 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM can Read Spectrogram: Encoder-free Speech-Language Modeling
Jun 08, 2026Recent speech-aware large language models (Speech-LLMs) rely on a pre-trained speech encoder to convert audio into semantic-rich representations consumable by LLM. In this work, instead, we explore: can an LLM learn to read Mel spectrogram directly without a dedicated speech encoder? We propose Mel-LLM, an encoder-free Speech-LLM that feeds lightly pre-processed Mel spectrogram patches directly into the LLM through a linear projection, allowing the LLM to learn speech-text alignment purely through its own parameters. We conduct extensive experiments on both automatic speech recognition (ASR) and text-to-speech (TTS) tasks. For ASR, we evaluate on the OpenASR leaderboard public sets and production-level scaling experiments, demonstrating that the encoder-free solution achieves competitive performance with only limited degradation compared to encoder-initialized counterparts. We find that when data is limited, initialization from a multimodal checkpoint (Phi-4-MM) is crucial for maintaining performance. We also present ablation studies revealing which LLM layers are less relevant to speech encoding. For TTS, we show preliminary results with a next-token VAE approach. While TTS performance is not yet optimal, these results establish the feasibility of a fully unified encoder-free architecture for autoregressive speech-text modeling.
Next Tokens Denoising for Speech Synthesis
Jul 30, 2025While diffusion and autoregressive (AR) models have significantly advanced generative modeling, they each present distinct limitations. AR models, which rely on causal attention, cannot exploit future context and suffer from slow generation speeds. Conversely, diffusion models struggle with key-value (KV) caching. To overcome these challenges, we introduce Dragon-FM, a novel text-to-speech (TTS) design that unifies AR and flow-matching. This model processes 48 kHz audio codec tokens in chunks at a compact 12.5 tokens per second rate. This design enables AR modeling across chunks, ensuring global coherence, while parallel flow-matching within chunks facilitates fast iterative denoising. Consequently, the proposed model can utilize KV-cache across chunks and incorporate future context within each chunk. Furthermore, it bridges continuous and discrete feature modeling, demonstrating that continuous AR flow-matching can predict discrete tokens with finite scalar quantizers. This efficient codec and fast chunk-autoregressive architecture also makes the proposed model particularly effective for generating extended content. Experiment for demos of our work} on podcast datasets demonstrate its capability to efficiently generate high-quality zero-shot podcasts.
Audio-Aware Large Language Models as Judges for Speaking Styles
Jun 06, 2025Audio-aware large language models (ALLMs) can understand the textual and non-textual information in the audio input. In this paper, we explore using ALLMs as an automatic judge to assess the speaking styles of speeches. We use ALLM judges to evaluate the speeches generated by SLMs on two tasks: voice style instruction following and role-playing. The speaking style we consider includes emotion, volume, speaking pace, word emphasis, pitch control, and non-verbal elements. We use four spoken language models (SLMs) to complete the two tasks and use humans and ALLMs to judge the SLMs' responses. We compare two ALLM judges, GPT-4o-audio and Gemini-2.5-pro, with human evaluation results and show that the agreement between Gemini and human judges is comparable to the agreement between human evaluators. These promising results show that ALLMs can be used as a judge to evaluate SLMs. Our results also reveal that current SLMs, even GPT-4o-audio, still have room for improvement in controlling the speaking style and generating natural dialogues.
Phi-Omni-ST: A multimodal language model for direct speech-to-speech translation
Jun 04, 2025Speech-aware language models (LMs) have demonstrated capabilities in understanding spoken language while generating text-based responses. However, enabling them to produce speech output efficiently and effectively remains a challenge. In this paper, we present Phi-Omni-ST, a multimodal LM for direct speech-to-speech translation (ST), built on the open-source Phi-4 MM model. Phi-Omni-ST extends its predecessor by generating translated speech using an audio transformer head that predicts audio tokens with a delay relative to text tokens, followed by a streaming vocoder for waveform synthesis. Our experimental results on the CVSS-C dataset demonstrate Phi-Omni-ST's superior performance, significantly surpassing existing baseline models trained on the same dataset. Furthermore, when we scale up the training data and the model size, Phi-Omni-ST reaches on-par performance with the current SOTA model.
Towards Efficient Speech-Text Jointly Decoding within One Speech Language Model
Jun 04, 2025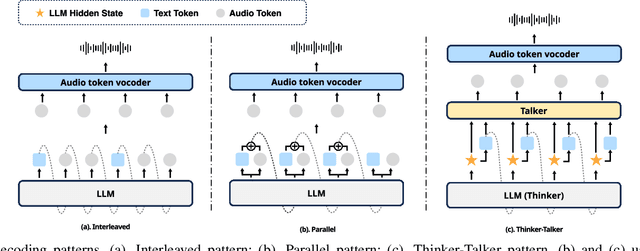
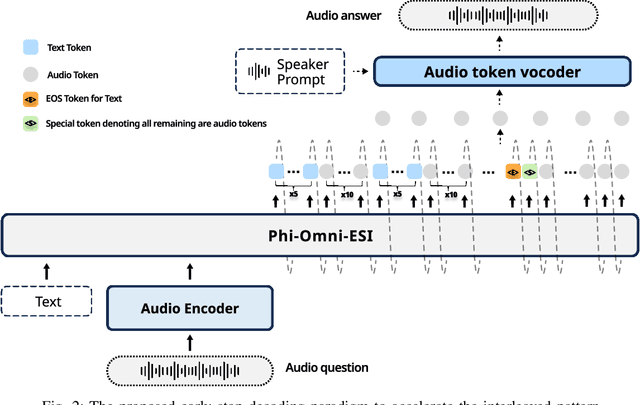


