 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Alignment of Speech and Language Latent Spaces for End-to-End Speech Recognition and Understanding
Oct 23, 2021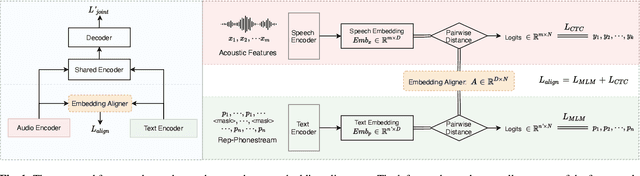
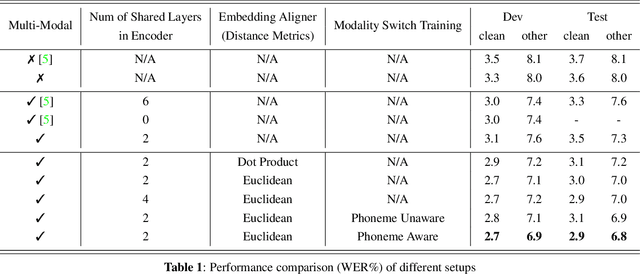
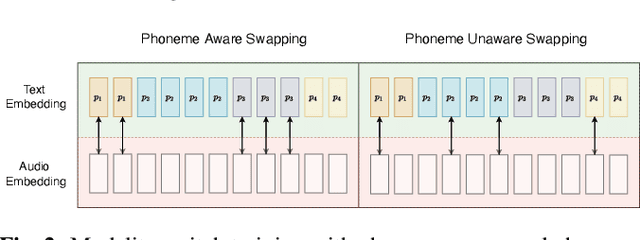
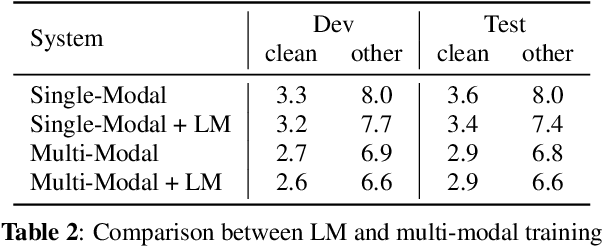
The advances in attention-based encoder-decoder (AED) networks have brought great progress to end-to-end (E2E) automatic speech recognition (ASR). One way to further improve the performance of AED-based E2E ASR is to introduce an extra text encoder for leveraging extensive text data and thus capture more context-aware linguistic information. However, this approach brings a mismatch problem between the speech encoder and the text encoder due to the different units used for modeling. In this paper, we propose an embedding aligner and modality switch training to better align the speech and text latent spaces. The embedding aligner is a shared linear projection between text encoder and speech encoder trained by masked language modeling (MLM) loss and connectionist temporal classification (CTC), respectively. The modality switch training randomly swaps speech and text embeddings based on the forced alignment result to learn a joint representation space. Experimental results show that our proposed approach achieves a relative 14% to 19% word error rate (WER) reduction on Librispeech ASR task. We further verify its effectiveness on spoken language understanding (SLU), i.e., an absolute 2.5% to 2.8% F1 score improvement on SNIPS slot filling task.
