 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiva-DiT: Residual-Based Differentiable Top-$k$ Selection for Efficient Diffusion Transformers
Feb 05, 2026Diffusion Transformers (DiTs) incur prohibitive computational costs due to the quadratic scaling of self-attention. Existing pruning methods fail to simultaneously satisfy differentiability, efficiency, and the strict static budgets required for hardware overhead. To address this, we propose Shiva-DiT, which effectively reconciles these conflicting requirements via Residual-Based Differentiable Top-$k$ Selection. By leveraging a residual-aware straight-through estimator, our method enforces deterministic token counts for static compilation while preserving end-to-end learnability through residual gradient estimation. Furthermore, we introduce a Context-Aware Router and Adaptive Ratio Policy to autonomously learn an adaptive pruning schedule. Experiments on mainstream models, including SD3.5, demonstrate that Shiva-DiT establishes a new Pareto frontier, achieving a 1.54$\times$ wall-clock speedup with superior fidelity compared to existing baselines, effectively eliminating ragged tensor overheads.
Factored Causal Representation Learning for Robust Reward Modeling in RLHF
Jan 29, 2026A reliable reward model is essential for aligning large language models with human preferences through reinforcement learning from human feedback. However, standard reward models are susceptible to spurious features that are not causally related to human labels. This can lead to reward hacking, where high predicted reward does not translate into better behavior. In this work, we address this problem from a causal perspective by proposing a factored representation learning framework that decomposes the model's contextual embedding into (1) causal factors that are sufficient for reward prediction and (2) non-causal factors that capture reward-irrelevant attributes such as length or sycophantic bias. The reward head is then constrained to depend only on the causal component. In addition, we introduce an adversarial head trained to predict reward from the non-causal factors, while applying gradient reversal to discourage them from encoding reward-relevant information. Experiments on both mathematical and dialogue tasks demonstrate that our method learns more robust reward models and consistently improves downstream RLHF performance over state-of-the-art baselines. Analyses on length and sycophantic bias further validate the effectiveness of our method in mitigating reward hacking behaviors.
Logics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
RollArt: Scaling Agentic RL Training via Disaggregated Infrastructure
Dec 27, 2025Agentic Reinforcement Learning (RL) enables Large Language Models (LLMs) to perform autonomous decision-making and long-term planning. Unlike standard LLM post-training, agentic RL workloads are highly heterogeneous, combining compute-intensive prefill phases, bandwidth-bound decoding, and stateful, CPU-heavy environment simulations. We argue that efficient agentic RL training requires disaggregated infrastructure to leverage specialized, best-fit hardware. However, naive disaggregation introduces substantial synchronization overhead and resource underutilization due to the complex dependencies between stages. We present RollArc, a distributed system designed to maximize throughput for multi-task agentic RL on disaggregated infrastructure. RollArc is built on three core principles: (1) hardware-affinity workload mapping, which routes compute-bound and bandwidth-bound tasks to bestfit GPU devices, (2) fine-grained asynchrony, which manages execution at the trajectory level to mitigate resource bubbles, and (3) statefulness-aware computation, which offloads stateless components (e.g., reward models) to serverless infrastructure for elastic scaling. Our results demonstrate that RollArc effectively improves training throughput and achieves 1.35-2.05\(\times\) end-to-end training time reduction compared to monolithic and synchronous baselines. We also evaluate RollArc by training a hundreds-of-billions-parameter MoE model for Qoder product on an Alibaba cluster with more than 3,000 GPUs, further demonstrating RollArc scalability and robustness. The code is available at https://github.com/alibaba/ROLL.
Reliable and Private Utility Signaling for Data Markets
Nov 11, 2025The explosive growth of data has highlighted its critical role in driving economic growth through data marketplaces, which enable extensive data sharing and access to high-quality datasets. To support effective trading, signaling mechanisms provide participants with information about data products before transactions, enabling informed decisions and facilitating trading. However, due to the inherent free-duplication nature of data, commonly practiced signaling methods face a dilemma between privacy and reliability, undermining the effectiveness of signals in guiding decision-making. To address this, this paper explores the benefits and develops a non-TCP-based construction for a desirable signaling mechanism that simultaneously ensures privacy and reliability. We begin by formally defining the desirable utility signaling mechanism and proving its ability to prevent suboptimal decisions for both participants and facilitate informed data trading. To design a protocol to realize its functionality, we propose leveraging maliciously secure multi-party computation (MPC) to ensure the privacy and robustness of signal computation and introduce an MPC-based hash verification scheme to ensure input reliability. In multi-seller scenarios requiring fair data valuation, we further explore the design and optimization of the MPC-based KNN-Shapley method with improved efficiency. Rigorous experiments demonstrate the efficiency and practicality of our approach.
DEPTH: Hallucination-Free Relation Extraction via Dependency-Aware Sentence Simplification and Two-tiered Hierarchical Refinement
Aug 20, 2025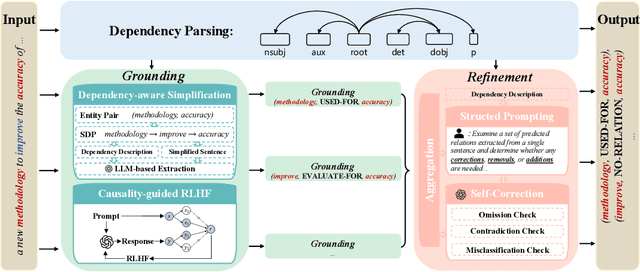

