 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLGE: A New General Language Generation Evaluation Benchmark
Paper and Code
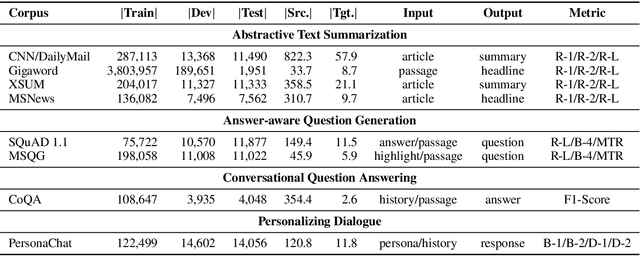
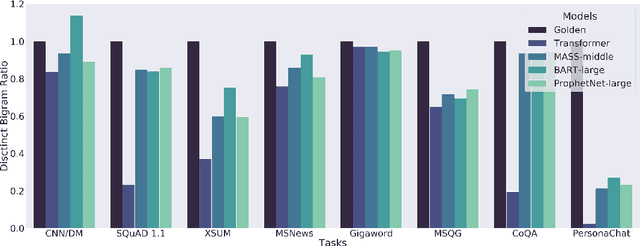

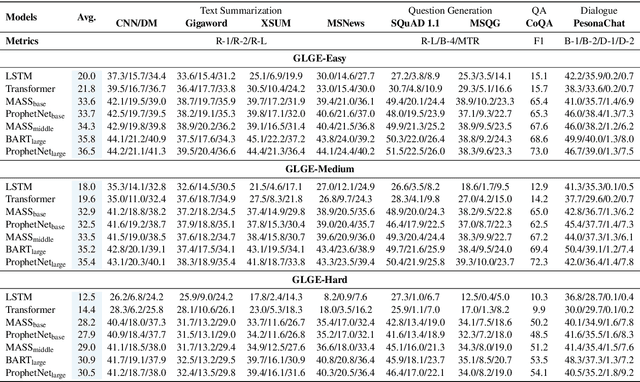
Multi-task benchmarks such as GLUE and SuperGLUE have driven great progress of pretraining and transfer learning in Natural Language Processing (NLP). These benchmarks mostly focus on a range of Natural Language Understanding (NLU) tasks, without considering the Natural Language Generation (NLG) models. In this paper, we present the General Language Generation Evaluation (GLGE), a new multi-task benchmark for evaluating the generalization capabilities of NLG models across eight language generation tasks. For each task, we continue to design three subtasks in terms of task difficulty (GLGE-Easy, GLGE-Medium, and GLGE-Hard). This introduces 24 subtasks to comprehensively compare model performance. To encourage research on pretraining and transfer learning on NLG models, we make GLGE publicly available and build a leaderboard with strong baselines including MASS, BART, and ProphetNet\footnote{The source code and dataset will be publicly available at https://github.com/microsoft/glge.