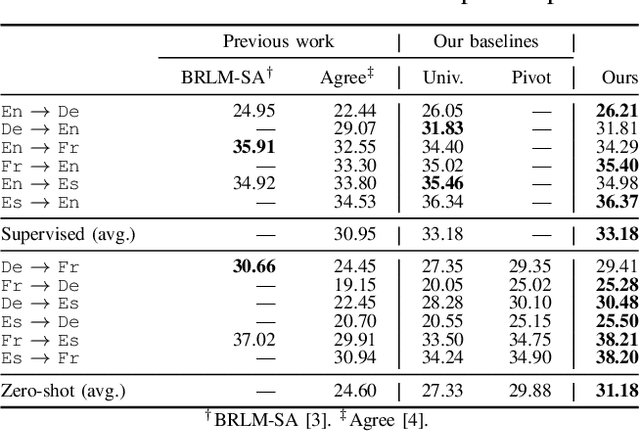
Recently, universal neural machine translation (NMT) with shared encoder-decoder gained good performance on zero-shot translation. Unlike universal NMT, jointly trained language-specific encoders-decoders aim to achieve universal representation across non-shared modules, each of which is for a language or language family. The non-shared architecture has the advantage of mitigating internal language competition, especially when the shared vocabulary and model parameters are restricted in their size. However, the performance of using multiple encoders and decoders on zero-shot translation still lags behind universal NMT. In this work, we study zero-shot translation using language-specific encoders-decoders. We propose to generalize the non-shared architecture and universal NMT by differentiating the Transformer layers between language-specific and interlingua. By selectively sharing parameters and applying cross-attentions, we explore maximizing the representation universality and realizing the best alignment of language-agnostic information. We also introduce a denoising auto-encoding (DAE) objective to jointly train the model with the translation task in a multi-task manner. Experiments on two public multilingual parallel datasets show that our proposed model achieves a competitive or better results than universal NMT and strong pivot baseline. Moreover, we experiment incrementally adding new language to the trained model by only updating the new model parameters. With this little effort, the zero-shot translation between this newly added language and existing languages achieves a comparable result with the model trained jointly from scratch on all languages.
CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
Feb 09, 2021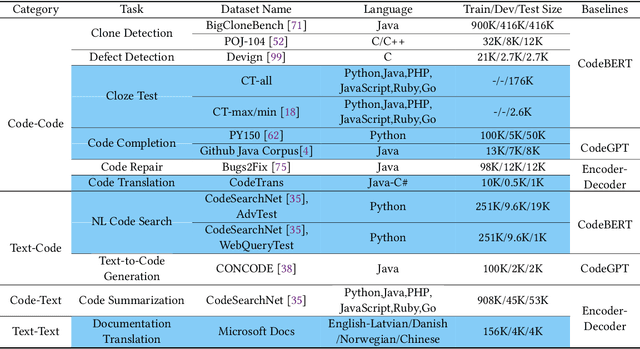

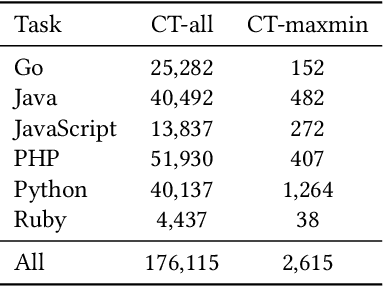

Benchmark datasets have a significant impact on accelerating research in programming language tasks. In this paper, we introduce CodeXGLUE, a benchmark dataset to foster machine learning research for program understanding and generation. CodeXGLUE includes a collection of 10 tasks across 14 datasets and a platform for model evaluation and comparison. CodeXGLUE also features three baseline systems, including the BERT-style, GPT-style, and Encoder-Decoder models, to make it easy for researchers to use the platform. The availability of such data and baselines can help the development and validation of new methods that can be applied to various program understanding and generation problems.