 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Proof: Recipe for Formal Theorem Proving Beyond Auto-Regressive Generation
Jun 17, 2026Enhancing the formal math reasoning capabilities of Large Language Models (LLMs) has become a key focus in both mathematical and computer science communities in recent years. While significant progress has been made in using state-of-the-art Auto-Regressive (AR) LLMs for formal theorem proving, these models suffer from inherent limitations. Their next-token prediction generation methods may yield suboptimal performance due to the challenges of long-range coherence and the compounding of errors over long sequences. Recent advancements in diffusion LLMs (dLLMs), which generate text through iterative denoising of a multi-token block, offer a promising alternative. However, the application of dLLMs to formal mathematics, where maintaining long-range coherence is critical, remains largely understudied. To address the challenges above, we propose **Diffusion-Proof**, to the best of our knowledge, the first framework to train and apply dLLMs for formal theorem proving. Our frameworks contain training and inference methods for two models. The first one is *dLLM-Prover-7B*, which performs whole-proof writing with long-range coherent tactic usage. The second one is *dLLM-Corrector-7B*, which is a novel large block diffusion-based correction model. It leverages the in-filling capabilities of dLLMs to perform local proof correction using bi-directional information. Extensive experiments demonstrate that **Diffusion-Proof** relatively significantly outperforms the AR LLM baseline trained under the same dataset. **Diffusion-Proof** achieves an absolute improvement of **1.61%** on ProofNet-Test and **6.14%** on MiniF2F-Test benchmarks compare to the baseline. Notably, **Diffusion-Proof** successfully resolves one IMO problem that more advanced thinking model DeepSeek-Prover-V2-7B could not solve, showcasing the unique advantage of dLLMs in formal theorem proving.
Does Traversal Order Matter? A Systematic Study of Tree Traversal Methods in Transformer Grammars
Jun 15, 2026Transformer Grammars (TGs) enhance language modeling by incorporating syntactic tree structures. Despite the potentially significant impact on model performance of how syntactic trees are linearized in TGs, existing studies rely solely on Depth-First Traversal (DFT) for linearization. In this paper, we expand the traversal design space by exploring Breadth-First Traversal (BFT) and a novel hybrid traversal strategy, Production-Rule Traversal (PRT), which combines the structural lookahead of BFT with the early lexical generation of DFT. We integrate these traversal methods with varying tree configurations and masking strategies, and empirically evaluate their performance on language modeling, syntactic generalization and summarization. We reveal the inherent trade-offs between nested composition and global lookahead, providing actionable recommendations for designing task-aware Transformer Grammars.
Lean4Agent: Formal Modeling and Verification for Agent Workflow and Trajectory
Jun 02, 2026Equipping Large Language Models (LLMs) to execute reliable multi-step workflows has become a central challenge in artificial intelligence. Despite recent advances in LLMs' agentic capabilities, most agent systems still lack formal methods for specifying, verifying, and debugging their workflow and execution trajectories. This challenge mirrors a long-standing problem in mathematics, where the ambiguity of natural languages (NLs) motivates the development of formal languages (FLs). Inspired by this paradigm, we propose **Lean4Agent**, to the best of our knowledge, the first framework that uses Lean4, a dependent-type FL to model and verify agent behavior. **Lean4Agent** launches **FormalAgentLib**, an extensible Lean4 library for formally modeling and verifying agent workflows' semantic consistency under explicit assumptions, and enabling localization of execution-time failures revealed by trajectories. Building on **FormalAgentLib**, we further develop **LeanEvolve**, which applies results in **FormalAgentLib** to revise workflows to enhance its capability. Extensive experiments on a hard problem subset of SWE-Bench-Verified and a subset of ELAIP-Bench across 5 leading LLMs indicate that the verification-passing workflows outperform the failing ones by an average of **11.94%**, and **LeanEvolve** further improves SWE performance by **7.47%** on average. Furthermore, **Lean4Agent** establishes a foundation for a new field of using expressive dependent-type FL to formally model and verify agent behavior.
CaptchaMind: Training CAPTCHA Solvers via Reinforcement Learning with Explicit Reasoning Supervision
May 19, 2026CAPTCHAs are widely deployed as human verification mechanisms and frequently block intelligent agents from completing end-to-end automation in real-world web environments. Solving modern CAPTCHAs requires robust multi-step visual reasoning and interaction capabilities, yet training-based approaches have remained absent due to the lack of large-scale training data and process-level annotations. We introduce CaptchaBench, the first CAPTCHA benchmark designed to support large-scale training, comprising 16,000 programmatically generated samples across eight task categories with detailed region and process-level annotations. Systematic evaluation on CaptchaBench reveals that existing methods fail consistently on tasks requiring fine-grained visual detail capture and region-level comparison. We therefore present CaptchaMind, an RL-based solver trained with explicit reasoning process supervision, achieving 82.9% average success rate across eight tasks and 71.0% on real-world instances, substantially outperforming all existing methods without closed-source APIs.
