 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning Diffusion Models for Molecular Generation via Reinforcement Learning and Fast Sampling
May 31, 2026Generating molecules that simultaneously satisfy drug-like properties and conform to the 3D structure of a target protein is a core challenge in structure-based drug design (SBDD). Existing generative approaches, however, often rely on costly post-hoc processing during Sampling or require carefully curated datasets during training, yet still achieve modest gains. These limitations are especially pronounced in multi-objective settings, where balancing conflicting criteria remains a core challenge. To address these challenges, We propose FTDiff, a reinforcement learning fine-tuning framework tailored for diffusion-based molecular generation under structural constraints. To ensure stable and sample-efficient optimization, FTDiff adopts a group relative policy optimization (GRPO) style strategy. Furthermore, FTDiff builds upon a time-free pretrained diffusion model and incorporates a fast sampling mechanism that reduces the number of denoising steps, significantly accelerating both training and inference while maintaining generation quality. By optimizing a fixed threshold-aware reward, FTDiff effectively guides the model to produce valid, diverse, and high- quality molecules that balance multiple drug design objectives. Extensive experiments on benchmark datasets demonstrate that FTDiff consistently outperforms prior methods, without requiring expensive post-hoc optimization or intricate data engineering.
Factored Causal Representation Learning for Robust Reward Modeling in RLHF
Jan 29, 2026A reliable reward model is essential for aligning large language models with human preferences through reinforcement learning from human feedback. However, standard reward models are susceptible to spurious features that are not causally related to human labels. This can lead to reward hacking, where high predicted reward does not translate into better behavior. In this work, we address this problem from a causal perspective by proposing a factored representation learning framework that decomposes the model's contextual embedding into (1) causal factors that are sufficient for reward prediction and (2) non-causal factors that capture reward-irrelevant attributes such as length or sycophantic bias. The reward head is then constrained to depend only on the causal component. In addition, we introduce an adversarial head trained to predict reward from the non-causal factors, while applying gradient reversal to discourage them from encoding reward-relevant information. Experiments on both mathematical and dialogue tasks demonstrate that our method learns more robust reward models and consistently improves downstream RLHF performance over state-of-the-art baselines. Analyses on length and sycophantic bias further validate the effectiveness of our method in mitigating reward hacking behaviors.
Full-Atom Peptide Design via Riemannian-Euclidean Bayesian Flow Networks
Nov 19, 2025



Diffusion and flow matching models have recently emerged as promising approaches for peptide binder design. Despite their progress, these models still face two major challenges. First, categorical sampling of discrete residue types collapses their continuous parameters into onehot assignments, while continuous variables (e.g., atom positions) evolve smoothly throughout the generation process. This mismatch disrupts the update dynamics and results in suboptimal performance. Second, current models assume unimodal distributions for side-chain torsion angles, which conflicts with the inherently multimodal nature of side chain rotameric states and limits prediction accuracy. To address these limitations, we introduce PepBFN, the first Bayesian flow network for full atom peptide design that directly models parameter distributions in fully continuous space. Specifically, PepBFN models discrete residue types by learning their continuous parameter distributions, enabling joint and smooth Bayesian updates with other continuous structural parameters. It further employs a novel Gaussian mixture based Bayesian flow to capture the multimodal side chain rotameric states and a Matrix Fisher based Riemannian flow to directly model residue orientations on the $\mathrm{SO}(3)$ manifold. Together, these parameter distributions are progressively refined via Bayesian updates, yielding smooth and coherent peptide generation. Experiments on side chain packing, reverse folding, and binder design tasks demonstrate the strong potential of PepBFN in computational peptide design.
Text to Sketch Generation with Multi-Styles
Nov 06, 2025Recent advances in vision-language models have facilitated progress in sketch generation. However, existing specialized methods primarily focus on generic synthesis and lack mechanisms for precise control over sketch styles. In this work, we propose a training-free framework based on diffusion models that enables explicit style guidance via textual prompts and referenced style sketches. Unlike previous style transfer methods that overwrite key and value matrices in self-attention, we incorporate the reference features as auxiliary information with linear smoothing and leverage a style-content guidance mechanism. This design effectively reduces content leakage from reference sketches and enhances synthesis quality, especially in cases with low structural similarity between reference and target sketches. Furthermore, we extend our framework to support controllable multi-style generation by integrating features from multiple reference sketches, coordinated via a joint AdaIN module. Extensive experiments demonstrate that our approach achieves high-quality sketch generation with accurate style alignment and improved flexibility in style control. The official implementation of M3S is available at https://github.com/CMACH508/M3S.
DEPTH: Hallucination-Free Relation Extraction via Dependency-Aware Sentence Simplification and Two-tiered Hierarchical Refinement
Aug 20, 2025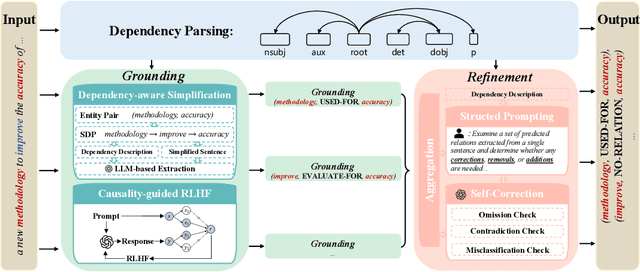

