 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlyRoute: Self-Evolving Agent Profiling via Data Flywheel for Adaptive Task Routing
May 21, 2026Enterprise routers assign queries to expert agents, yet deployed profiles stay static while agents evolve (prompts, tools, models), and developers rarely keep descriptions or exemplars current. We present FlyRoute, a self-evolving profiling framework that grows capability evidence from real traffic: dispatch candidates, quality-gate successful pairs into each agent's success store, periodically distill evidence into learned capability descriptions, and inject those descriptions together with BM25-retrieved successes into an LLM router. To make this flywheel data-efficient, FlyRoute introduces a targeted exploration policy that combines profile uncertainty, BM25 relevance, and lexical novelty, prioritizing under-profiled agents only for plausible queries and avoiding redundant evidence collection. In experiments on our proprietary enterprise developer-support dataset of real routed queries, FlyRoute improves a same-backbone zero-shot LLM router from 72.57% to 78.04% with only five seed queries per agent, showing that profile retrieval already strengthens cold-start routing. After streaming 7,211 labeled training queries through the flywheel, accuracy rises to 89.83% (+17.26pp over zero-shot; +11.79pp over cold start), with consistent gains across four expert domains under standard routing accuracy on single-gold test queries.
Resolving Representation Ambiguity in Feedforward Novel View Synthesis Transformer via Semantic-Spatial Decoupling
May 18, 2026Transformer-based models have advanced feedforward novel view synthesis (NVS). Current architectures such as GS-LRM and LVSM mix semantic information (e.g., RGB) and spatial information (e.g., Plücker rays) into a shared feature space. Since Plücker rays naturally carry lattice-like spatial structure, these designs can make the spatial bias interfere with appearance representation and degrade rendering fidelity. To this end, we propose to decouple the representation of feedforward NVS transformers into separate semantic and spatial tokens. The decoupled design keeps semantic and spatial information explicit in their branches while preserving cross-branch interaction through shared attention routing. Built on this design, we introduce optional categorized supervision and bidirectional modulation: the former provides branch-specific training signals, while the latter improves interaction between the two branches. Notably, the base decoupled design introduces virtually zero additional inference latency due to its architectural design. The proposed designs achieve consistent improvements, demonstrating effectiveness across decoder-only and encoder-decoder feedforward NVS models.
Deep Modeling and Interpretation for Bladder Cancer Classification
Feb 10, 2026Deep models based on vision transformer (ViT) and convolutional neural network (CNN) have demonstrated remarkable performance on natural datasets. However, these models may not be similar in medical imaging, where abnormal regions cover only a small portion of the image. This challenge motivates this study to investigate the latest deep models for bladder cancer classification tasks. We propose the following to evaluate these deep models: 1) standard classification using 13 models (four CNNs and eight transormer-based models), 2) calibration analysis to examine if these models are well calibrated for bladder cancer classification, and 3) we use GradCAM++ to evaluate the interpretability of these models for clinical diagnosis. We simulate $\sim 300$ experiments on a publicly multicenter bladder cancer dataset, and the experimental results demonstrate that the ConvNext series indicate limited generalization ability to classify bladder cancer images (e.g., $\sim 60\%$ accuracy). In addition, ViTs show better calibration effects compared to ConvNext and swin transformer series. We also involve test time augmentation to improve the models interpretability. Finally, no model provides a one-size-fits-all solution for a feasible interpretable model. ConvNext series are suitable for in-distribution samples, while ViT and its variants are suitable for interpreting out-of-distribution samples.
Impact of domain adaptation in deep learning for medical image classifications
Feb 10, 2026Domain adaptation (DA) is a quickly expanding area in machine learning that involves adjusting a model trained in one domain to perform well in another domain. While there have been notable progressions, the fundamental concept of numerous DA methodologies has persisted: aligning the data from various domains into a shared feature space. In this space, knowledge acquired from labeled source data can improve the model training on target data that lacks sufficient labels. In this study, we demonstrate the use of 10 deep learning models to simulate common DA techniques and explore their application in four medical image datasets. We have considered various situations such as multi-modality, noisy data, federated learning (FL), interpretability analysis, and classifier calibration. The experimental results indicate that using DA with ResNet34 in a brain tumor (BT) data set results in an enhancement of 4.7\% in model performance. Similarly, the use of DA can reduce the impact of Gaussian noise, as it provides $\sim 3\%$ accuracy increase using ResNet34 on a BT dataset. Furthermore, simply introducing DA into FL framework shows limited potential (e.g., $\sim 0.3\%$ increase in performance) for skin cancer classification. In addition, the DA method can improve the interpretability of the models using the gradcam++ technique, which offers clinical values. Calibration analysis also demonstrates that using DA provides a lower expected calibration error (ECE) value $\sim 2\%$ compared to CNN alone on a multi-modality dataset.