Geometric and Spectral Alignment for Deep Neural Network II
May 04, 2026This paper develops the angular and static-channel component of Geometric and Spectral Alignment for residual Jacobian chains. Starting from Cartan-coordinate rigidity and fitted effective-rank windows, we study how dominant singular subspaces are transported across adjacent layers and how the resulting finite matrices can be displayed in physical channel coordinates. The main results are deterministic, margin-verified results. We bound the error between full interface transport and its dominant-window truncation, add fitted-tail errors so that empirical spectra can be certified against the Gibbs--Cartan tail model, and distinguish source-mode incidence from fully physical input-output channel incidence. Given row groups and active supports, the Physical Alignment Matrix decomposes orthogonally as core plus overlap plus noise. Active-column gaps, pairwise overlap margins, and noise bounds combine into a static certificate radius under which the full transport and the truncated transport induce the same active supports, pairwise incidence graph, SRS sets, hub columns, and core/overlap/noise masks. The finer SC/SA/ST labels of the Invariant Channel Mapping require additional row-energy and profile-correlation margins, stated as explicit perturbation tests. The empirical section reports the matrices and block-energy heatmaps that measure these certificate quantities across CNNs, language models, and vision/diffusion backbones. The figures are interpreted as finite-dimensional measurements; complete membership in the Physical GSA certificate domain requires checking the numerical margin protocol stated in Section 10.
DiscreteRTC: Discrete Diffusion Policies are Natural Asynchronous Executors
Apr 27, 2026Unlike chatbots, physical AI must act while the world keeps evolving. Therefore, the inter-chunk pause of synchronous executors are fatal for dynamic tasks regardless of how fast the inference is. Asynchronous execution -- thinking while acting -- is therefore a structural requirement, and real-time chunking (RTC) makes it viable by recasting chunk transitions as inpainting: freezing committed actions and consistently generating the remainder. However, RTC with flow-matching policy is structurally suboptimal: its inpainting comes from inference-time corrections rather than the base policy, yielding little pre-training benefit, specific fine-tuning, heuristic guidance, and extra computation that inflates the latency. In this work, we observe that discrete diffusion policies, which generate actions by iteratively unmasking, are natural asynchronous executors that resolve all limitations at once: they are fine-tuning free since inpainting is their native operation, while early stopping further provides adaptive guidance and reduces inference cost. We propose DiscreteRTC, which replaces external corrections with native unmasking, and show on dynamic simulated benchmarks and real-world dynamic manipulation tasks that it achieves higher success rates than continuous RTC and other baselines. In summary, DiscreteRTC is simpler to implement with 0 lines of code for async inpainting, faster at inference with only 0.7x computation compared with generating actions from scratch, and better at execution with 50% higher success rate in real-world dynamic pick task compared with flow-matching-based RTC. More visualizations are on https://outsider86.github.io/DiscreteRTCSite/.
AgentSPEX: An Agent SPecification and EXecution Language
Apr 14, 2026Language-model agent systems commonly rely on reactive prompting, in which a single instruction guides the model through an open-ended sequence of reasoning and tool-use steps, leaving control flow and intermediate state implicit and making agent behavior potentially difficult to control. Orchestration frameworks such as LangGraph, DSPy, and CrewAI impose greater structure through explicit workflow definitions, but tightly couple workflow logic with Python, making agents difficult to maintain and modify. In this paper, we introduce AgentSPEX, an Agent SPecification and EXecution Language for specifying LLM-agent workflows with explicit control flow and modular structure, along with a customizable agent harness. AgentSPEX supports typed steps, branching and loops, parallel execution, reusable submodules, and explicit state management, and these workflows execute within an agent harness that provides tool access, a sandboxed virtual environment, and support for checkpointing, verification, and logging. Furthermore, we provide a visual editor with synchronized graph and workflow views for authoring and inspection. We include ready-to-use agents for deep research and scientific research, and we evaluate AgentSPEX on 7 benchmarks. Finally, we show through a user study that AgentSPEX provides a more interpretable and accessible workflow-authoring paradigm than a popular existing agent framework.
