 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering VLMs for Few-Shot Multimodal Time Series Classification via Tailored Agentic Reasoning
May 10, 2026In this paper, we propose the first VL$\underline{\textbf{M}}$ $\underline{\textbf{a}}$gentic $\underline{\textbf{r}}$easoning framework for few-$\underline{\textbf{s}}$hot multimodal $\underline{\textbf{T}}$ime $\underline{\textbf{S}}$eries $\underline{\textbf{C}}$lassification ($\textbf{MarsTSC}$), which introduces a self-evolving knowledge bank as a dynamic context iteratively refined via reflective agentic reasoning. The framework comprises three collaborative roles: i) Generator conducts reliable classification via reasoning; ii) Reflector diagnoses the root causes of reasoning errors to yield discriminative insights targeting the temporal features overlooked by Generator; iii) Modifier applies verified updates to the knowledge bank to prevent context collapse. We further introduce a test-time update strategy to enable cautious, continuous knowledge bank refinement to mitigate few-shot bias and distribution shift. Extensive experiments across 12 mainstream time series benchmarks demonstrate that $\textbf{MarsTSC}$ delivers substantial and consistent performance gains across 6 VLM backbones, outperforming both classical and foundation model-based time series baselines under few-shot conditions, while producing interpretable rationales that ground each classification decision in human-readable feature evidence.
WaveMoE: A Wavelet-Enhanced Mixture-of-Experts Foundation Model for Time Series Forecasting
Apr 12, 2026Time series foundation models (TSFMs) have recently achieved remarkable success in universal forecasting by leveraging large-scale pretraining on diverse time series data. Complementing this progress, incorporating frequency-domain information yields promising performance in enhancing the modeling of complex temporal patterns, such as periodicity and localized high-frequency dynamics, which are prevalent in real-world time series. To advance this direction, we propose a new perspective that integrates explicit frequency-domain representations into scalable foundation models, and introduce WaveMoE, a wavelet-enhanced mixture-of-experts foundation model for time series forecasting. WaveMoE adopts a dual-path architecture that jointly processes time series tokens and wavelet tokens aligned along a unified temporal axis, and coordinates them through a shared expert routing mechanism that enables consistent expert specialization while efficiently scaling model capacity. Preliminary experimental results on 16 diverse benchmark datasets indicate that WaveMoE has the potential to further improve forecasting performance by incorporating wavelet-domain corpora.
Time Series Reasoning via Process-Verifiable Thinking Data Synthesis and Scheduling for Tailored LLM Reasoning
Feb 08, 2026Time series is a pervasive data type across various application domains, rendering the reasonable solving of diverse time series tasks a long-standing goal. Recent advances in large language models (LLMs), especially their reasoning abilities unlocked through reinforcement learning (RL), have opened new opportunities for tackling tasks with long Chain-of-Thought (CoT) reasoning. However, leveraging LLM reasoning for time series remains in its infancy, hindered by the absence of carefully curated time series CoT data for training, limited data efficiency caused by underexplored data scheduling, and the lack of RL algorithms tailored for exploiting such time series CoT data. In this paper, we introduce VeriTime, a framework that tailors LLMs for time series reasoning through data synthesis, data scheduling, and RL training. First, we propose a data synthesis pipeline that constructs a TS-text multimodal dataset with process-verifiable annotations. Second, we design a data scheduling mechanism that arranges training samples according to a principled hierarchy of difficulty and task taxonomy. Third, we develop a two-stage reinforcement finetuning featuring fine-grained, multi-objective rewards that leverage verifiable process-level CoT data. Extensive experiments show that VeriTime substantially boosts LLM performance across diverse time series reasoning tasks. Notably, it enables compact 3B, 4B models to achieve reasoning capabilities on par with or exceeding those of larger proprietary LLMs.
Florence: A New Foundation Model for Computer Vision
Nov 22, 2021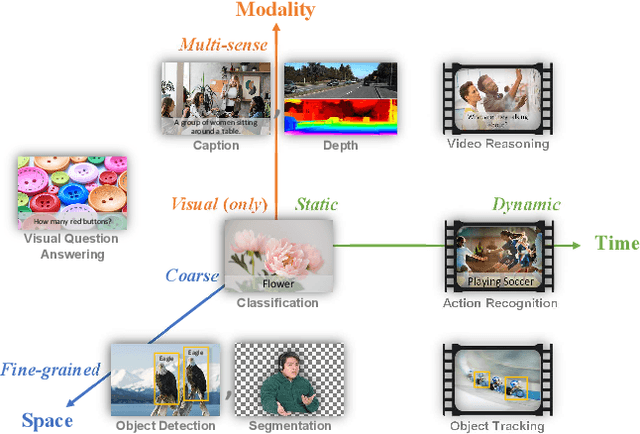
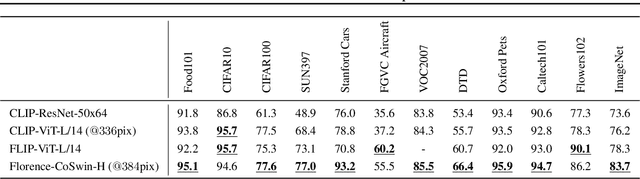
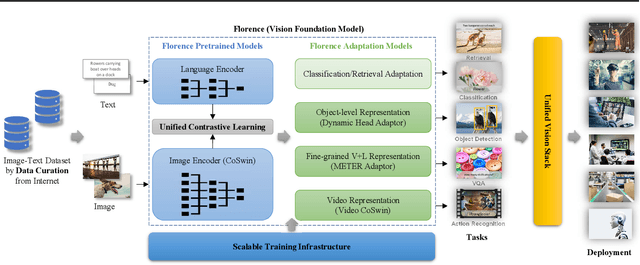
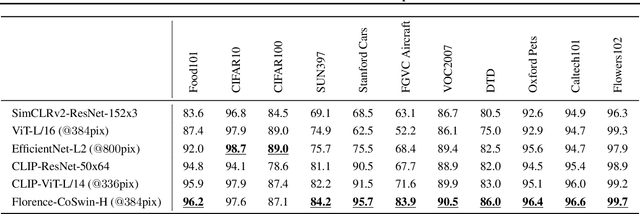
Automated visual understanding of our diverse and open world demands computer vision models to generalize well with minimal customization for specific tasks, similar to human vision. Computer vision foundation models, which are trained on diverse, large-scale dataset and can be adapted to a wide range of downstream tasks, are critical for this mission to solve real-world computer vision applications. While existing vision foundation models such as CLIP, ALIGN, and Wu Dao 2.0 focus mainly on mapping images and textual representations to a cross-modal shared representation, we introduce a new computer vision foundation model, Florence, to expand the representations from coarse (scene) to fine (object), from static (images) to dynamic (videos), and from RGB to multiple modalities (caption, depth). By incorporating universal visual-language representations from Web-scale image-text data, our Florence model can be easily adapted for various computer vision tasks, such as classification, retrieval, object detection, VQA, image caption, video retrieval and action recognition. Moreover, Florence demonstrates outstanding performance in many types of transfer learning: fully sampled fine-tuning, linear probing, few-shot transfer and zero-shot transfer for novel images and objects. All of these properties are critical for our vision foundation model to serve general purpose vision tasks. Florence achieves new state-of-the-art results in majority of 44 representative benchmarks, e.g., ImageNet-1K zero-shot classification with top-1 accuracy of 83.74 and the top-5 accuracy of 97.18, 62.4 mAP on COCO fine tuning, 80.36 on VQA, and 87.8 on Kinetics-600.