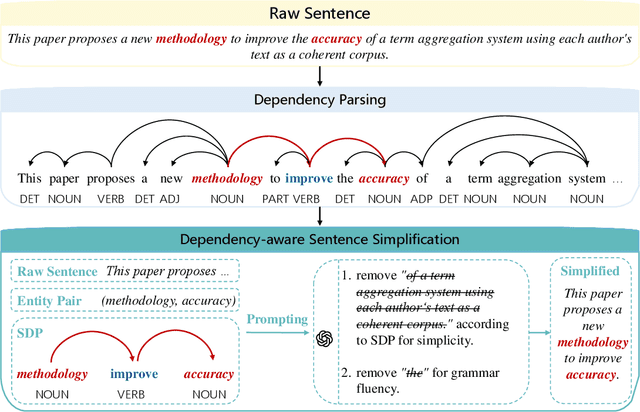

Relation extraction enables the construction of structured knowledge for many downstream applications. While large language models (LLMs) have shown great promise in this domain, most existing methods concentrate on relation classification, which predicts the semantic relation type between a related entity pair. However, we observe that LLMs often struggle to reliably determine whether a relation exists, especially in cases involving complex sentence structures or intricate semantics, which leads to spurious predictions. Such hallucinations can introduce noisy edges in knowledge graphs, compromising the integrity of structured knowledge and downstream reliability. To address these challenges, we propose DEPTH, a framework that integrates Dependency-aware sEntence simPlification and Two-tiered Hierarchical refinement into the relation extraction pipeline. Given a sentence and its candidate entity pairs, DEPTH operates in two stages: (1) the Grounding module extracts relations for each pair by leveraging their shortest dependency path, distilling the sentence into a minimal yet coherent relational context that reduces syntactic noise while preserving key semantics; (2) the Refinement module aggregates all local predictions and revises them based on a holistic understanding of the sentence, correcting omissions and inconsistencies. We further introduce a causality-driven reward model that mitigates reward hacking by disentangling spurious correlations, enabling robust fine-tuning via reinforcement learning with human feedback. Experiments on six benchmarks demonstrate that DEPTH reduces the average hallucination rate to 7.0\% while achieving a 17.2\% improvement in average F1 score over state-of-the-art baselines.
Non-Linear Flow Matching for Full-Atom Peptide Design
Feb 21, 2025Peptide design plays a pivotal role in therapeutic applications, yet existing AI-assisted methods often struggle to generate stable peptides with high affinity due to their inability to accurately simulate the dynamic docking process. To address this challenge, we propose NLFlow, a novel multi-manifold approach based on non-linear flow matching. Specifically, we design a polynomial-based conditional vector field to accelerate the convergence of the peptide's position towards the target pocket, effectively capturing the temporal inconsistencies across position, rotation, torsion, and amino acid type manifolds. This enables the model to better align with the true conformational changes observed in biological docking processes. Additionally, we incorporate interaction-related information, such as polarity, to enhance the understanding of peptide-protein binding. Extensive experiments demonstrate that NLFlow outperforms existing methods in generating peptides with superior stability, affinity, and diversity, offering a fast and efficient solution for peptide design and advancing the peptide-based therapeutic development.
Towards Generalizable Reinforcement Learning via Causality-Guided Self-Adaptive Representations
Jul 31, 2024