PI(t)D(t) Control and Motion Profiling for Omnidirectional Mobile Robots
Oct 19, 2021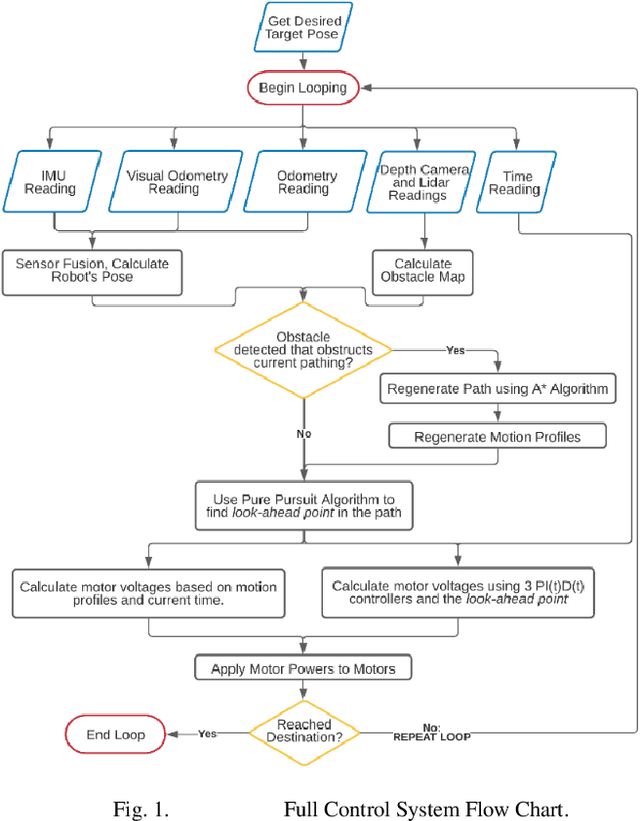

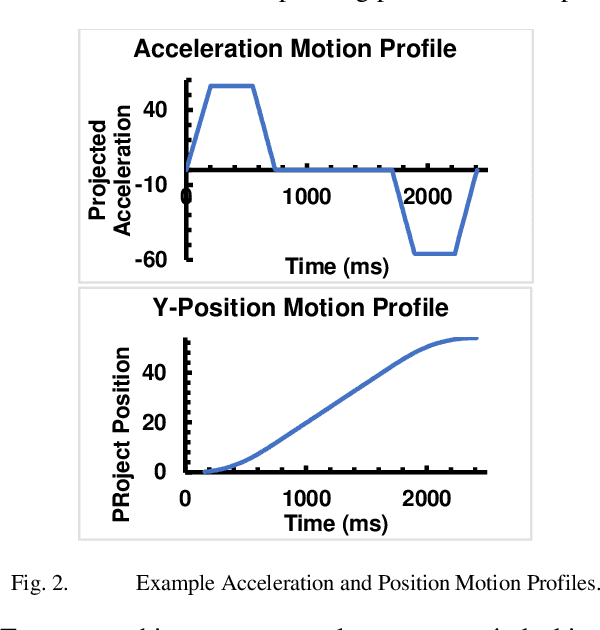
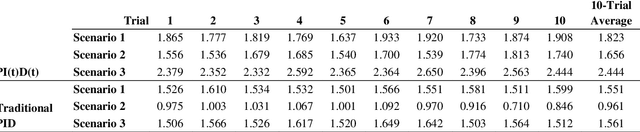
Recently, a trend is emerging toward human-servicing autonomous mobile robots, with diverse applications including delivery of supplies in hospitals, hotels, or labs where personnel are scarce, or reacting to indoor emergencies. However, existing autonomous mobile robot (AMR) motion is slow and inefficient, a foundational barrier to proliferation of human-servicing applications. This research has developed a motion control architecture that demonstrates the potential of several algorithms for increasing speed and efficiency. These include a novel PI(t)D(t) controller that sets integral and derivative gains as functions of time, and motion-profiling applied for holonomic motion. Resulting performance indicates potential for faster, more efficient AMRs, that maintain high levels of accuracy and repeatability. The hope is that this research can serve as a proof of concept for faster motion-control, to remove a key barrier to further use of human-servicing mobile robots.
Leveraging Knowledge in Multilingual Commonsense Reasoning
Oct 16, 2021

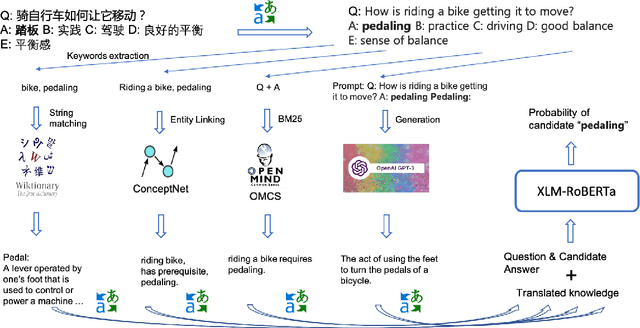
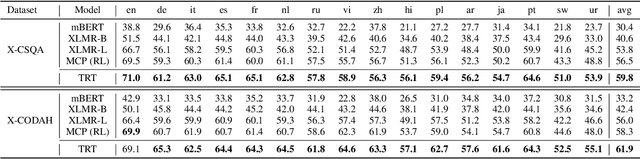
Commonsense reasoning (CSR) requires the model to be equipped with general world knowledge. While CSR is a language-agnostic process, most comprehensive knowledge sources are in few popular languages, especially English. Thus, it remains unclear how to effectively conduct multilingual commonsense reasoning (XCSR) for various languages. In this work, we propose to utilize English knowledge sources via a translate-retrieve-translate (TRT) strategy. For multilingual commonsense questions and choices, we collect related knowledge via translation and retrieval from the knowledge sources. The retrieved knowledge is then translated into the target language and integrated into a pre-trained multilingual language model via visible knowledge attention. Then we utilize a diverse of 4 English knowledge sources to provide more comprehensive coverage of knowledge in different formats. Extensive results on the XCSR benchmark demonstrate that TRT with external knowledge can significantly improve multilingual commonsense reasoning in both zero-shot and translate-train settings, outperforming 3.3 and 3.6 points over the previous state-of-the-art on XCSR benchmark datasets (X-CSQA and X-CODAH).