Speech language models (Speech LMs) enable end-to-end speech-text modelling within a single model, offering a promising direction for spoken dialogue systems. The choice of speech-text jointly decoding paradigm plays a critical role in performance, efficiency, and alignment quality. In this work, we systematically compare representative joint speech-text decoding strategies-including the interleaved, and parallel generation paradigms-under a controlled experimental setup using the same base language model, speech tokenizer and training data. Our results show that the interleaved approach achieves the best alignment. However it suffers from slow inference due to long token sequence length. To address this, we propose a novel early-stop interleaved (ESI) pattern that not only significantly accelerates decoding but also yields slightly better performance. Additionally, we curate high-quality question answering (QA) datasets to further improve speech QA performance.
Isochrony-Controlled Speech-to-Text Translation: A study on translating from Sino-Tibetan to Indo-European Languages
Nov 11, 2024



End-to-end speech translation (ST), which translates source language speech directly into target language text, has garnered significant attention in recent years. Many ST applications require strict length control to ensure that the translation duration matches the length of the source audio, including both speech and pause segments. Previous methods often controlled the number of words or characters generated by the Machine Translation model to approximate the source sentence's length without considering the isochrony of pauses and speech segments, as duration can vary between languages. To address this, we present improvements to the duration alignment component of our sequence-to-sequence ST model. Our method controls translation length by predicting the duration of speech and pauses in conjunction with the translation process. This is achieved by providing timing information to the decoder, ensuring it tracks the remaining duration for speech and pauses while generating the translation. The evaluation on the Zh-En test set of CoVoST 2, demonstrates that the proposed Isochrony-Controlled ST achieves 0.92 speech overlap and 8.9 BLEU, which has only a 1.4 BLEU drop compared to the ST baseline.
Investigating Neural Audio Codecs for Speech Language Model-Based Speech Generation
Sep 06, 2024



Neural audio codec tokens serve as the fundamental building blocks for speech language model (SLM)-based speech generation. However, there is no systematic understanding on how the codec system affects the speech generation performance of the SLM. In this work, we examine codec tokens within SLM framework for speech generation to provide insights for effective codec design. We retrain existing high-performing neural codec models on the same data set and loss functions to compare their performance in a uniform setting. We integrate codec tokens into two SLM systems: masked-based parallel speech generation system and an auto-regressive (AR) plus non-auto-regressive (NAR) model-based system. Our findings indicate that better speech reconstruction in codec systems does not guarantee improved speech generation in SLM. A high-quality codec decoder is crucial for natural speech production in SLM, while speech intelligibility depends more on quantization mechanism.
VALL-E 2: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers
Jun 08, 2024



This paper introduces VALL-E 2, the latest advancement in neural codec language models that marks a milestone in zero-shot text-to-speech synthesis (TTS), achieving human parity for the first time. Based on its predecessor, VALL-E, the new iteration introduces two significant enhancements: Repetition Aware Sampling refines the original nucleus sampling process by accounting for token repetition in the decoding history. It not only stabilizes the decoding but also circumvents the infinite loop issue. Grouped Code Modeling organizes codec codes into groups to effectively shorten the sequence length, which not only boosts inference speed but also addresses the challenges of long sequence modeling. Our experiments on the LibriSpeech and VCTK datasets show that VALL-E 2 surpasses previous systems in speech robustness, naturalness, and speaker similarity. It is the first of its kind to reach human parity on these benchmarks. Moreover, VALL-E 2 consistently synthesizes high-quality speech, even for sentences that are traditionally challenging due to their complexity or repetitive phrases. The advantages of this work could contribute to valuable endeavors, such as generating speech for individuals with aphasia or people with amyotrophic lateral sclerosis. Demos of VALL-E 2 will be posted to https://aka.ms/valle2.
TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation
May 28, 2024There is a rising interest and trend in research towards directly translating speech from one language to another, known as end-to-end speech-to-speech translation. However, most end-to-end models struggle to outperform cascade models, i.e., a pipeline framework by concatenating speech recognition, machine translation and text-to-speech models. The primary challenges stem from the inherent complexities involved in direct translation tasks and the scarcity of data. In this study, we introduce a novel model framework TransVIP that leverages diverse datasets in a cascade fashion yet facilitates end-to-end inference through joint probability. Furthermore, we propose two separated encoders to preserve the speaker's voice characteristics and isochrony from the source speech during the translation process, making it highly suitable for scenarios such as video dubbing. Our experiments on the French-English language pair demonstrate that our model outperforms the current state-of-the-art speech-to-speech translation model.
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Apr 10, 2024



Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.