 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Interest-oriented Universal User Representation via Contrastive Learning
Sep 18, 2021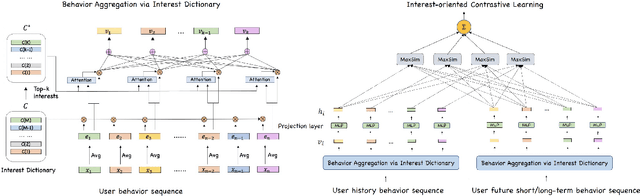
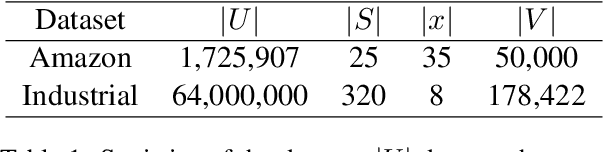
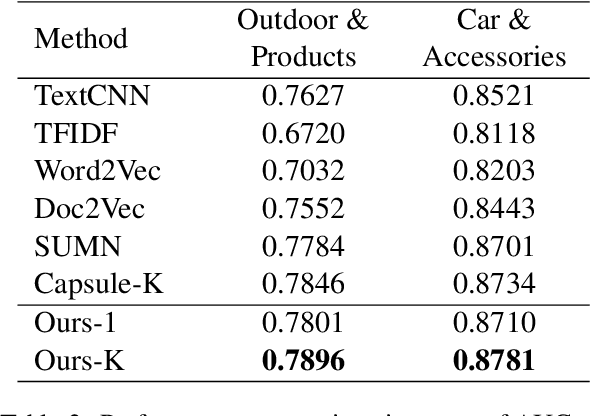
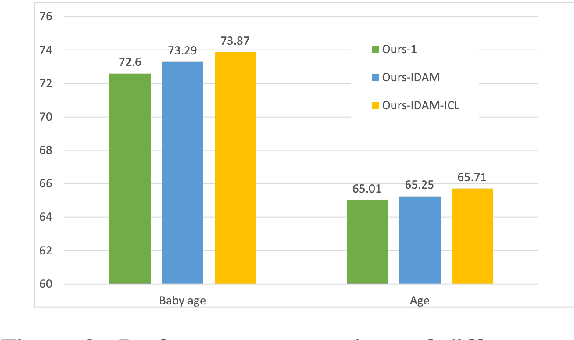
User representation is essential for providing high-quality commercial services in industry. Universal user representation has received many interests recently, with which we can be free from the cumbersome work of training a specific model for each downstream application. In this paper, we attempt to improve universal user representation from two points of views. First, a contrastive self-supervised learning paradigm is presented to guide the representation model training. It provides a unified framework that allows for long-term or short-term interest representation learning in a data-driven manner. Moreover, a novel multi-interest extraction module is presented. The module introduces an interest dictionary to capture principal interests of the given user, and then generate his/her interest-oriented representations via behavior aggregation. Experimental results demonstrate the effectiveness and applicability of the learned user representations.