 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiva-DiT: Residual-Based Differentiable Top-$k$ Selection for Efficient Diffusion Transformers
Feb 05, 2026Diffusion Transformers (DiTs) incur prohibitive computational costs due to the quadratic scaling of self-attention. Existing pruning methods fail to simultaneously satisfy differentiability, efficiency, and the strict static budgets required for hardware overhead. To address this, we propose Shiva-DiT, which effectively reconciles these conflicting requirements via Residual-Based Differentiable Top-$k$ Selection. By leveraging a residual-aware straight-through estimator, our method enforces deterministic token counts for static compilation while preserving end-to-end learnability through residual gradient estimation. Furthermore, we introduce a Context-Aware Router and Adaptive Ratio Policy to autonomously learn an adaptive pruning schedule. Experiments on mainstream models, including SD3.5, demonstrate that Shiva-DiT establishes a new Pareto frontier, achieving a 1.54$\times$ wall-clock speedup with superior fidelity compared to existing baselines, effectively eliminating ragged tensor overheads.
Neural Quantum Propagators for Driven-Dissipative Quantum Dynamics
Oct 21, 2024



Describing the dynamics of strong-laser driven open quantum systems is a very challenging task that requires the solution of highly involved equations of motion. While machine learning techniques are being applied with some success to simulate the time evolution of individual quantum states, their use to approximate time-dependent operators (that can evolve various states) remains largely unexplored. In this work, we develop driven neural quantum propagators (NQP), a universal neural network framework that solves driven-dissipative quantum dynamics by approximating propagators rather than wavefunctions or density matrices. NQP can handle arbitrary initial quantum states, adapt to various external fields, and simulate long-time dynamics, even when trained on far shorter time windows. Furthermore, by appropriately configuring the external fields, our trained NQP can be transferred to systems governed by different Hamiltonians. We demonstrate the effectiveness of our approach by studying the spin-boson and the three-state transition Gamma models.
Any-step Dynamics Model Improves Future Predictions for Online and Offline Reinforcement Learning
May 27, 2024



Model-based methods in reinforcement learning offer a promising approach to enhance data efficiency by facilitating policy exploration within a dynamics model. However, accurately predicting sequential steps in the dynamics model remains a challenge due to the bootstrapping prediction, which attributes the next state to the prediction of the current state. This leads to accumulated errors during model roll-out. In this paper, we propose the Any-step Dynamics Model (ADM) to mitigate the compounding error by reducing bootstrapping prediction to direct prediction. ADM allows for the use of variable-length plans as inputs for predicting future states without frequent bootstrapping. We design two algorithms, ADMPO-ON and ADMPO-OFF, which apply ADM in online and offline model-based frameworks, respectively. In the online setting, ADMPO-ON demonstrates improved sample efficiency compared to previous state-of-the-art methods. In the offline setting, ADMPO-OFF not only demonstrates superior performance compared to recent state-of-the-art offline approaches but also offers better quantification of model uncertainty using only a single ADM.
Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts
Apr 14, 2024



Reinforcement learning (RL) trains agents to accomplish complex tasks through environmental interaction data, but its capacity is also limited by the scope of the available data. To obtain a knowledgeable agent, a promising approach is to leverage the knowledge from large language models (LLMs). Despite previous studies combining LLMs with RL, seamless integration of the two components remains challenging due to their semantic gap. This paper introduces a novel method, Knowledgeable Agents from Language Model Rollouts (KALM), which extracts knowledge from LLMs in the form of imaginary rollouts that can be easily learned by the agent through offline reinforcement learning methods. The primary challenge of KALM lies in LLM grounding, as LLMs are inherently limited to textual data, whereas environmental data often comprise numerical vectors unseen to LLMs. To address this, KALM fine-tunes the LLM to perform various tasks based on environmental data, including bidirectional translation between natural language descriptions of skills and their corresponding rollout data. This grounding process enhances the LLM's comprehension of environmental dynamics, enabling it to generate diverse and meaningful imaginary rollouts that reflect novel skills. Initial empirical evaluations on the CLEVR-Robot environment demonstrate that KALM enables agents to complete complex rephrasings of task goals and extend their capabilities to novel tasks requiring unprecedented optimal behaviors. KALM achieves a success rate of 46% in executing tasks with unseen goals, substantially surpassing the 26% success rate achieved by baseline methods. Furthermore, KALM effectively enables the LLM to comprehend environmental dynamics, resulting in the generation of meaningful imaginary rollouts that reflect novel skills and demonstrate the seamless integration of large language models and reinforcement learning.
Episodic Return Decomposition by Difference of Implicitly Assigned Sub-Trajectory Reward
Dec 17, 2023



