 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuffle the Context: RoPE-Perturbed Self-Distillation for Long-Context Adaptation
Apr 15, 2026Large language models (LLMs) increasingly operate in settings that require reliable long-context understanding, such as retrieval-augmented generation and multi-document reasoning. A common strategy is to fine-tune pretrained short-context models at the target sequence length. However, we find that standard long-context adaptation can remain brittle: model accuracy depends strongly on the absolute placement of relevant evidence, exhibiting high positional variance even when controlling for task format and difficulty. We propose RoPE-Perturbed Self-Distillation, a training regularizer that improves positional robustness. The core idea is to form alternative "views" of the same training sequence by perturbing its RoPE indices -- effectively moving parts of the context to different positions -- and to train the model to produce consistent predictions across views via self-distillation. This encourages reliance on semantic signals instead of brittle position dependencies. Experiments on long-context adaptation of Llama-3-8B and Qwen-3-4B demonstrate consistent gains on long-context benchmarks, including up to 12.04% improvement on RULER-64K for Llama-3-8B and 2.71% on RULER-256K for Qwen-3-4B after SFT, alongside improved length extrapolation beyond the training context window.
Rethinking Language Model Scaling under Transferable Hypersphere Optimization
Mar 30, 2026Scaling laws for large language models depend critically on the optimizer and parameterization. Existing hyperparameter transfer laws are mainly developed for first-order optimizers, and they do not structurally prevent training instability at scale. Recent hypersphere optimization methods constrain weight matrices to a fixed-norm hypersphere, offering a promising alternative for more stable scaling. We introduce HyperP (Hypersphere Parameterization), the first framework for transferring optimal learning rates across model width, depth, training tokens, and Mixture-of-Experts (MoE) granularity under the Frobenius-sphere constraint with the Muon optimizer. We prove that weight decay is a first-order no-op on the Frobenius sphere, show that Depth-$μ$P remains necessary, and find that the optimal learning rate follows the same data-scaling power law with the "magic exponent" 0.32 previously observed for AdamW. A single base learning rate tuned at the smallest scale transfers across all compute budgets under HyperP, yielding $1.58\times$ compute efficiency over a strong Muon baseline at $6\times10^{21}$ FLOPs. Moreover, HyperP delivers transferable stability: all monitored instability indicators, including $Z$-values, output RMS, and activation outliers, remain bounded and non-increasing under training FLOPs scaling. We also propose SqrtGate, an MoE gating mechanism derived from the hypersphere constraint that preserves output RMS across MoE granularities for improved granularity scaling, and show that hypersphere optimization enables substantially larger auxiliary load-balancing weights, yielding both strong performance and good expert balance. We release our training codebase at https://github.com/microsoft/ArchScale.
Test-time Recursive Thinking: Self-Improvement without External Feedback
Feb 03, 2026Modern Large Language Models (LLMs) have shown rapid improvements in reasoning capabilities, driven largely by reinforcement learning (RL) with verifiable rewards. Here, we ask whether these LLMs can self-improve without the need for additional training. We identify two core challenges for such systems: (i) efficiently generating diverse, high-quality candidate solutions, and (ii) reliably selecting correct answers in the absence of ground-truth supervision. To address these challenges, we propose Test-time Recursive Thinking (TRT), an iterative self-improvement framework that conditions generation on rollout-specific strategies, accumulated knowledge, and self-generated verification signals. Using TRT, open-source models reach 100% accuracy on AIME-25/24, and on LiveCodeBench's most difficult problems, closed-source models improve by 10.4-14.8 percentage points without external feedback.
