 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision SmolMamba: Spike-Guided Token Pruning for Energy-Efficient Spiking State-Space Vision Models
Apr 28, 2026Spiking Transformers have shown strong potential for long-range visual modeling through spike-driven self-attention. However, their quadratic token interactions remain fundamentally misaligned with the sparse and event-driven nature of spiking neural computation. To address this limitation, we propose Vision SmolMamba, an energy-efficient spiking state-space architecture that integrates spike-driven dynamics with linear-time selective recurrence. The key idea is a Spike-Guided Spatio-Temporal Token Pruner (SST-TP), which estimates token importance using both spike activation strength and first-spike latency. This mechanism progressively removes redundant tokens while preserving salient spatio-temporal information, enabling efficient scaling with token sparsity. Based on this mechanism, the proposed SmolMamba block incorporates spike events directly into bidirectional state-space recurrence, forming a spiking state-space vision backbone for efficient long-range modeling. Extensive experiments on both static and event-based benchmarks, including ImageNet-1K, CIFAR10/100, CIFAR10-DVS, and DVS128 Gesture, demonstrate that Vision SmolMamba consistently achieves superior accuracy-efficiency trade-offs. In particular, it reduces the estimated energy cost by at least 1.5x compared with prior spiking Transformer baselines and a Spiking Mamba variant while maintaining competitive or improved accuracy. These results demonstrate that combining spike-guided token sparsity with state-space modeling offers a scalable and energy-efficient paradigm for spiking vision systems.
QB-LIF: Learnable-Scale Quantized Burst Neurons for Efficient SNNs
Apr 28, 2026Binary spike coding enables sparse and event-driven computation in spiking neural networks (SNNs), yet its 1-bit-per-timestep representation fundamentally limits information throughput. This bottleneck becomes increasingly restrictive in deep architectures under short simulation horizons. We propose the Quantized Burst-LIF (QB-LIF) neuron, which reformulates burst spiking as a saturated uniform quantization of membrane potentials with a learnable scale. Instead of relying on predefined multi-threshold structures, QB-LIF treats the quantization scale as a trainable parameter, allowing each layer to autonomously adapt its spiking resolution to the underlying membrane-potential statistics. To preserve hardware efficiency, we introduce an absorbable scale strategy that folds the learned quantized scale into synaptic weights during inference, maintaining a strict accumulate-only (AC) execution paradigm. To enable stable optimization in the discrete multi-level space, we further design ReLSG-ET, a rectified-linear surrogate gradient with exponential tails that sustains gradient flow across burst intervals. Extensive experiments on static (CIFAR-10/100, ImageNet) and event-driven (CIFAR10-DVS, DVS128-Gesture) benchmarks demonstrate that QB-LIF consistently outperforms binary and fixed-burst SNNs, achieving higher accuracy under ultra-low latency while preserving neuromorphic compatibility.
BSViT: A Burst Spiking Vision Transformer for Expressive and Efficient Visual Representation Learning
Apr 25, 2026Spiking Vision Transformers (S-ViTs) offer a promising framework for energy-efficient visual learning. However, existing designs remain limited by two fundamental issues: the restricted information capacity of binary spike coding and the dense token interactions introduced by global self-attention. To address these challenges, this work proposes BSViT, a burst spiking-driven Vision Transformer featuring a Dual-Channel Burst Spiking Self-Attention (DBSSA) mechanism. DBSSA encodes queries with binary spikes and keys with burst spikes to enhance representational capacity. The value pathway adopts dual excitatory and inhibitory binary channels, enabling signed modulation and richer spike interactions. Importantly, the entire attention operation preserves addition-only computation, ensuring compatibility with energy-efficient neuromorphic hardware. To further reduce spike activity and incorporate spatial priors, a patch adjacency masking strategy is introduced to restrict attention to local neighborhoods, resulting in structure-aware sparsity and reduced computational overhead. In addition, burst spike coding is systematically integrated across the network to increase spike-level representational capacity beyond conventional binary spiking. Extensive experiments on both static and event-based vision benchmarks demonstrate that BSViT consistently outperforms existing spiking Transformers in accuracy while maintaining competitive energy efficiency.
HybridReg: Robust 3D Point Cloud Registration with Hybrid Motions
Mar 10, 2025



