 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFAN, a transformer-based deep learning model for human-artificial intelligence collaborative assessment of incidental pulmonary nodules in CT scans: a multi-reader, multi-case trial
Mar 26, 2026The widespread adoption of CT has notably increased the number of detected lung nodules. However, current deep learning methods for classifying benign and malignant nodules often fail to comprehensively integrate global and local features, and most of them have not been validated through clinical trials. To address this, we developed DeepFAN, a transformer-based model trained on over 10K pathology-confirmed nodules and further conducted a multi-reader, multi-case clinical trial to evaluate its efficacy in assisting junior radiologists. DeepFAN achieved diagnostic area under the curve (AUC) of 0.939 (95% CI 0.930-0.948) on an internal test set and 0.954 (95% CI 0.934-0.973) on the clinical trial dataset involving 400 cases across three independent medical institutions. Explainability analysis indicated higher contributions from global than local features. Twelve readers' average performance significantly improved by 10.9% (95% CI 8.3%-13.5%) in AUC, 10.0% (95% CI 8.9%-11.1%) in accuracy, 7.6% (95% CI 6.1%-9.2%) in sensitivity, and 12.6% (95% CI 10.9%-14.3%) in specificity (P<0.001 for all). Nodule-level inter-reader diagnostic consistency improved from fair to moderate (overall k: 0.313 vs. 0.421; P=0.019). In conclusion, DeepFAN effectively assisted junior radiologists and may help homogenize diagnostic quality and reduce unnecessary follow-up of indeterminate pulmonary nodules. Chinese Clinical Trial Registry: ChiCTR2400084624.
HyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025



Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
Reliable and Private Utility Signaling for Data Markets
Nov 11, 2025The explosive growth of data has highlighted its critical role in driving economic growth through data marketplaces, which enable extensive data sharing and access to high-quality datasets. To support effective trading, signaling mechanisms provide participants with information about data products before transactions, enabling informed decisions and facilitating trading. However, due to the inherent free-duplication nature of data, commonly practiced signaling methods face a dilemma between privacy and reliability, undermining the effectiveness of signals in guiding decision-making. To address this, this paper explores the benefits and develops a non-TCP-based construction for a desirable signaling mechanism that simultaneously ensures privacy and reliability. We begin by formally defining the desirable utility signaling mechanism and proving its ability to prevent suboptimal decisions for both participants and facilitate informed data trading. To design a protocol to realize its functionality, we propose leveraging maliciously secure multi-party computation (MPC) to ensure the privacy and robustness of signal computation and introduce an MPC-based hash verification scheme to ensure input reliability. In multi-seller scenarios requiring fair data valuation, we further explore the design and optimization of the MPC-based KNN-Shapley method with improved efficiency. Rigorous experiments demonstrate the efficiency and practicality of our approach.
OpBoost: A Vertical Federated Tree Boosting Framework Based on Order-Preserving Desensitization
Oct 04, 2022
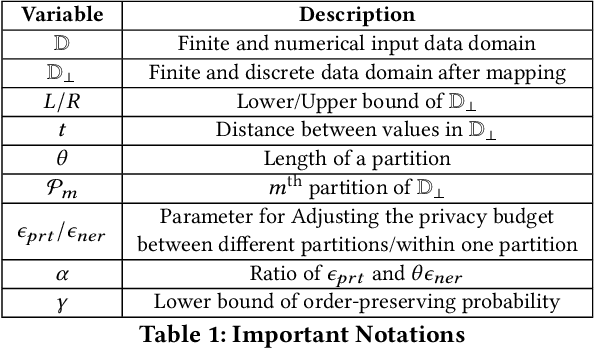
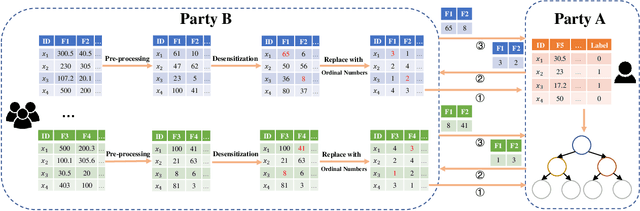
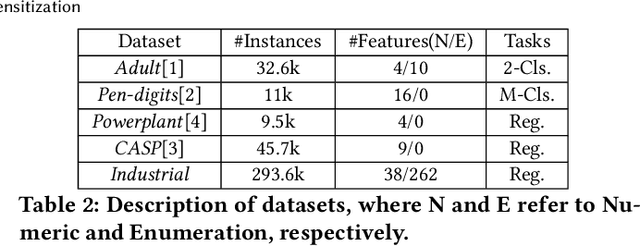
Vertical Federated Learning (FL) is a new paradigm that enables users with non-overlapping attributes of the same data samples to jointly train a model without directly sharing the raw data. Nevertheless, recent works show that it's still not sufficient to prevent privacy leakage from the training process or the trained model. This paper focuses on studying the privacy-preserving tree boosting algorithms under the vertical FL. The existing solutions based on cryptography involve heavy computation and communication overhead and are vulnerable to inference attacks. Although the solution based on Local Differential Privacy (LDP) addresses the above problems, it leads to the low accuracy of the trained model. This paper explores to improve the accuracy of the widely deployed tree boosting algorithms satisfying differential privacy under vertical FL. Specifically, we introduce a framework called OpBoost. Three order-preserving desensitization algorithms satisfying a variant of LDP called distance-based LDP (dLDP) are designed to desensitize the training data. In particular, we optimize the dLDP definition and study efficient sampling distributions to further improve the accuracy and efficiency of the proposed algorithms. The proposed algorithms provide a trade-off between the privacy of pairs with large distance and the utility of desensitized values. Comprehensive evaluations show that OpBoost has a better performance on prediction accuracy of trained models compared with existing LDP approaches on reasonable settings. Our code is open source.