General intelligence requires quick adaption across tasks. While existing reinforcement learning (RL) methods have made progress in generalization, they typically assume only distribution changes between source and target domains. In this paper, we explore a wider range of scenarios where both the distribution and environment spaces may change. For example, in Atari games, we train agents to generalize to tasks with different levels of mode and difficulty, where there could be new state or action variables that never occurred in previous environments. To address this challenging setting, we introduce a causality-guided self-adaptive representation-based approach, called CSR, that equips the agent to generalize effectively and efficiently across a sequence of tasks with evolving dynamics. Specifically, we employ causal representation learning to characterize the latent causal variables and world models within the RL system. Such compact causal representations uncover the structural relationships among variables, enabling the agent to autonomously determine whether changes in the environment stem from distribution shifts or variations in space, and to precisely locate these changes. We then devise a three-step strategy to fine-tune the model under different scenarios accordingly. Empirical experiments show that CSR efficiently adapts to the target domains with only a few samples and outperforms state-of-the-art baselines on a wide range of scenarios, including our simulated environments, Cartpole, and Atari games.
Boosting Efficiency in Task-Agnostic Exploration through Causal Knowledge
Jul 30, 2024



The effectiveness of model training heavily relies on the quality of available training resources. However, budget constraints often impose limitations on data collection efforts. To tackle this challenge, we introduce causal exploration in this paper, a strategy that leverages the underlying causal knowledge for both data collection and model training. We, in particular, focus on enhancing the sample efficiency and reliability of the world model learning within the domain of task-agnostic reinforcement learning. During the exploration phase, the agent actively selects actions expected to yield causal insights most beneficial for world model training. Concurrently, the causal knowledge is acquired and incrementally refined with the ongoing collection of data. We demonstrate that causal exploration aids in learning accurate world models using fewer data and provide theoretical guarantees for its convergence. Empirical experiments, on both synthetic data and real-world applications, further validate the benefits of causal exploration.
PFB-Diff: Progressive Feature Blending Diffusion for Text-driven Image Editing
Jun 28, 2023



Diffusion models have showcased their remarkable capability to synthesize diverse and high-quality images, sparking interest in their application for real image editing. However, existing diffusion-based approaches for local image editing often suffer from undesired artifacts due to the pixel-level blending of the noised target images and diffusion latent variables, which lack the necessary semantics for maintaining image consistency. To address these issues, we propose PFB-Diff, a Progressive Feature Blending method for Diffusion-based image editing. Unlike previous methods, PFB-Diff seamlessly integrates text-guided generated content into the target image through multi-level feature blending. The rich semantics encoded in deep features and the progressive blending scheme from high to low levels ensure semantic coherence and high quality in edited images. Additionally, we introduce an attention masking mechanism in the cross-attention layers to confine the impact of specific words to desired regions, further improving the performance of background editing. PFB-Diff can effectively address various editing tasks, including object/background replacement and object attribute editing. Our method demonstrates its superior performance in terms of image fidelity, editing accuracy, efficiency, and faithfulness to the original image, without the need for fine-tuning or training.
Linking Sketch Patches by Learning Synonymous Proximity for Graphic Sketch Representation
Nov 30, 2022



Graphic sketch representations are effective for representing sketches. Existing methods take the patches cropped from sketches as the graph nodes, and construct the edges based on sketch's drawing order or Euclidean distances on the canvas. However, the drawing order of a sketch may not be unique, while the patches from semantically related parts of a sketch may be far away from each other on the canvas. In this paper, we propose an order-invariant, semantics-aware method for graphic sketch representations. The cropped sketch patches are linked according to their global semantics or local geometric shapes, namely the synonymous proximity, by computing the cosine similarity between the captured patch embeddings. Such constructed edges are learnable to adapt to the variation of sketch drawings, which enable the message passing among synonymous patches. Aggregating the messages from synonymous patches by graph convolutional networks plays a role of denoising, which is beneficial to produce robust patch embeddings and accurate sketch representations. Furthermore, we enforce a clustering constraint over the embeddings jointly with the network learning. The synonymous patches are self-organized as compact clusters, and their embeddings are guided to move towards their assigned cluster centroids. It raises the accuracy of the computed synonymous proximity. Experimental results show that our method significantly improves the performance on both controllable sketch synthesis and sketch healing.