 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactored Causal Representation Learning for Robust Reward Modeling in RLHF
Jan 29, 2026A reliable reward model is essential for aligning large language models with human preferences through reinforcement learning from human feedback. However, standard reward models are susceptible to spurious features that are not causally related to human labels. This can lead to reward hacking, where high predicted reward does not translate into better behavior. In this work, we address this problem from a causal perspective by proposing a factored representation learning framework that decomposes the model's contextual embedding into (1) causal factors that are sufficient for reward prediction and (2) non-causal factors that capture reward-irrelevant attributes such as length or sycophantic bias. The reward head is then constrained to depend only on the causal component. In addition, we introduce an adversarial head trained to predict reward from the non-causal factors, while applying gradient reversal to discourage them from encoding reward-relevant information. Experiments on both mathematical and dialogue tasks demonstrate that our method learns more robust reward models and consistently improves downstream RLHF performance over state-of-the-art baselines. Analyses on length and sycophantic bias further validate the effectiveness of our method in mitigating reward hacking behaviors.
ShopSimulator: Evaluating and Exploring RL-Driven LLM Agent for Shopping Assistants
Jan 26, 2026Large language model (LLM)-based agents are increasingly deployed in e-commerce shopping. To perform thorough, user-tailored product searches, agents should interpret personal preferences, engage in multi-turn dialogues, and ultimately retrieve and discriminate among highly similar products. However, existing research has yet to provide a unified simulation environment that consistently captures all of these aspects, and always focuses solely on evaluation benchmarks without training support. In this paper, we introduce ShopSimulator, a large-scale and challenging Chinese shopping environment. Leveraging ShopSimulator, we evaluate LLMs across diverse scenarios, finding that even the best-performing models achieve less than 40% full-success rate. Error analysis reveals that agents struggle with deep search and product selection in long trajectories, fail to balance the use of personalization cues, and to effectively engage with users. Further training exploration provides practical guidance for overcoming these weaknesses, with the combination of supervised fine-tuning (SFT) and reinforcement learning (RL) yielding significant performance improvements. Code and data will be released at https://github.com/ShopAgent-Team/ShopSimulator.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
DEPTH: Hallucination-Free Relation Extraction via Dependency-Aware Sentence Simplification and Two-tiered Hierarchical Refinement
Aug 20, 2025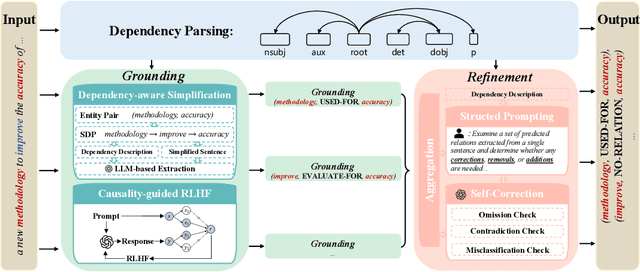

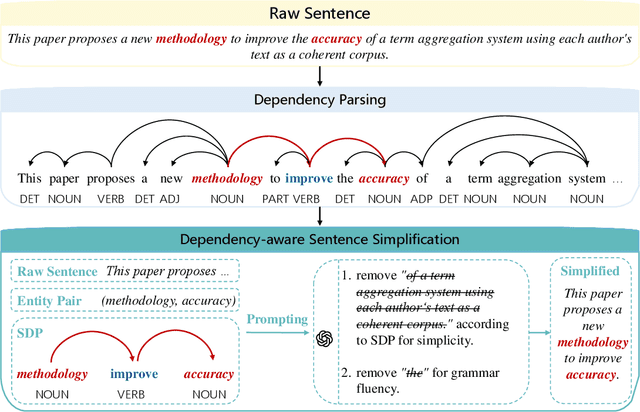

Relation extraction enables the construction of structured knowledge for many downstream applications. While large language models (LLMs) have shown great promise in this domain, most existing methods concentrate on relation classification, which predicts the semantic relation type between a related entity pair. However, we observe that LLMs often struggle to reliably determine whether a relation exists, especially in cases involving complex sentence structures or intricate semantics, which leads to spurious predictions. Such hallucinations can introduce noisy edges in knowledge graphs, compromising the integrity of structured knowledge and downstream reliability. To address these challenges, we propose DEPTH, a framework that integrates Dependency-aware sEntence simPlification and Two-tiered Hierarchical refinement into the relation extraction pipeline. Given a sentence and its candidate entity pairs, DEPTH operates in two stages: (1) the Grounding module extracts relations for each pair by leveraging their shortest dependency path, distilling the sentence into a minimal yet coherent relational context that reduces syntactic noise while preserving key semantics; (2) the Refinement module aggregates all local predictions and revises them based on a holistic understanding of the sentence, correcting omissions and inconsistencies. We further introduce a causality-driven reward model that mitigates reward hacking by disentangling spurious correlations, enabling robust fine-tuning via reinforcement learning with human feedback. Experiments on six benchmarks demonstrate that DEPTH reduces the average hallucination rate to 7.0\% while achieving a 17.2\% improvement in average F1 score over state-of-the-art baselines.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.