 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactored Causal Representation Learning for Robust Reward Modeling in RLHF
Jan 29, 2026A reliable reward model is essential for aligning large language models with human preferences through reinforcement learning from human feedback. However, standard reward models are susceptible to spurious features that are not causally related to human labels. This can lead to reward hacking, where high predicted reward does not translate into better behavior. In this work, we address this problem from a causal perspective by proposing a factored representation learning framework that decomposes the model's contextual embedding into (1) causal factors that are sufficient for reward prediction and (2) non-causal factors that capture reward-irrelevant attributes such as length or sycophantic bias. The reward head is then constrained to depend only on the causal component. In addition, we introduce an adversarial head trained to predict reward from the non-causal factors, while applying gradient reversal to discourage them from encoding reward-relevant information. Experiments on both mathematical and dialogue tasks demonstrate that our method learns more robust reward models and consistently improves downstream RLHF performance over state-of-the-art baselines. Analyses on length and sycophantic bias further validate the effectiveness of our method in mitigating reward hacking behaviors.
DEPTH: Hallucination-Free Relation Extraction via Dependency-Aware Sentence Simplification and Two-tiered Hierarchical Refinement
Aug 20, 2025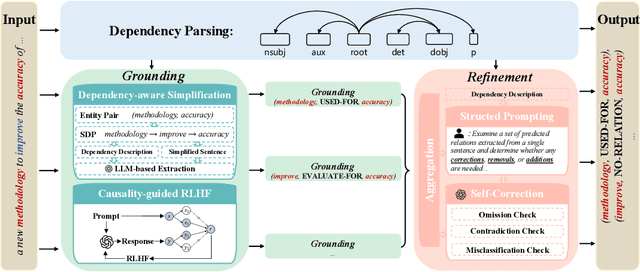

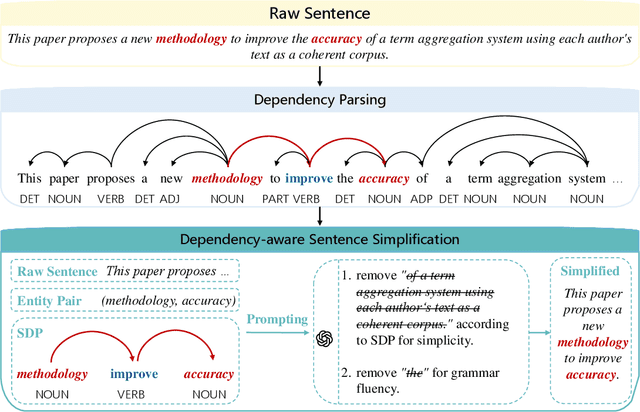

Relation extraction enables the construction of structured knowledge for many downstream applications. While large language models (LLMs) have shown great promise in this domain, most existing methods concentrate on relation classification, which predicts the semantic relation type between a related entity pair. However, we observe that LLMs often struggle to reliably determine whether a relation exists, especially in cases involving complex sentence structures or intricate semantics, which leads to spurious predictions. Such hallucinations can introduce noisy edges in knowledge graphs, compromising the integrity of structured knowledge and downstream reliability. To address these challenges, we propose DEPTH, a framework that integrates Dependency-aware sEntence simPlification and Two-tiered Hierarchical refinement into the relation extraction pipeline. Given a sentence and its candidate entity pairs, DEPTH operates in two stages: (1) the Grounding module extracts relations for each pair by leveraging their shortest dependency path, distilling the sentence into a minimal yet coherent relational context that reduces syntactic noise while preserving key semantics; (2) the Refinement module aggregates all local predictions and revises them based on a holistic understanding of the sentence, correcting omissions and inconsistencies. We further introduce a causality-driven reward model that mitigates reward hacking by disentangling spurious correlations, enabling robust fine-tuning via reinforcement learning with human feedback. Experiments on six benchmarks demonstrate that DEPTH reduces the average hallucination rate to 7.0\% while achieving a 17.2\% improvement in average F1 score over state-of-the-art baselines.
Towards Generalizable Reinforcement Learning via Causality-Guided Self-Adaptive Representations
Jul 31, 2024



General intelligence requires quick adaption across tasks. While existing reinforcement learning (RL) methods have made progress in generalization, they typically assume only distribution changes between source and target domains. In this paper, we explore a wider range of scenarios where both the distribution and environment spaces may change. For example, in Atari games, we train agents to generalize to tasks with different levels of mode and difficulty, where there could be new state or action variables that never occurred in previous environments. To address this challenging setting, we introduce a causality-guided self-adaptive representation-based approach, called CSR, that equips the agent to generalize effectively and efficiently across a sequence of tasks with evolving dynamics. Specifically, we employ causal representation learning to characterize the latent causal variables and world models within the RL system. Such compact causal representations uncover the structural relationships among variables, enabling the agent to autonomously determine whether changes in the environment stem from distribution shifts or variations in space, and to precisely locate these changes. We then devise a three-step strategy to fine-tune the model under different scenarios accordingly. Empirical experiments show that CSR efficiently adapts to the target domains with only a few samples and outperforms state-of-the-art baselines on a wide range of scenarios, including our simulated environments, Cartpole, and Atari games.
Boosting Efficiency in Task-Agnostic Exploration through Causal Knowledge
Jul 30, 2024



The effectiveness of model training heavily relies on the quality of available training resources. However, budget constraints often impose limitations on data collection efforts. To tackle this challenge, we introduce causal exploration in this paper, a strategy that leverages the underlying causal knowledge for both data collection and model training. We, in particular, focus on enhancing the sample efficiency and reliability of the world model learning within the domain of task-agnostic reinforcement learning. During the exploration phase, the agent actively selects actions expected to yield causal insights most beneficial for world model training. Concurrently, the causal knowledge is acquired and incrementally refined with the ongoing collection of data. We demonstrate that causal exploration aids in learning accurate world models using fewer data and provide theoretical guarantees for its convergence. Empirical experiments, on both synthetic data and real-world applications, further validate the benefits of causal exploration.