 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDermaVQA-DAS: Dermatology Assessment Schema (DAS) & Datasets for Closed-Ended Question Answering & Segmentation in Patient-Generated Dermatology Images
Dec 30, 2025Recent advances in dermatological image analysis have been driven by large-scale annotated datasets; however, most existing benchmarks focus on dermatoscopic images and lack patient-authored queries and clinical context, limiting their applicability to patient-centered care. To address this gap, we introduce DermaVQA-DAS, an extension of the DermaVQA dataset that supports two complementary tasks: closed-ended question answering (QA) and dermatological lesion segmentation. Central to this work is the Dermatology Assessment Schema (DAS), a novel expert-developed framework that systematically captures clinically meaningful dermatological features in a structured and standardized form. DAS comprises 36 high-level and 27 fine-grained assessment questions, with multiple-choice options in English and Chinese. Leveraging DAS, we provide expert-annotated datasets for both closed QA and segmentation and benchmark state-of-the-art multimodal models. For segmentation, we evaluate multiple prompting strategies and show that prompt design impacts performance: the default prompt achieves the best results under Mean-of-Max and Mean-of-Mean evaluation aggregation schemes, while an augmented prompt incorporating both patient query title and content yields the highest performance under majority-vote-based microscore evaluation, achieving a Jaccard index of 0.395 and a Dice score of 0.566 with BiomedParse. For closed-ended QA, overall performance is strong across models, with average accuracies ranging from 0.729 to 0.798; o3 achieves the best overall accuracy (0.798), closely followed by GPT-4.1 (0.796), while Gemini-1.5-Pro shows competitive performance within the Gemini family (0.783). We publicly release DermaVQA-DAS, the DAS schema, and evaluation protocols to support and accelerate future research in patient-centered dermatological vision-language modeling (https://osf.io/72rp3).
Generative Enhancement for 3D Medical Images
Mar 19, 2024



The limited availability of 3D medical image datasets, due to privacy concerns and high collection or annotation costs, poses significant challenges in the field of medical imaging. While a promising alternative is the use of synthesized medical data, there are few solutions for realistic 3D medical image synthesis due to difficulties in backbone design and fewer 3D training samples compared to 2D counterparts. In this paper, we propose GEM-3D, a novel generative approach to the synthesis of 3D medical images and the enhancement of existing datasets using conditional diffusion models. Our method begins with a 2D slice, noted as the informed slice to serve the patient prior, and propagates the generation process using a 3D segmentation mask. By decomposing the 3D medical images into masks and patient prior information, GEM-3D offers a flexible yet effective solution for generating versatile 3D images from existing datasets. GEM-3D can enable dataset enhancement by combining informed slice selection and generation at random positions, along with editable mask volumes to introduce large variations in diffusion sampling. Moreover, as the informed slice contains patient-wise information, GEM-3D can also facilitate counterfactual image synthesis and dataset-level de-enhancement with desired control. Experiments on brain MRI and abdomen CT images demonstrate that GEM-3D is capable of synthesizing high-quality 3D medical images with volumetric consistency, offering a straightforward solution for dataset enhancement during inference. The code is available at https://github.com/HKU-MedAI/GEM-3D.
RAD-DINO: Exploring Scalable Medical Image Encoders Beyond Text Supervision
Jan 19, 2024Language-supervised pre-training has proven to be a valuable method for extracting semantically meaningful features from images, serving as a foundational element in multimodal systems within the computer vision and medical imaging domains. However, resulting features are limited by the information contained within the text. This is particularly problematic in medical imaging, where radiologists' written findings focus on specific observations; a challenge compounded by the scarcity of paired imaging-text data due to concerns over leakage of personal health information. In this work, we fundamentally challenge the prevailing reliance on language supervision for learning general purpose biomedical imaging encoders. We introduce RAD-DINO, a biomedical image encoder pre-trained solely on unimodal biomedical imaging data that obtains similar or greater performance than state-of-the-art biomedical language supervised models on a diverse range of benchmarks. Specifically, the quality of learned representations is evaluated on standard imaging tasks (classification and semantic segmentation), and a vision-language alignment task (text report generation from images). To further demonstrate the drawback of language supervision, we show that features from RAD-DINO correlate with other medical records (e.g., sex or age) better than language-supervised models, which are generally not mentioned in radiology reports. Finally, we conduct a series of ablations determining the factors in RAD-DINO's performance; notably, we observe that RAD-DINO's downstream performance scales well with the quantity and diversity of training data, demonstrating that image-only supervision is a scalable approach for training a foundational biomedical image encoder.
Fully Authentic Visual Question Answering Dataset from Online Communities
Nov 27, 2023