End-to-End Segmentation-based News Summarization
Oct 15, 2021

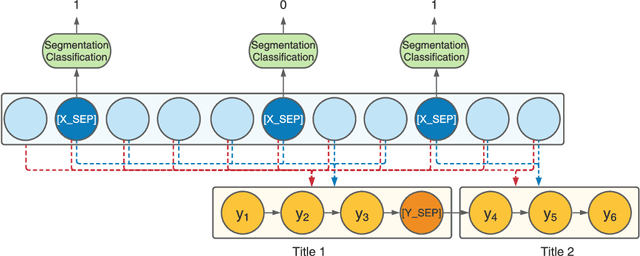
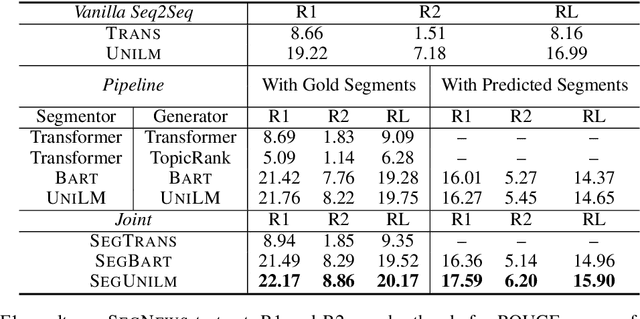
In this paper, we bring a new way of digesting news content by introducing the task of segmenting a news article into multiple sections and generating the corresponding summary to each section. We make two contributions towards this new task. First, we create and make available a dataset, SegNews, consisting of 27k news articles with sections and aligned heading-style section summaries. Second, we propose a novel segmentation-based language generation model adapted from pre-trained language models that can jointly segment a document and produce the summary for each section. Experimental results on SegNews demonstrate that our model can outperform several state-of-the-art sequence-to-sequence generation models for this new task.
Dict-BERT: Enhancing Language Model Pre-training with Dictionary
Oct 13, 2021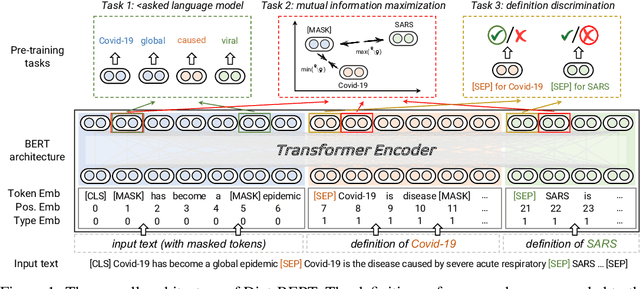
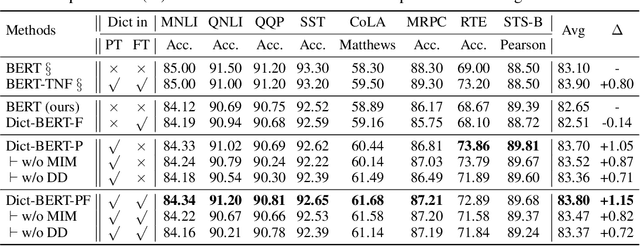
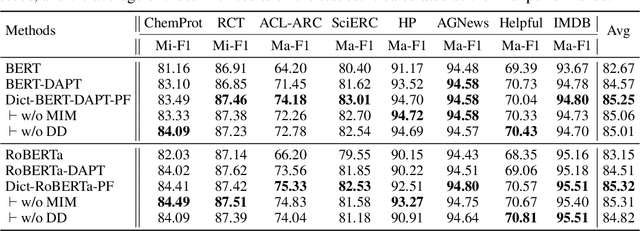
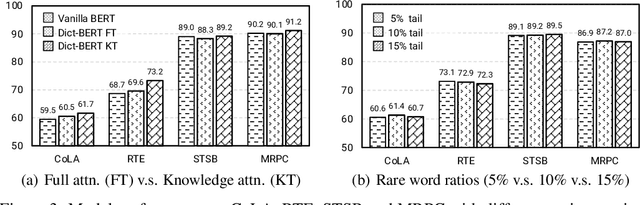
Pre-trained language models (PLMs) aim to learn universal language representations by conducting self-supervised training tasks on large-scale corpora. Since PLMs capture word semantics in different contexts, the quality of word representations highly depends on word frequency, which usually follows a heavy-tailed distributions in the pre-training corpus. Therefore, the embeddings of rare words on the tail are usually poorly optimized. In this work, we focus on enhancing language model pre-training by leveraging definitions of the rare words in dictionaries (e.g., Wiktionary). To incorporate a rare word definition as a part of input, we fetch its definition from the dictionary and append it to the end of the input text sequence. In addition to training with the masked language modeling objective, we