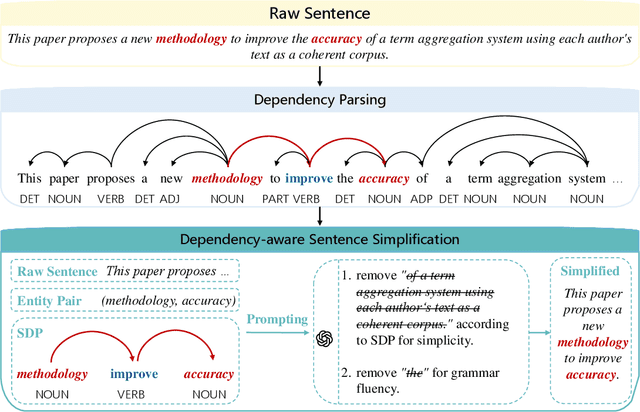

Relation extraction enables the construction of structured knowledge for many downstream applications. While large language models (LLMs) have shown great promise in this domain, most existing methods concentrate on relation classification, which predicts the semantic relation type between a related entity pair. However, we observe that LLMs often struggle to reliably determine whether a relation exists, especially in cases involving complex sentence structures or intricate semantics, which leads to spurious predictions. Such hallucinations can introduce noisy edges in knowledge graphs, compromising the integrity of structured knowledge and downstream reliability. To address these challenges, we propose DEPTH, a framework that integrates Dependency-aware sEntence simPlification and Two-tiered Hierarchical refinement into the relation extraction pipeline. Given a sentence and its candidate entity pairs, DEPTH operates in two stages: (1) the Grounding module extracts relations for each pair by leveraging their shortest dependency path, distilling the sentence into a minimal yet coherent relational context that reduces syntactic noise while preserving key semantics; (2) the Refinement module aggregates all local predictions and revises them based on a holistic understanding of the sentence, correcting omissions and inconsistencies. We further introduce a causality-driven reward model that mitigates reward hacking by disentangling spurious correlations, enabling robust fine-tuning via reinforcement learning with human feedback. Experiments on six benchmarks demonstrate that DEPTH reduces the average hallucination rate to 7.0\% while achieving a 17.2\% improvement in average F1 score over state-of-the-art baselines.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
InstGenIE: Generative Image Editing Made Efficient with Mask-aware Caching and Scheduling
May 27, 2025



Generative image editing using diffusion models has become a prevalent application in today's AI cloud services. In production environments, image editing typically involves a mask that specifies the regions of an image template to be edited. The use of masks provides direct control over the editing process and introduces sparsity in the model inference. In this paper, we present InstGenIE, a system that efficiently serves image editing requests. The key insight behind InstGenIE is that image editing only modifies the masked regions of image templates while preserving the original content in the unmasked areas. Driven by this insight, InstGenIE judiciously skips redundant computations associated with the unmasked areas by reusing cached intermediate activations from previous inferences. To mitigate the high cache loading overhead, InstGenIE employs a bubble-free pipeline scheme that overlaps computation with cache loading. Additionally, to reduce queuing latency in online serving while improving the GPU utilization, InstGenIE proposes a novel continuous batching strategy for diffusion model serving, allowing newly arrived requests to join the running batch in just one step of denoising computation, without waiting for the entire batch to complete. As heterogeneous masks induce imbalanced loads, InstGenIE also develops a load balancing strategy that takes into account the loads of both computation and cache loading. Collectively, InstGenIE outperforms state-of-the-art diffusion serving systems for image editing, achieving up to 3x higher throughput and reducing average request latency by up to 14.7x while ensuring image quality.
DDK: Distilling Domain Knowledge for Efficient Large Language Models
Jul 23, 2024



Despite the advanced intelligence abilities of large language models (LLMs) in various applications, they still face significant computational and storage demands. Knowledge Distillation (KD) has emerged as an effective strategy to improve the performance of a smaller LLM (i.e., the student model) by transferring knowledge from a high-performing LLM (i.e., the teacher model). Prevailing techniques in LLM distillation typically use a black-box model API to generate high-quality pretrained and aligned datasets, or utilize white-box distillation by altering the loss function to better transfer knowledge from the teacher LLM. However, these methods ignore the knowledge differences between the student and teacher LLMs across domains. This results in excessive focus on domains with minimal performance gaps and insufficient attention to domains with large gaps, reducing overall performance. In this paper, we introduce a new LLM distillation framework called DDK, which dynamically adjusts the composition of the distillation dataset in a smooth manner according to the domain performance differences between the teacher and student models, making the distillation process more stable and effective. Extensive evaluations show that DDK significantly improves the performance of student models, outperforming both continuously pretrained baselines and existing knowledge distillation methods by a large margin.