Visual Question Answering (VQA) entails answering questions about images. We introduce the first VQA dataset in which all contents originate from an authentic use case. Sourced from online question answering community forums, we call it VQAonline. We then characterize our dataset and how it relates to eight other VQA datasets. Observing that answers in our dataset tend to be much longer (e.g., with a mean of 173 words) and thus incompatible with standard VQA evaluation metrics, we next analyze which of the six popular metrics for longer text evaluation align best with human judgments. We then use the best-suited metrics to evaluate six state-of-the-art vision and language foundation models on VQAonline and reveal where they struggle most. We will release the dataset soon to facilitate future extensions.
MAIRA-1: A specialised large multimodal model for radiology report generation
Nov 22, 2023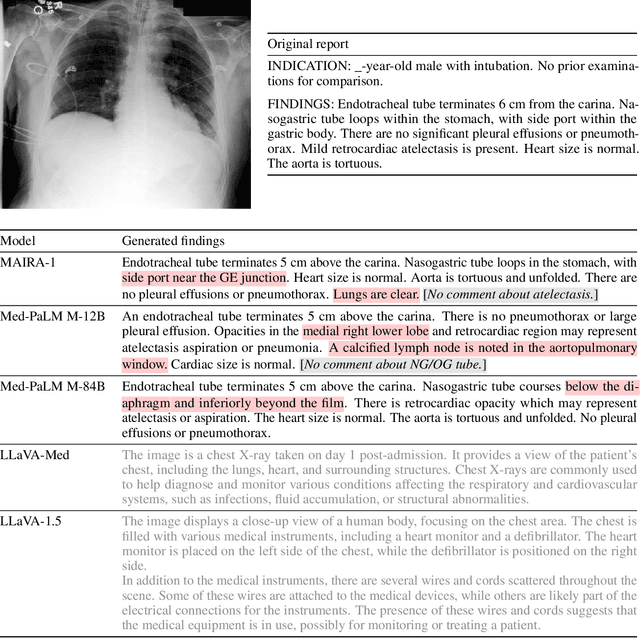



We present a radiology-specific multimodal model for the task for generating radiological reports from chest X-rays (CXRs). Our work builds on the idea that large language model(s) can be equipped with multimodal capabilities through alignment with pre-trained vision encoders. On natural images, this has been shown to allow multimodal models to gain image understanding and description capabilities. Our proposed model (MAIRA-1) leverages a CXR-specific image encoder in conjunction with a fine-tuned large language model based on Vicuna-7B, and text-based data augmentation, to produce reports with state-of-the-art quality. In particular, MAIRA-1 significantly improves on the radiologist-aligned RadCliQ metric and across all lexical metrics considered. Manual review of model outputs demonstrates promising fluency and accuracy of generated reports while uncovering failure modes not captured by existing evaluation practices. More information and resources can be found on the project website: https://aka.ms/maira.
Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond
Oct 31, 2023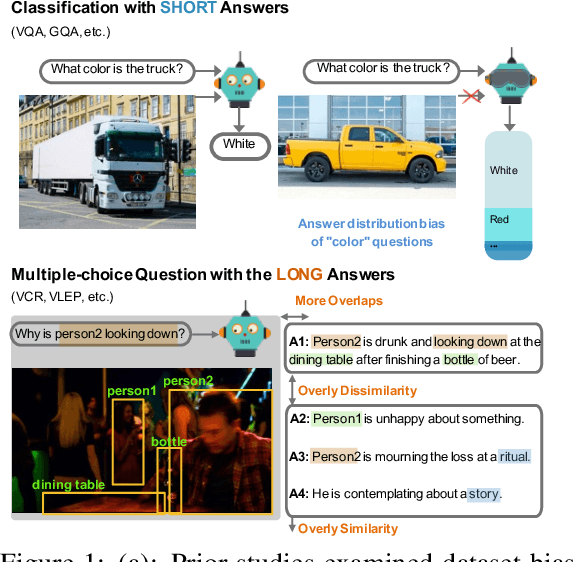
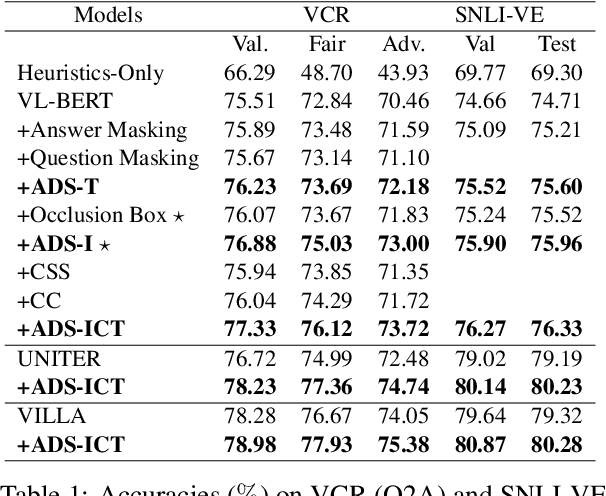


