 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeTracer: Towards Traceable Agent States
Apr 14, 2026Code agents are advancing rapidly, but debugging them is becoming increasingly difficult. As frameworks orchestrate parallel tool calls and multi-stage workflows over complex tasks, making the agent's state transitions and error propagation hard to observe. In these runs, an early misstep can trap the agent in unproductive loops or even cascade into fundamental errors, forming hidden error chains that make it hard to tell when the agent goes off track and why. Existing agent tracing analyses either focus on simple interaction or rely on small-scale manual inspection, which limits their scalability and usefulness for real coding workflows. We present CodeTracer, a tracing architecture that parses heterogeneous run artifacts through evolving extractors, reconstructs the full state transition history as a hierarchical trace tree with persistent memory, and performs failure onset localization to pinpoint the failure origin and its downstream chain. To enable systematic evaluation, we construct CodeTraceBench from a large collection of executed trajectories generated by four widely used code agent frameworks on diverse code tasks (e.g., bug fixing, refactoring, and terminal interaction), with supervision at both the stage and step levels for failure localization. Experiments show that CodeTracer substantially outperforms direct prompting and lightweight baselines, and that replaying its diagnostic signals consistently recovers originally failed runs under matched budgets. Our code and data are publicly available.
Long-form RewardBench: Evaluating Reward Models for Long-form Generation
Mar 13, 2026The widespread adoption of reinforcement learning-based alignment highlights the growing importance of reward models. Various benchmarks have been built to evaluate reward models in various domains and scenarios. However, a significant gap remains in assessing reward models for long-form generation, despite its critical role in real-world applications. To bridge this, we introduce Long-form RewardBench, the first reward modeling testbed specifically designed for long-form generation. Our benchmark encompasses five key subtasks: QA, RAG, Chat, Writing, and Reasoning. We collected instruction and preference data through a meticulously designed multi-stage data collection process, and conducted extensive experiments on 20+ mainstream reward models, including both classifiers and generative models. Our findings reveal that current models still lack long-form reward modeling capabilities. Furthermore, we designed a novel Long-form Needle-in-a-Haystack Test, which revealed a correlation between reward modeling performance and the error's position within a response, as well as the overall response length, with distinct characteristics observed between classification and generative models. Finally, we demonstrate that classifiers exhibit better generalizability compared to generative models trained on the same data. As the first benchmark for long-form reward modeling, this work aims to offer a robust platform for visualizing progress in this crucial area.
CE-RM: A Pointwise Generative Reward Model Optimized via Two-Stage Rollout and Unified Criteria
Jan 28, 2026Automatic evaluation is crucial yet challenging for open-ended natural language generation, especially when rule-based metrics are infeasible. Compared with traditional methods, the recent LLM-as-a-Judge paradigms enable better and more flexible evaluation, and show promise as generative reward models for reinforcement learning. However, prior work has revealed a notable gap between their seemingly impressive benchmark performance and actual effectiveness in RL practice. We attribute this issue to some limitations in existing studies, including the dominance of pairwise evaluation and inadequate optimization of evaluation criteria. Therefore, we propose CE-RM-4B, a pointwise generative reward model trained with a dedicated two-stage rollout method, and adopting unified query-based criteria. Using only about 5.7K high-quality data curated from the open-source preference dataset, our CE-RM-4B achieves superior performance on diverse reward model benchmarks, especially in Best-of-N scenarios, and delivers more effective improvements in downstream RL practice.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Asymmetric Proximal Policy Optimization: mini-critics boost LLM reasoning
Oct 02, 2025Most recent RL for LLMs (RL4LLM) methods avoid explicit critics, replacing them with average advantage baselines. This shift is largely pragmatic: conventional value functions are computationally expensive to train at LLM scale and often fail under sparse rewards and long reasoning horizons. We revisit this bottleneck from an architectural perspective and introduce Asymmetric Proximal Policy Optimization (AsyPPO), a simple and scalable framework that restores the critics role while remaining efficient in large-model settings. AsyPPO employs a set of lightweight mini-critics, each trained on disjoint prompt shards. This design encourages diversity while preserving calibration, reducing value-estimation bias. Beyond robust estimation, AsyPPO leverages inter-critic uncertainty to refine the policy update: (i) masking advantages in states where critics agree and gradients add little learning signal, and (ii) filtering high-divergence states from entropy regularization, suppressing spurious exploration. After training on open-source data with only 5,000 samples, AsyPPO consistently improves learning stability and performance across multiple benchmarks over strong baselines, such as GRPO, achieving performance gains of more than six percent on Qwen3-4b-Base and about three percent on Qwen3-8b-Base and Qwen3-14b-Base over classic PPO, without additional tricks. These results highlight the importance of architectural innovations for scalable, efficient algorithms.
Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning
Aug 11, 2025Reinforcement learning for LLM reasoning has rapidly emerged as a prominent research area, marked by a significant surge in related studies on both algorithmic innovations and practical applications. Despite this progress, several critical challenges remain, including the absence of standardized guidelines for employing RL techniques and a fragmented understanding of their underlying mechanisms. Additionally, inconsistent experimental settings, variations in training data, and differences in model initialization have led to conflicting conclusions, obscuring the key characteristics of these techniques and creating confusion among practitioners when selecting appropriate techniques. This paper systematically reviews widely adopted RL techniques through rigorous reproductions and isolated evaluations within a unified open-source framework. We analyze the internal mechanisms, applicable scenarios, and core principles of each technique through fine-grained experiments, including datasets of varying difficulty, model sizes, and architectures. Based on these insights, we present clear guidelines for selecting RL techniques tailored to specific setups, and provide a reliable roadmap for practitioners navigating the RL for the LLM domain. Finally, we reveal that a minimalist combination of two techniques can unlock the learning capability of critic-free policies using vanilla PPO loss. The results demonstrate that our simple combination consistently improves performance, surpassing strategies like GRPO and DAPO.
IC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025
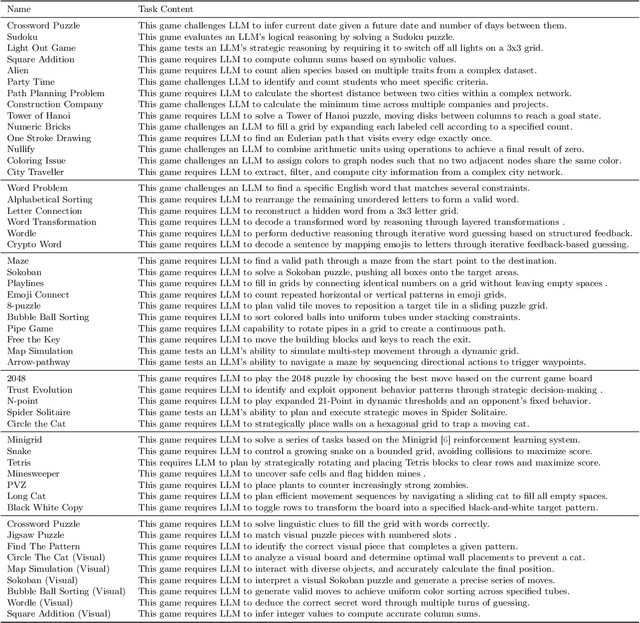
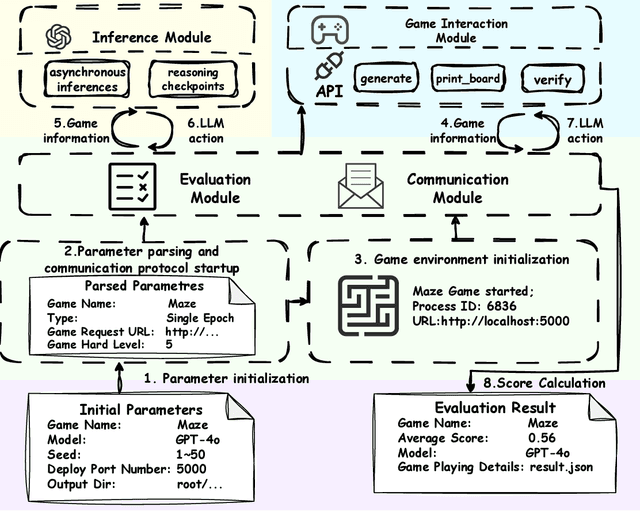

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
Think-J: Learning to Think for Generative LLM-as-a-Judge
May 20, 2025



LLM-as-a-Judge refers to the automatic modeling of preferences for responses generated by Large Language Models (LLMs), which is of significant importance for both LLM evaluation and reward modeling. Although generative LLMs have made substantial progress in various tasks, their performance as LLM-Judge still falls short of expectations. In this work, we propose Think-J, which improves generative LLM-as-a-Judge by learning how to think. We first utilized a small amount of curated data to develop the model with initial judgment thinking capabilities. Subsequently, we optimize the judgment thinking traces based on reinforcement learning (RL). We propose two methods for judgment thinking optimization, based on offline and online RL, respectively. The offline RL requires training a critic model to construct positive and negative examples for learning. The online method defines rule-based reward as feedback for optimization. Experimental results showed that our approach can significantly enhance the evaluation capability of generative LLM-Judge, surpassing both generative and classifier-based LLM-Judge without requiring extra human annotations.