propose two novel self-supervised pre-training tasks on word and sentence-level alignment between input text sequence and rare word definitions to enhance language modeling representation with dictionary. We evaluate the proposed Dict-BERT model on the language understanding benchmark GLUE and eight specialized domain benchmark datasets. Extensive experiments demonstrate that Dict-BERT can significantly improve the understanding of rare words and boost model performance on various NLP downstream tasks.
Large-scale Self-Supervised Speech Representation Learning for Automatic Speaker Verification
Oct 12, 2021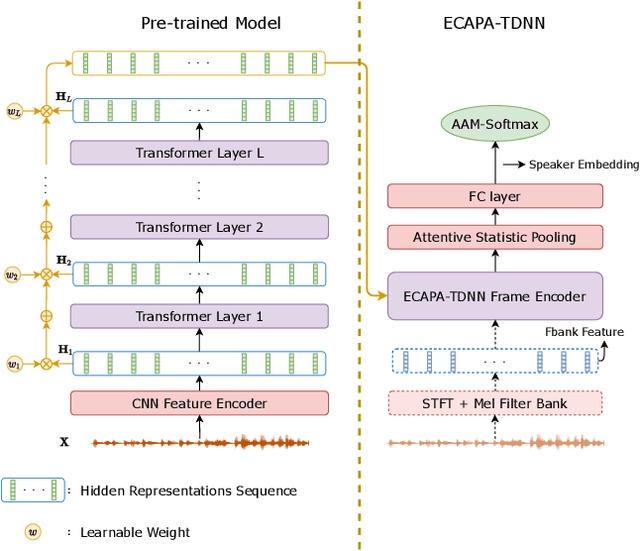


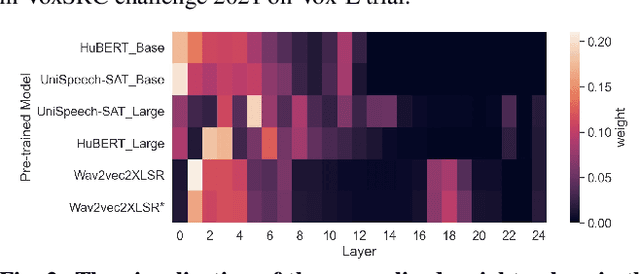
The speech representations learned from large-scale unlabeled data have shown better generalizability than those from supervised learning and thus attract a lot of interest to be applied for various downstream tasks. In this paper, we explore the limits of speech representations learned by different self-supervised objectives and datasets for automatic speaker verification (ASV), especially with a well-recognized SOTA ASV model, ECAPA-TDNN [1], as a downstream model. The representations from all hidden layers of the pre-trained model are firstly averaged with learnable weights and then fed into the ECAPA-TDNN as input features. The experimental results on Voxceleb dataset show that the weighted average representation is significantly superior to FBank, a conventional handcrafted feature for ASV. Our best single system achieves 0.564%, 0.561%, and 1.230% equal error rate (EER) on the three official trials of VoxCeleb1, separately. Accordingly, the ensemble system with three pre-trained models can further improve the EER to 0.431%, 0.507% and 1.081%. Among the three evaluation trials, our best system outperforms the winner system [2] of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC2021) on the VoxCeleb1-E trial.