Vision-language (VL) understanding tasks evaluate models' comprehension of complex visual scenes through multiple-choice questions. However, we have identified two dataset biases that models can exploit as shortcuts to resolve various VL tasks correctly without proper understanding. The first type of dataset bias is \emph{Unbalanced Matching} bias, where the correct answer overlaps the question and image more than the incorrect answers. The second type of dataset bias is \emph{Distractor Similarity} bias, where incorrect answers are overly dissimilar to the correct answer but significantly similar to other incorrect answers within the same sample. To address these dataset biases, we first propose Adversarial Data Synthesis (ADS) to generate synthetic training and debiased evaluation data. We then introduce Intra-sample Counterfactual Training (ICT) to assist models in utilizing the synthesized training data, particularly the counterfactual data, via focusing on intra-sample differentiation. Extensive experiments demonstrate the effectiveness of ADS and ICT in consistently improving model performance across different benchmarks, even in domain-shifted scenarios.
* EMNLP 2023
UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding
Jul 03, 2023



Vision-language tasks, such as VQA, SNLI-VE, and VCR are challenging because they require the model's reasoning ability to understand the semantics of the visual world and natural language. Supervised methods working for vision-language tasks have been well-studied. However, solving these tasks in a zero-shot setting is less explored. Since Contrastive Language-Image Pre-training (CLIP) has shown remarkable zero-shot performance on image-text matching, previous works utilized its strong zero-shot ability by converting vision-language tasks into an image-text matching problem, and they mainly consider global-level matching (e.g., the whole image or sentence). However, we find visual and textual fine-grained information, e.g., keywords in the sentence and objects in the image, can be fairly informative for semantics understanding. Inspired by this, we propose a unified framework to take advantage of the fine-grained information for zero-shot vision-language learning, covering multiple tasks such as VQA, SNLI-VE, and VCR. Our experiments show that our framework outperforms former zero-shot methods on VQA and achieves substantial improvement on SNLI-VE and VCR. Furthermore, our ablation studies confirm the effectiveness and generalizability of our proposed method. Code will be available at https://github.com/ThreeSR/UniFine
i-Code V2: An Autoregressive Generation Framework over Vision, Language, and Speech Data
May 21, 2023



The convergence of text, visual, and audio data is a key step towards human-like artificial intelligence, however the current Vision-Language-Speech landscape is dominated by encoder-only models which lack generative abilities. We propose closing this gap with i-Code V2, the first model capable of generating natural language from any combination of Vision, Language, and Speech data. i-Code V2 is an integrative system that leverages state-of-the-art single-modality encoders, combining their outputs with a new modality-fusing encoder in order to flexibly project combinations of modalities into a shared representational space. Next, language tokens are generated from these representations via an autoregressive decoder. The whole framework is pretrained end-to-end on a large collection of dual- and single-modality datasets using a novel text completion objective that can be generalized across arbitrary combinations of modalities. i-Code V2 matches or outperforms state-of-the-art single- and dual-modality baselines on 7 multimodal tasks, demonstrating the power of generative multimodal pretraining across a diversity of tasks and signals.
Streaming Video Model
Mar 30, 2023