Knowledge Squeezed Adversarial Network Compression
Apr 25, 2019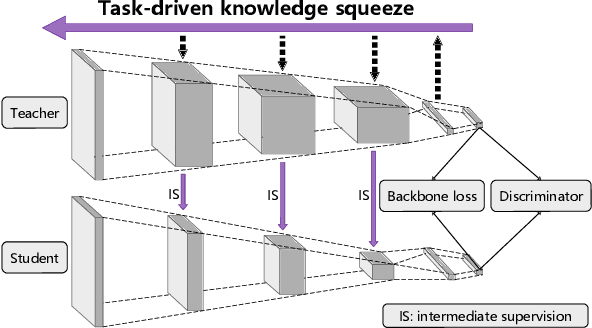
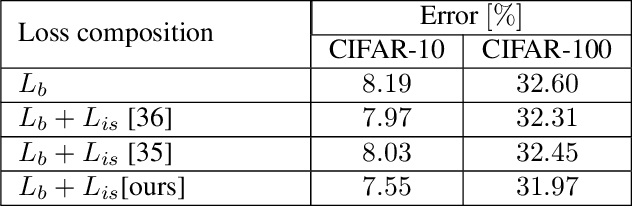
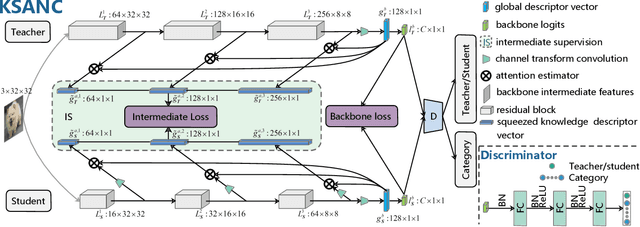
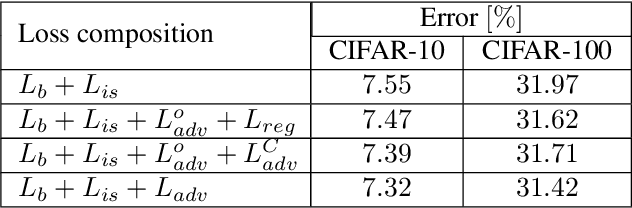
Deep network compression has been achieved notable progress via knowledge distillation, where a teacher-student learning manner is adopted by using predetermined loss. Recently, more focuses have been transferred to employ the adversarial training to minimize the discrepancy between distributions of output from two networks. However, they always emphasize on result-oriented learning while neglecting the scheme of process-oriented learning, leading to the loss of rich information contained in the whole network pipeline. Inspired by the assumption that, the small network can not perfectly mimic a large one due to the huge gap of network scale, we propose a knowledge transfer method, involving effective intermediate supervision, under the adversarial training framework to learn the student network. To achieve powerful but highly compact intermediate information representation, the squeezed knowledge is realized by task-driven attention mechanism. Then, the transferred knowledge from teacher network could accommodate the size of student network. As a result, the proposed method integrates merits from both process-oriented and result-oriented learning. Extensive experimental results on three typical benchmark datasets, i.e., CIFAR-10, CIFAR-100, and ImageNet, demonstrate that our method achieves highly superior performances against other state-of-the-art methods.
SECaps: A Sequence Enhanced Capsule Model for Charge Prediction
Oct 10, 2018
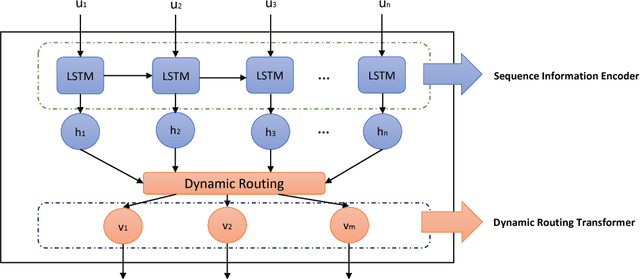

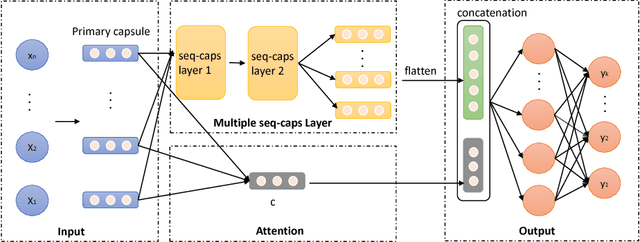
Automatic charge prediction aims to predict appropriate final charges according to the fact descriptions for a given criminal case. Automatic charge pre-diction plays an important role in assisting judges and lawyers to improve the effi-ciency of legal decisions, and thus has received much attention. Nevertheless, most existing works on automatic charge prediction perform adequately on those high-frequency charges but are not yet capable of predicting few-shot charges with lim-ited cases. On the other hand, some works have shown the benefits of capsule net-work, which is a powerful technique. This motivates us to propose a Sequence En-hanced Capsule model, dubbed as SECaps model, to relieve this problem. More specifically, we propose a new basic structure, seq-caps layer, to enhance capsule by taking sequence information in to account. In addition, we construct our SE-Caps model by making use of seq-caps layer. Comparing the state-of-the-art meth-ods, our SECaps model achieves 4.5% and 6.4% F1 promotion in two real-world datasets, Criminal-S and Criminal-L, respectively. The experimental results consis-tently demonstrate the superiorities and competitiveness of our proposed model.