Federated Vision Transformer with Adaptive Focal Loss for Medical Image Classification
Feb 02, 2026While deep learning models like Vision Transformer (ViT) have achieved significant advances, they typically require large datasets. With data privacy regulations, access to many original datasets is restricted, especially medical images. Federated learning (FL) addresses this challenge by enabling global model aggregation without data exchange. However, the heterogeneity of the data and the class imbalance that exist in local clients pose challenges for the generalization of the model. This study proposes a FL framework leveraging a dynamic adaptive focal loss (DAFL) and a client-aware aggregation strategy for local training. Specifically, we design a dynamic class imbalance coefficient that adjusts based on each client's sample distribution and class data distribution, ensuring minority classes receive sufficient attention and preventing sparse data from being ignored. To address client heterogeneity, a weighted aggregation strategy is adopted, which adapts to data size and characteristics to better capture inter-client variations. The classification results on three public datasets (ISIC, Ocular Disease and RSNA-ICH) show that the proposed framework outperforms DenseNet121, ResNet50, ViT-S/16, ViT-L/32, FedCLIP, Swin Transformer, CoAtNet, and MixNet in most cases, with accuracy improvements ranging from 0.98\% to 41.69\%. Ablation studies on the imbalanced ISIC dataset validate the effectiveness of the proposed loss function and aggregation strategy compared to traditional loss functions and other FL approaches. The codes can be found at: https://github.com/AIPMLab/ViT-FLDAF.
Do AI Overviews Benefit Search Engines? An Ecosystem Perspective
Jan 30, 2026The integration of AI Overviews into search engines enhances user experience but diverts traffic from content creators, potentially discouraging high-quality content creation and causing user attrition that undermines long-term search engine profit. To address this issue, we propose a game-theoretic model of creator competition with costly effort, characterize equilibrium behavior, and design two incentive mechanisms: a citation mechanism that references sources within an AI Overview, and a compensation mechanism that offers monetary rewards to creators. For both cases, we provide structural insights and near-optimal profit-maximizing mechanisms. Evaluations on real click data show that although AI Overviews harm long-term search engine profit, interventions based on our proposed mechanisms can increase long-term profit across a range of realistic scenarios, pointing toward a more sustainable trajectory for AI-enhanced search ecosystems.
Reliable and Private Utility Signaling for Data Markets
Nov 11, 2025The explosive growth of data has highlighted its critical role in driving economic growth through data marketplaces, which enable extensive data sharing and access to high-quality datasets. To support effective trading, signaling mechanisms provide participants with information about data products before transactions, enabling informed decisions and facilitating trading. However, due to the inherent free-duplication nature of data, commonly practiced signaling methods face a dilemma between privacy and reliability, undermining the effectiveness of signals in guiding decision-making. To address this, this paper explores the benefits and develops a non-TCP-based construction for a desirable signaling mechanism that simultaneously ensures privacy and reliability. We begin by formally defining the desirable utility signaling mechanism and proving its ability to prevent suboptimal decisions for both participants and facilitate informed data trading. To design a protocol to realize its functionality, we propose leveraging maliciously secure multi-party computation (MPC) to ensure the privacy and robustness of signal computation and introduce an MPC-based hash verification scheme to ensure input reliability. In multi-seller scenarios requiring fair data valuation, we further explore the design and optimization of the MPC-based KNN-Shapley method with improved efficiency. Rigorous experiments demonstrate the efficiency and practicality of our approach.
Federated CLIP for Resource-Efficient Heterogeneous Medical Image Classification
Nov 11, 2025Despite the remarkable performance of deep models in medical imaging, they still require source data for training, which limits their potential in light of privacy concerns. Federated learning (FL), as a decentralized learning framework that trains a shared model with multiple hospitals (a.k.a., FL clients), provides a feasible solution. However, data heterogeneity and resource costs hinder the deployment of FL models, especially when using vision language models (VLM). To address these challenges, we propose a novel contrastive language-image pre-training (CLIP) based FL approach for medical image classification (FedMedCLIP). Specifically, we introduce a masked feature adaptation module (FAM) as a communication module to reduce the communication load while freezing the CLIP encoders to reduce the computational overhead. Furthermore, we propose a masked multi-layer perceptron (MLP) as a private local classifier to adapt to the client tasks. Moreover, we design an adaptive Kullback-Leibler (KL) divergence-based distillation regularization method to enable mutual learning between FAM and MLP. Finally, we incorporate model compression to transmit the FAM parameters while using ensemble predictions for classification. Extensive experiments on four publicly available medical datasets demonstrate that our model provides feasible performance (e.g., 8\% higher compared to second best baseline on ISIC2019) with reasonable resource cost (e.g., 120$\times$ faster than FedAVG).
