 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Behavior Sequential Modeling with Transition-Aware Graph Attention Network for E-Commerce Recommendation
Jan 21, 2026User interactions on e-commerce platforms are inherently diverse, involving behaviors such as clicking, favoriting, adding to cart, and purchasing. The transitions between these behaviors offer valuable insights into user-item interactions, serving as a key signal for un- derstanding evolving preferences. Consequently, there is growing interest in leveraging multi-behavior data to better capture user intent. Recent studies have explored sequential modeling of multi- behavior data, many relying on transformer-based architectures with polynomial time complexity. While effective, these approaches often incur high computational costs, limiting their applicability in large-scale industrial systems with long user sequences. To address this challenge, we propose the Transition-Aware Graph Attention Network (TGA), a linear-complexity approach for modeling multi-behavior transitions. Unlike traditional trans- formers that treat all behavior pairs equally, TGA constructs a structured sparse graph by identifying informative transitions from three perspectives: (a) item-level transitions, (b) category-level transitions, and (c) neighbor-level transitions. Built upon the structured graph, TGA employs a transition-aware graph Attention mechanism that jointly models user-item interactions and behav- ior transition types, enabling more accurate capture of sequential patterns while maintaining computational efficiency. Experiments show that TGA outperforms all state-of-the-art models while sig- nificantly reducing computational cost. Notably, TGA has been deployed in a large-scale industrial production environment, where it leads to impressive improvements in key business metrics.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Document-Level Text Simplification: Dataset, Criteria and Baseline
Oct 11, 2021
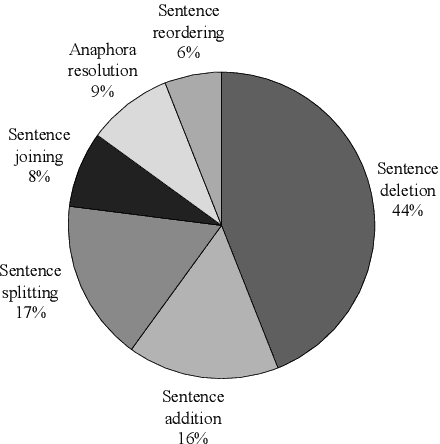


Text simplification is a valuable technique. However, current research is limited to sentence simplification. In this paper, we define and investigate a new task of document-level text simplification, which aims to simplify a document consisting of multiple sentences. Based on Wikipedia dumps, we first construct a large-scale dataset named D-Wikipedia and perform analysis and human evaluation on it to show that the dataset is reliable. Then, we propose a new automatic evaluation metric called D-SARI that is more suitable for the document-level simplification task. Finally, we select several representative models as baseline models for this task and perform automatic evaluation and human evaluation. We analyze the results and point out the shortcomings of the baseline models.