Real-world decision-making problems are usually accompanied by delayed rewards, which affects the sample efficiency of Reinforcement Learning, especially in the extremely delayed case where the only feedback is the episodic reward obtained at the end of an episode. Episodic return decomposition is a promising way to deal with the episodic-reward setting. Several corresponding algorithms have shown remarkable effectiveness of the learned step-wise proxy rewards from return decomposition. However, these existing methods lack either attribution or representation capacity, leading to inefficient decomposition in the case of long-term episodes. In this paper, we propose a novel episodic return decomposition method called Diaster (Difference of implicitly assigned sub-trajectory reward). Diaster decomposes any episodic reward into credits of two divided sub-trajectories at any cut point, and the step-wise proxy rewards come from differences in expectation. We theoretically and empirically verify that the decomposed proxy reward function can guide the policy to be nearly optimal. Experimental results show that our method outperforms previous state-of-the-art methods in terms of both sample efficiency and performance.
Model-based Reinforcement Learning with Multi-step Plan Value Estimation
Sep 12, 2022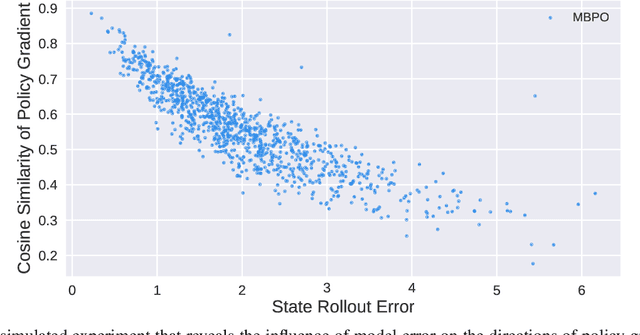
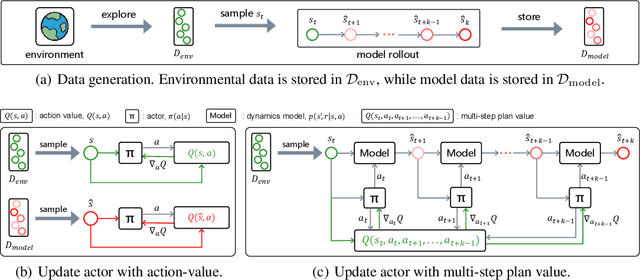
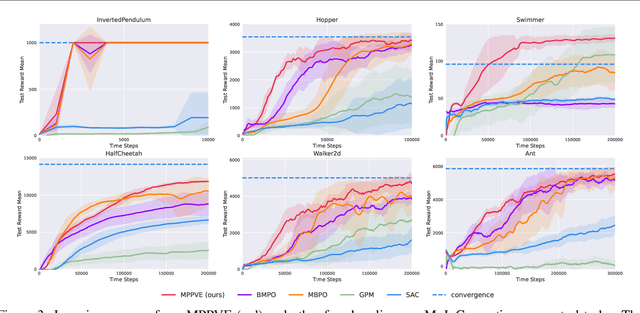
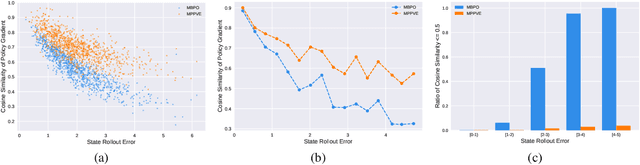
A promising way to improve the sample efficiency of reinforcement learning is model-based methods, in which many explorations and evaluations can happen in the learned models to save real-world samples. However, when the learned model has a non-negligible model error, sequential steps in the model are hard to be accurately evaluated, limiting the model's utilization. This paper proposes to alleviate this issue by introducing multi-step plans to replace multi-step actions for model-based RL. We employ the multi-step plan value estimation, which evaluates the expected discounted return after executing a sequence of action plans at a given state, and updates the policy by directly computing the multi-step policy gradient via plan value estimation. The new model-based reinforcement learning algorithm MPPVE (Model-based Planning Policy Learning with Multi-step Plan Value Estimation) shows a better utilization of the learned model and achieves a better sample efficiency than state-of-the-art model-based RL approaches.