Scene-level point cloud registration is very challenging when considering dynamic foregrounds. Existing indoor datasets mostly assume rigid motions, so the trained models cannot robustly handle scenes with non-rigid motions. On the other hand, non-rigid datasets are mainly object-level, so the trained models cannot generalize well to complex scenes. This paper presents HybridReg, a new approach to 3D point cloud registration, learning uncertainty mask to account for hybrid motions: rigid for backgrounds and non-rigid/rigid for instance-level foregrounds. First, we build a scene-level 3D registration dataset, namely HybridMatch, designed specifically with strategies to arrange diverse deforming foregrounds in a controllable manner. Second, we account for different motion types and formulate a mask-learning module to alleviate the interference of deforming outliers. Third, we exploit a simple yet effective negative log-likelihood loss to adopt uncertainty to guide the feature extraction and correlation computation. To our best knowledge, HybridReg is the first work that exploits hybrid motions for robust point cloud registration. Extensive experiments show HybridReg's strengths, leading it to achieve state-of-the-art performance on both widely-used indoor and outdoor datasets.
MLPs Compass: What is learned when MLPs are combined with PLMs?
Jan 03, 2024



While Transformer-based pre-trained language models and their variants exhibit strong semantic representation capabilities, the question of comprehending the information gain derived from the additional components of PLMs remains an open question in this field. Motivated by recent efforts that prove Multilayer-Perceptrons (MLPs) modules achieving robust structural capture capabilities, even outperforming Graph Neural Networks (GNNs), this paper aims to quantify whether simple MLPs can further enhance the already potent ability of PLMs to capture linguistic information. Specifically, we design a simple yet effective probing framework containing MLPs components based on BERT structure and conduct extensive experiments encompassing 10 probing tasks spanning three distinct linguistic levels. The experimental results demonstrate that MLPs can indeed enhance the comprehension of linguistic structure by PLMs. Our research provides interpretable and valuable insights into crafting variations of PLMs utilizing MLPs for tasks that emphasize diverse linguistic structures.
Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance
Oct 20, 2023



Document-level event argument extraction poses new challenges of long input and cross-sentence inference compared to its sentence-level counterpart. However, most prior works focus on capturing the relations between candidate arguments and the event trigger in each event, ignoring two crucial points: a) non-argument contextual clue information; b) the relevance among argument roles. In this paper, we propose a SCPRG (Span-trigger-based Contextual Pooling and latent Role Guidance) model, which contains two novel and effective modules for the above problem. The Span-Trigger-based Contextual Pooling(STCP) adaptively selects and aggregates the information of non-argument clue words based on the context attention weights of specific argument-trigger pairs from pre-trained model. The Role-based Latent Information Guidance (RLIG) module constructs latent role representations, makes them interact through role-interactive encoding to capture semantic relevance, and merges them into candidate arguments. Both STCP and RLIG introduce no more than 1% new parameters compared with the base model and can be easily applied to other event extraction models, which are compact and transplantable. Experiments on two public datasets show that our SCPRG outperforms previous state-of-the-art methods, with 1.13 F1 and 2.64 F1 improvements on RAMS and WikiEvents respectively. Further analyses illustrate the interpretability of our model.
Revisiting Graph Meaning Representations through Decoupling Contextual Representation Learning and Structural Information Propagation
Oct 15, 2023In the field of natural language understanding, the intersection of neural models and graph meaning representations (GMRs) remains a compelling area of research. Despite the growing interest, a critical gap persists in understanding the exact influence of GMRs, particularly concerning relation extraction tasks. Addressing this, we introduce DAGNN-plus, a simple and parameter-efficient neural architecture designed to decouple contextual representation learning from structural information propagation. Coupled with various sequence encoders and GMRs, this architecture provides a foundation for systematic experimentation on two English and two Chinese datasets. Our empirical analysis utilizes four different graph formalisms and nine parsers. The results yield a nuanced understanding of GMRs, showing improvements in three out of the four datasets, particularly favoring English over Chinese due to highly accurate parsers. Interestingly, GMRs appear less effective in literary-domain datasets compared to general-domain datasets. These findings lay the groundwork for better-informed design of GMRs and parsers to improve relation classification, which is expected to tangibly impact the future trajectory of natural language understanding research.
CARLG: Leveraging Contextual Clues and Role Correlations for Improving Document-level Event Argument Extraction
Oct 08, 2023