KG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering
Oct 08, 2021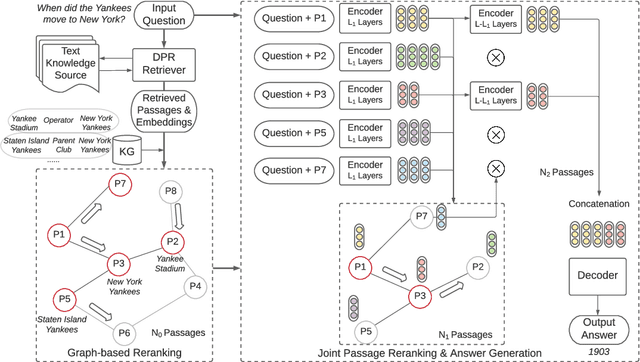
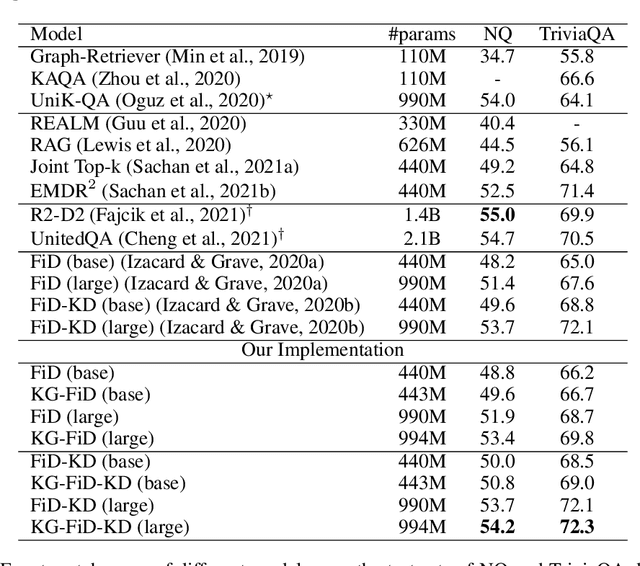
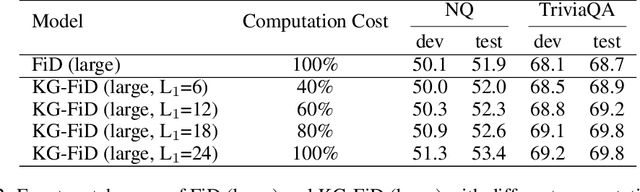
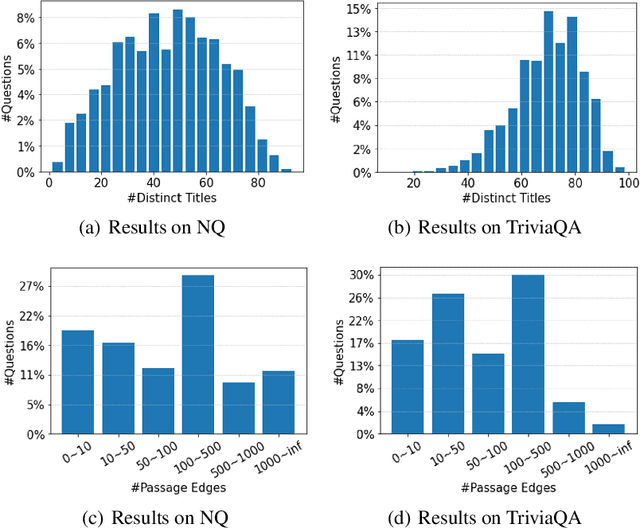
Current Open-Domain Question Answering (ODQA) model paradigm often contains a retrieving module and a reading module. Given an input question, the reading module predicts the answer from the relevant passages which are retrieved by the retriever. The recent proposed Fusion-in-Decoder (FiD), which is built on top of the pretrained generative model T5, achieves the state-of-the-art performance in the reading module. Although being effective, it remains constrained by inefficient attention on all retrieved passages which contain a lot of noise. In this work, we propose a novel method KG-FiD, which filters noisy passages by leveraging the structural relationship among the retrieved passages with a knowledge graph. We initiate the passage node embedding from the FiD encoder and then use graph neural network (GNN) to update the representation for reranking. To improve the efficiency, we build the GNN on top of the intermediate layer output of the FiD encoder and only pass a few top reranked passages into the higher layers of encoder and decoder for answer generation. We also apply the proposed GNN based reranking method to enhance the passage retrieval results in the retrieving module. Extensive experiments on common ODQA benchmark datasets (Natural Question and TriviaQA) demonstrate that KG-FiD can improve vanilla FiD by up to 1.5% on answer exact match score and achieve comparable performance with FiD with only 40% of computation cost.
DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization
Sep 06, 2021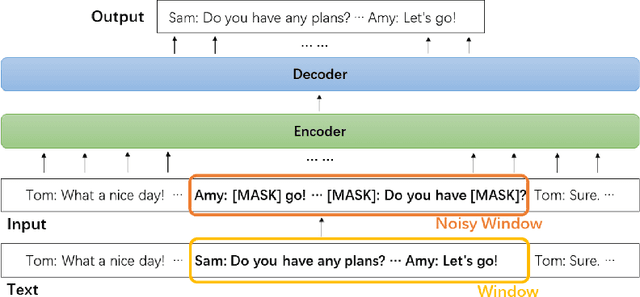

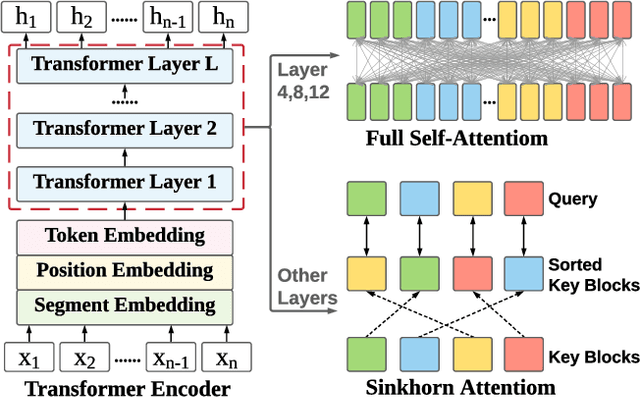
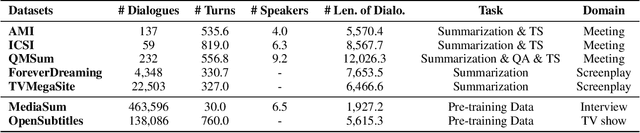
Dialogue is an essential part of human communication and cooperation. Existing research mainly focuses on short dialogue scenarios in a one-on-one fashion. However, multi-person interactions in the real world, such as meetings or interviews, are frequently over a few thousand words. There is still a lack of corresponding research and powerful tools to understand and process such long dialogues. Therefore, in this work, we present a pre-training framework for long dialogue understanding and summarization. Considering the nature of long conversations, we propose a window-based denoising approach for generative pre-training. For a dialogue, it corrupts a window of text with dialogue-inspired noise, and guides the model to reconstruct this window based on the content of the remaining conversation. Furthermore, to process longer input, we augment the model with sparse attention which is combined with conventional attention in a hybrid manner. We conduct extensive experiments on five datasets of long dialogues, covering tasks of dialogue summarization, abstractive question answering and topic segmentation. Experimentally, we show that our pre-trained model DialogLM significantly surpasses the state-of-the-art models across datasets and tasks.
Does Knowledge Help General NLU? An Empirical Study
Sep 01, 2021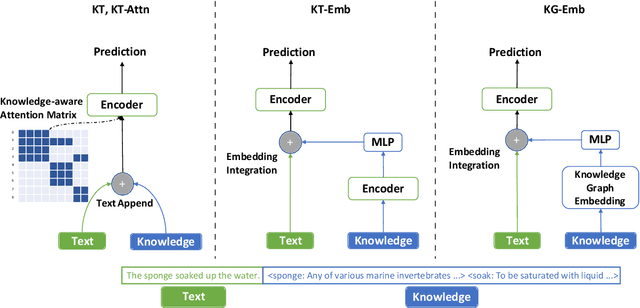

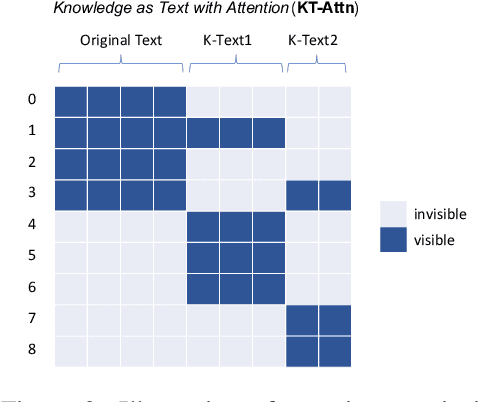
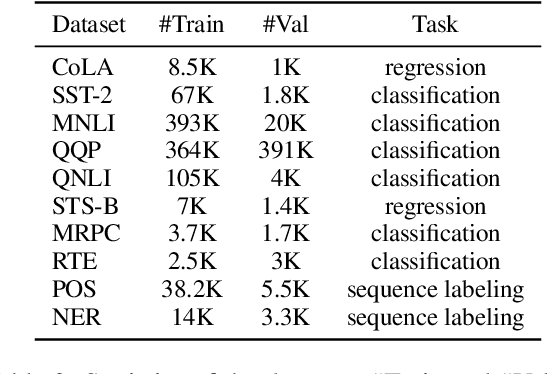