Video understanding tasks have traditionally been modeled by two separate architectures, specially tailored for two distinct tasks. Sequence-based video tasks, such as action recognition, use a video backbone to directly extract spatiotemporal features, while frame-based video tasks, such as multiple object tracking (MOT), rely on single fixed-image backbone to extract spatial features. In contrast, we propose to unify video understanding tasks into one novel streaming video architecture, referred to as Streaming Vision Transformer (S-ViT). S-ViT first produces frame-level features with a memory-enabled temporally-aware spatial encoder to serve the frame-based video tasks. Then the frame features are input into a task-related temporal decoder to obtain spatiotemporal features for sequence-based tasks. The efficiency and efficacy of S-ViT is demonstrated by the state-of-the-art accuracy in the sequence-based action recognition task and the competitive advantage over conventional architecture in the frame-based MOT task. We believe that the concept of streaming video model and the implementation of S-ViT are solid steps towards a unified deep learning architecture for video understanding. Code will be available at https://github.com/yuzhms/Streaming-Video-Model.
Learning Visual Representation from Modality-Shared Contrastive Language-Image Pre-training
Jul 26, 2022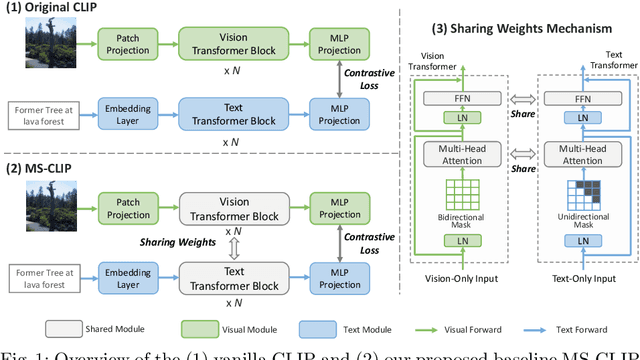
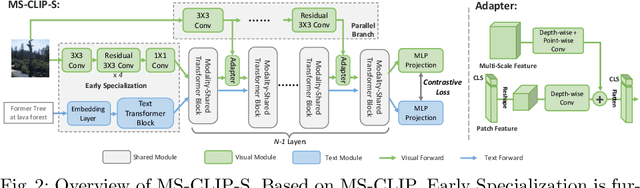
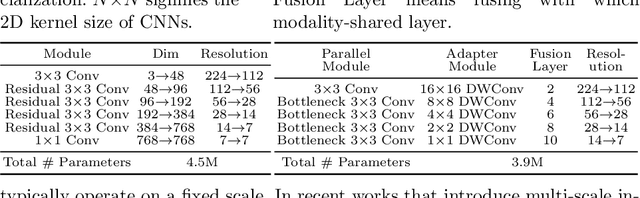
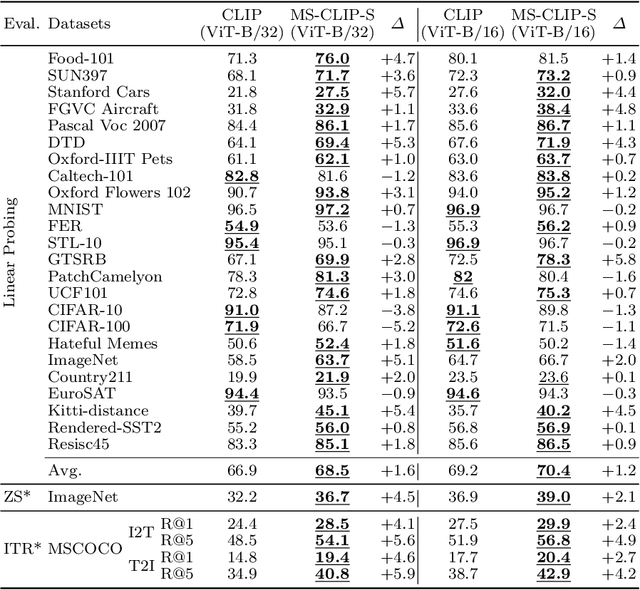
Large-scale multi-modal contrastive pre-training has demonstrated great utility to learn transferable features for a range of downstream tasks by mapping multiple modalities into a shared embedding space. Typically, this has employed separate encoders for each modality. However, recent work suggests that transformers can support learning across multiple modalities and allow knowledge sharing. Inspired by this, we investigate a variety of Modality-Shared Contrastive Language-Image Pre-training (MS-CLIP) frameworks. More specifically, we question how many parameters of a transformer model can be shared across modalities during contrastive pre-training, and rigorously examine architectural design choices that position the proportion of parameters shared along a spectrum. In studied conditions, we observe that a mostly unified encoder for vision and language signals outperforms all other variations that separate more parameters. Additionally, we find that light-weight modality-specific parallel modules further improve performance. Experimental results show that the proposed MS-CLIP approach outperforms vanilla CLIP by up to 13\% relative in zero-shot ImageNet classification (pre-trained on YFCC-100M), while simultaneously supporting a reduction of parameters. In addition, our approach outperforms vanilla CLIP by 1.6 points in linear probing on a collection of 24 downstream vision tasks. Furthermore, we discover that sharing parameters leads to semantic concepts from different modalities being encoded more closely in the embedding space, facilitating the transferring of common semantic structure (e.g., attention patterns) from language to vision. Code is available at \href{https://github.com/Hxyou/MSCLIP}{URL}.