Document-level event argument extraction (EAE) is a crucial but challenging subtask in information extraction. Most existing approaches focus on the interaction between arguments and event triggers, ignoring two critical points: the information of contextual clues and the semantic correlations among argument roles. In this paper, we propose the CARLG model, which consists of two modules: Contextual Clues Aggregation (CCA) and Role-based Latent Information Guidance (RLIG), effectively leveraging contextual clues and role correlations for improving document-level EAE. The CCA module adaptively captures and integrates contextual clues by utilizing context attention weights from a pre-trained encoder. The RLIG module captures semantic correlations through role-interactive encoding and provides valuable information guidance with latent role representation. Notably, our CCA and RLIG modules are compact, transplantable and efficient, which introduce no more than 1% new parameters and can be easily equipped on other span-base methods with significant performance boost. Extensive experiments on the RAMS, WikiEvents, and MLEE datasets demonstrate the superiority of the proposed CARLG model. It outperforms previous state-of-the-art approaches by 1.26 F1, 1.22 F1, and 1.98 F1, respectively, while reducing the inference time by 31%. Furthermore, we provide detailed experimental analyses based on the performance gains and illustrate the interpretability of our model.
Improving Image Captioning with Control Signal of Sentence Quality
Jun 07, 2022

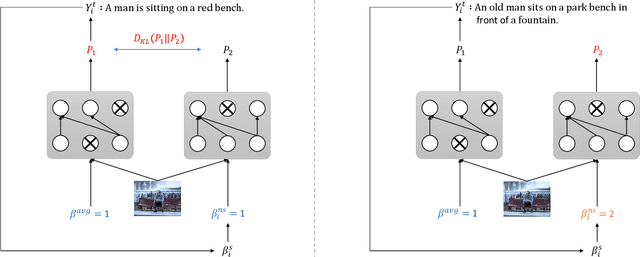
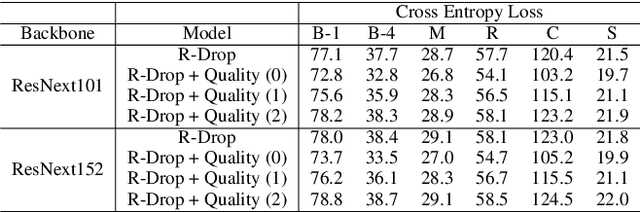
In the dataset of image captioning, each image is aligned with several captions. Despite the fact that the quality of these descriptions varies, existing captioning models treat them equally in the training process. In this paper, we propose a new control signal of sentence quality, which is taken as an additional input to the captioning model. By integrating the control signal information, captioning models are aware of the quality level of the target sentences and handle them differently. Moreover, we propose a novel reinforcement training method specially designed for the control signal of sentence quality: Quality-oriented Self-Annotated Training (Q-SAT). Equipped with R-Drop strategy, models controlled by the highest quality level surpass baseline models a lot on accuracy-based evaluation metrics, which validates the effectiveness of our proposed methods.
Double Thompson Sampling in Finite stochastic Games
Feb 28, 2022We consider the trade-off problem between exploration and exploitation under finite discounted Markov Decision Process, where the state transition matrix of the underlying environment stays unknown. We propose a double Thompson sampling reinforcement learning algorithm(DTS) to solve this kind of problem. This algorithm achieves a total regret bound of $\tilde{\mathcal{O}}(D\sqrt{SAT})$in time horizon $T$ with $S$ states, $A$ actions and diameter $D$. DTS consists of two parts, the first part is the traditional part where we apply the posterior sampling method on transition matrix based on prior distribution. In the second part, we employ a count-based posterior update method to balance between the local optimal action and the long-term optimal action in order to find the global optimal game value. We established a regret bound of $\tilde{\mathcal{O}}(\sqrt{T}/S^{2})$. Which is by far the best regret bound for finite discounted Markov Decision Process to our knowledge. Numerical results proves the efficiency and superiority of our approach.