Mean Flow Policy with Instantaneous Velocity Constraint for One-step Action Generation
Feb 14, 2026Learning expressive and efficient policy functions is a promising direction in reinforcement learning (RL). While flow-based policies have recently proven effective in modeling complex action distributions with a fast deterministic sampling process, they still face a trade-off between expressiveness and computational burden, which is typically controlled by the number of flow steps. In this work, we propose mean velocity policy (MVP), a new generative policy function that models the mean velocity field to achieve the fastest one-step action generation. To ensure its high expressiveness, an instantaneous velocity constraint (IVC) is introduced on the mean velocity field during training. We theoretically prove that this design explicitly serves as a crucial boundary condition, thereby improving learning accuracy and enhancing policy expressiveness. Empirically, our MVP achieves state-of-the-art success rates across several challenging robotic manipulation tasks from Robomimic and OGBench. It also delivers substantial improvements in training and inference speed over existing flow-based policy baselines.
DADP: Domain Adaptive Diffusion Policy
Feb 03, 2026Learning domain adaptive policies that can generalize to unseen transition dynamics, remains a fundamental challenge in learning-based control. Substantial progress has been made through domain representation learning to capture domain-specific information, thus enabling domain-aware decision making. We analyze the process of learning domain representations through dynamical prediction and find that selecting contexts adjacent to the current step causes the learned representations to entangle static domain information with varying dynamical properties. Such mixture can confuse the conditioned policy, thereby constraining zero-shot adaptation. To tackle the challenge, we propose DADP (Domain Adaptive Diffusion Policy), which achieves robust adaptation through unsupervised disentanglement and domain-aware diffusion injection. First, we introduce Lagged Context Dynamical Prediction, a strategy that conditions future state estimation on a historical offset context; by increasing this temporal gap, we unsupervisedly disentangle static domain representations by filtering out transient properties. Second, we integrate the learned domain representations directly into the generative process by biasing the prior distribution and reformulating the diffusion target. Extensive experiments on challenging benchmarks across locomotion and manipulation demonstrate the superior performance, and the generalizability of DADP over prior methods. More visualization results are available on the https://outsider86.github.io/DomainAdaptiveDiffusionPolicy/.
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025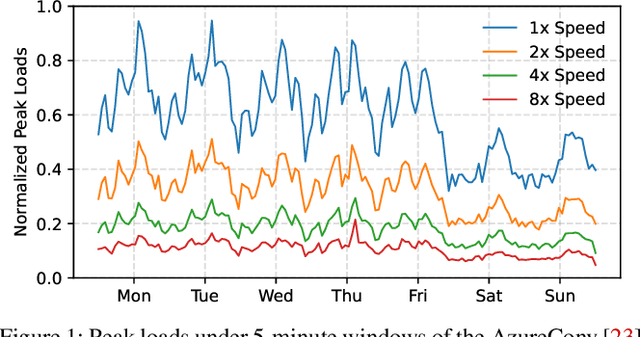
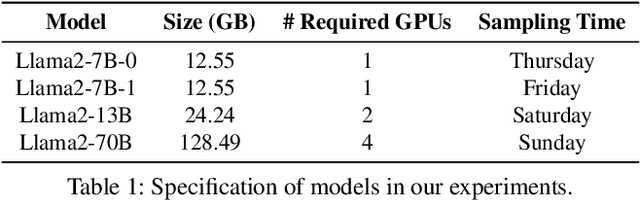
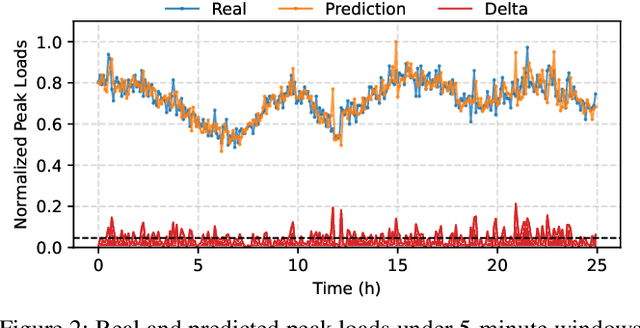
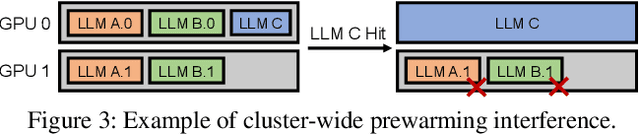
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.