Breaking the Modality Barrier: Generative Modeling for Accurate Molecule Retrieval from Mass Spectra
Nov 09, 2025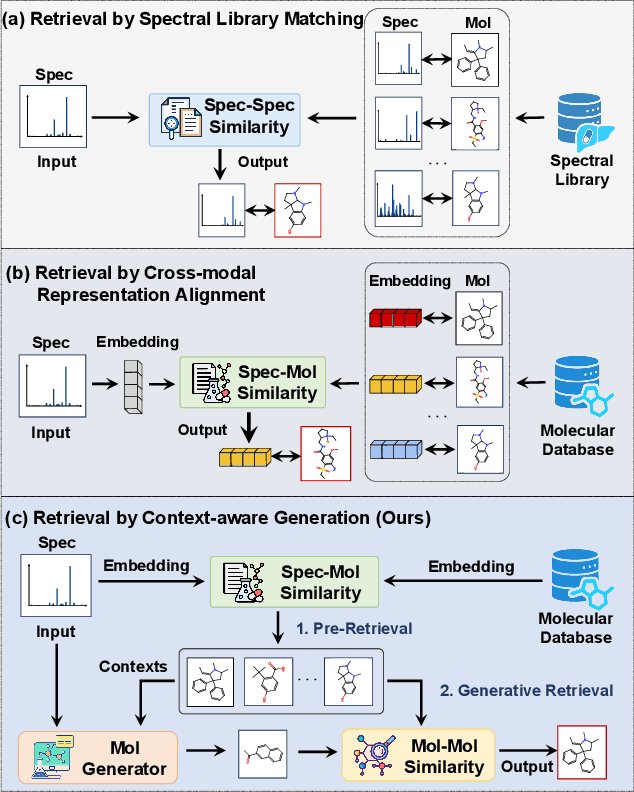



Retrieving molecular structures from tandem mass spectra is a crucial step in rapid compound identification. Existing retrieval methods, such as traditional mass spectral library matching, suffer from limited spectral library coverage, while recent cross-modal representation learning frameworks often encounter modality misalignment, resulting in suboptimal retrieval accuracy and generalization. To address these limitations, we propose GLMR, a Generative Language Model-based Retrieval framework that mitigates the cross-modal misalignment through a two-stage process. In the pre-retrieval stage, a contrastive learning-based model identifies top candidate molecules as contextual priors for the input mass spectrum. In the generative retrieval stage, these candidate molecules are integrated with the input mass spectrum to guide a generative model in producing refined molecular structures, which are then used to re-rank the candidates based on molecular similarity. Experiments on both MassSpecGym and the proposed MassRET-20k dataset demonstrate that GLMR significantly outperforms existing methods, achieving over 40% improvement in top-1 accuracy and exhibiting strong generalizability.
Enhancing Dual Network Based Semi-Supervised Medical Image Segmentation with Uncertainty-Guided Pseudo-Labeling
Sep 16, 2025Despite the remarkable performance of supervised medical image segmentation models, relying on a large amount of labeled data is impractical in real-world situations. Semi-supervised learning approaches aim to alleviate this challenge using unlabeled data through pseudo-label generation. Yet, existing semi-supervised segmentation methods still suffer from noisy pseudo-labels and insufficient supervision within the feature space. To solve these challenges, this paper proposes a novel semi-supervised 3D medical image segmentation framework based on a dual-network architecture. Specifically, we investigate a Cross Consistency Enhancement module using both cross pseudo and entropy-filtered supervision to reduce the noisy pseudo-labels, while we design a dynamic weighting strategy to adjust the contributions of pseudo-labels using an uncertainty-aware mechanism (i.e., Kullback-Leibler divergence). In addition, we use a self-supervised contrastive learning mechanism to align uncertain voxel features with reliable class prototypes by effectively differentiating between trustworthy and uncertain predictions, thus reducing prediction uncertainty. Extensive experiments are conducted on three 3D segmentation datasets, Left Atrial, NIH Pancreas and BraTS-2019. The proposed approach consistently exhibits superior performance across various settings (e.g., 89.95\% Dice score on left Atrial with 10\% labeled data) compared to the state-of-the-art methods. Furthermore, the usefulness of the proposed modules is further validated via ablation experiments.