It is often observed in knowledge-centric tasks (e.g., common sense question and answering, relation classification) that the integration of external knowledge such as entity representation into language models can help provide useful information to boost the performance. However, it is still unclear whether this benefit can extend to general natural language understanding (NLU) tasks. In this work, we empirically investigated the contribution of external knowledge by measuring the end-to-end performance of language models with various knowledge integration methods. We find that the introduction of knowledge can significantly improve the results on certain tasks while having no adverse effects on other tasks. We then employ mutual information to reflect the difference brought by knowledge and a neural interpretation model to reveal how a language model utilizes external knowledge. Our study provides valuable insights and guidance for practitioners to equip NLP models with knowledge.
Want To Reduce Labeling Cost? GPT-3 Can Help
Aug 30, 2021
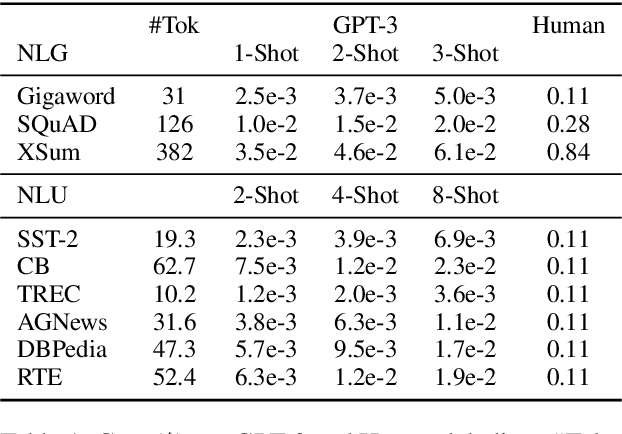
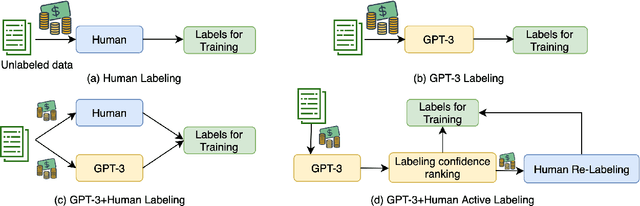
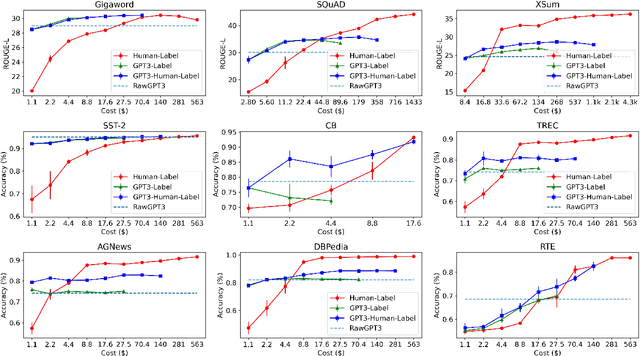
Data annotation is a time-consuming and labor-intensive process for many NLP tasks. Although there exist various methods to produce pseudo data labels, they are often task-specific and require a decent amount of labeled data to start with. Recently, the immense language model GPT-3 with 175 billion parameters has achieved tremendous improvement across many few-shot learning tasks. In this paper, we explore ways to leverage GPT-3 as a low-cost data labeler to train other models. We find that, to make the downstream model achieve the same performance on a variety of NLU and NLG tasks, it costs 50% to 96% less to use labels from GPT-3 than using labels from humans. Furthermore, we propose a novel framework of combining pseudo labels from GPT-3 with human labels, which leads to even better performance with limited labeling budget. These results present a cost-effective data labeling methodology that is generalizable to many practical applications.