RE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
Training LLMs for Divide-and-Conquer Reasoning Elevates Test-Time Scalability
Feb 02, 2026Large language models (LLMs) have demonstrated strong reasoning capabilities through step-by-step chain-of-thought (CoT) reasoning. Nevertheless, at the limits of model capability, CoT often proves insufficient, and its strictly sequential nature constrains test-time scalability. A potential alternative is divide-and-conquer (DAC) reasoning, which decomposes a complex problem into subproblems to facilitate more effective exploration of the solution. Although promising, our analysis reveals a fundamental misalignment between general-purpose post-training and DAC-style inference, which limits the model's capacity to fully leverage this potential. To bridge this gap and fully unlock LLMs' reasoning capabilities on the most challenging tasks, we propose an end-to-end reinforcement learning (RL) framework to enhance their DAC-style reasoning capacity. At each step, the policy decomposes a problem into a group of subproblems, solves them sequentially, and addresses the original one conditioned on the subproblem solutions, with both decomposition and solution integrated into RL training. Under comparable training, our DAC-style framework endows the model with a higher performance ceiling and stronger test-time scalability, surpassing CoT by 8.6% in Pass@1 and 6.3% in Pass@32 on competition-level benchmarks.
RLBR: Reinforcement Learning with Biasing Rewards for Contextual Speech Large Language Models
Jan 19, 2026Speech large language models (LLMs) have driven significant progress in end-to-end speech understanding and recognition, yet they continue to struggle with accurately recognizing rare words and domain-specific terminology. This paper presents a novel fine-tuning method, Reinforcement Learning with Biasing Rewards (RLBR), which employs a specialized biasing words preferred reward to explicitly emphasize biasing words in the reward calculation. In addition, we introduce reference-aware mechanisms that extend the reinforcement learning algorithm with reference transcription to strengthen the potential trajectory exploration space. Experiments on the LibriSpeech corpus across various biasing list sizes demonstrate that RLBR delivers substantial performance improvements over a strong supervised fine-tuning (SFT) baseline and consistently outperforms several recently published methods. The proposed approach achieves excellent performance on the LibriSpeech test-clean and test-other sets, reaching Biasing Word Error Rates (BWERs) of 0.59% / 2.11%, 1.09% / 3.24%, and 1.36% / 4.04% for biasing list sizes of 100, 500, and 1000, respectively, without compromising the overall WERs.
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Jul 09, 2025



Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
SwS: Self-aware Weakness-driven Problem Synthesis in Reinforcement Learning for LLM Reasoning
Jun 10, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for training large language models (LLMs) on complex reasoning tasks, such as mathematical problem solving. A prerequisite for the scalability of RLVR is a high-quality problem set with precise and verifiable answers. However, the scarcity of well-crafted human-labeled math problems and limited-verification answers in existing distillation-oriented synthetic datasets limit their effectiveness in RL. Additionally, most problem synthesis strategies indiscriminately expand the problem set without considering the model's capabilities, leading to low efficiency in generating useful questions. To mitigate this issue, we introduce a Self-aware Weakness-driven problem Synthesis framework (SwS) that systematically identifies model deficiencies and leverages them for problem augmentation. Specifically, we define weaknesses as questions that the model consistently fails to learn through its iterative sampling during RL training. We then extract the core concepts from these failure cases and synthesize new problems to strengthen the model's weak areas in subsequent augmented training, enabling it to focus on and gradually overcome its weaknesses. Without relying on external knowledge distillation, our framework enables robust generalization byempowering the model to self-identify and address its weaknesses in RL, yielding average performance gains of 10.0% and 7.7% on 7B and 32B models across eight mainstream reasoning benchmarks.
R&D-Agent: Automating Data-Driven AI Solution Building Through LLM-Powered Automated Research, Development, and Evolution
May 20, 2025Recent advances in AI and ML have transformed data science, yet increasing complexity and expertise requirements continue to hinder progress. While crowdsourcing platforms alleviate some challenges, high-level data science tasks remain labor-intensive and iterative. To overcome these limitations, we introduce R&D-Agent, a dual-agent framework for iterative exploration. The Researcher agent uses performance feedback to generate ideas, while the Developer agent refines code based on error feedback. By enabling multiple parallel exploration traces that merge and enhance one another, R&D-Agent narrows the gap between automated solutions and expert-level performance. Evaluated on MLE-Bench, R&D-Agent emerges as the top-performing machine learning engineering agent, demonstrating its potential to accelerate innovation and improve precision across diverse data science applications. We have open-sourced R&D-Agent on GitHub: https://github.com/microsoft/RD-Agent.
Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math
Apr 30, 2025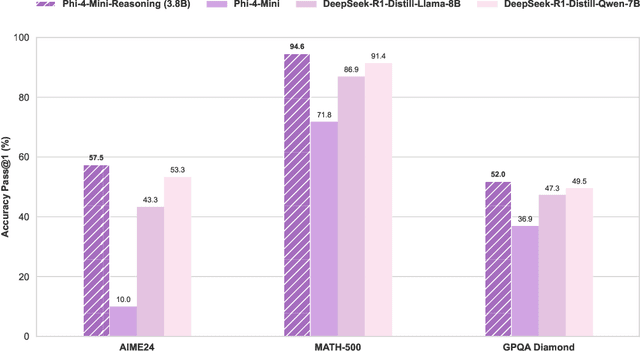
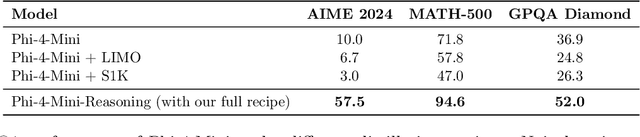
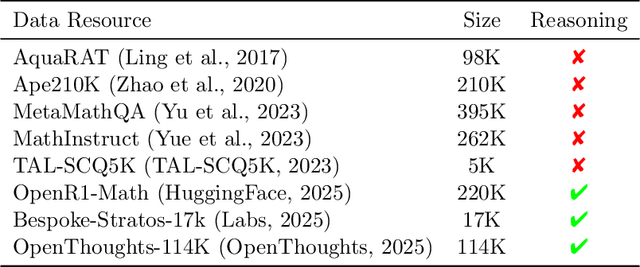
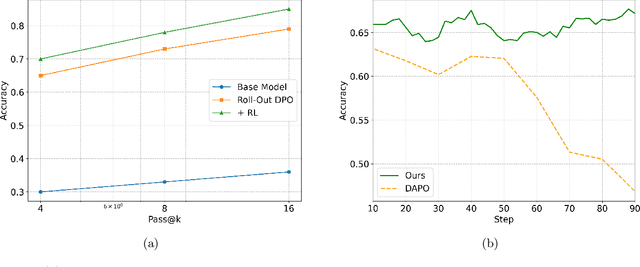
Chain-of-Thought (CoT) significantly enhances formal reasoning capabilities in Large Language Models (LLMs) by training them to explicitly generate intermediate reasoning steps. While LLMs readily benefit from such techniques, improving reasoning in Small Language Models (SLMs) remains challenging due to their limited model capacity. Recent work by Deepseek-R1 demonstrates that distillation from LLM-generated synthetic data can substantially improve the reasoning ability of SLM. However, the detailed modeling recipe is not disclosed. In this work, we present a systematic training recipe for SLMs that consists of four steps: (1) large-scale mid-training on diverse distilled long-CoT data, (2) supervised fine-tuning on high-quality long-CoT data, (3) Rollout DPO leveraging a carefully curated preference dataset, and (4) Reinforcement Learning (RL) with Verifiable Reward. We apply our method on Phi-4-Mini, a compact 3.8B-parameter model. The resulting Phi-4-Mini-Reasoning model exceeds, on math reasoning tasks, much larger reasoning models, e.g., outperforming DeepSeek-R1-Distill-Qwen-7B by 3.2 points and DeepSeek-R1-Distill-Llama-8B by 7.7 points on Math-500. Our results validate that a carefully designed training recipe, with large-scale high-quality CoT data, is effective to unlock strong reasoning capabilities even in resource-constrained small models.