 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023



We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
RT-1: Robotics Transformer for Real-World Control at Scale
Dec 13, 2022



By transferring knowledge from large, diverse, task-agnostic datasets, modern machine learning models can solve specific downstream tasks either zero-shot or with small task-specific datasets to a high level of performance. While this capability has been demonstrated in other fields such as computer vision, natural language processing or speech recognition, it remains to be shown in robotics, where the generalization capabilities of the models are particularly critical due to the difficulty of collecting real-world robotic data. We argue that one of the keys to the success of such general robotic models lies with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the diverse, robotic data. In this paper, we present a model class, dubbed Robotics Transformer, that exhibits promising scalable model properties. We verify our conclusions in a study of different model classes and their ability to generalize as a function of the data size, model size, and data diversity based on a large-scale data collection on real robots performing real-world tasks. The project's website and videos can be found at robotics-transformer.github.io
Token Turing Machines
Nov 16, 2022



We propose Token Turing Machines (TTM), a sequential, autoregressive Transformer model with memory for real-world sequential visual understanding. Our model is inspired by the seminal Neural Turing Machine, and has an external memory consisting of a set of tokens which summarise the previous history (i.e., frames). This memory is efficiently addressed, read and written using a Transformer as the processing unit/controller at each step. The model's memory module ensures that a new observation will only be processed with the contents of the memory (and not the entire history), meaning that it can efficiently process long sequences with a bounded computational cost at each step. We show that TTM outperforms other alternatives, such as other Transformer models designed for long sequences and recurrent neural networks, on two real-world sequential visual understanding tasks: online temporal activity detection from videos and vision-based robot action policy learning.
Open-vocabulary Queryable Scene Representations for Real World Planning
Sep 20, 2022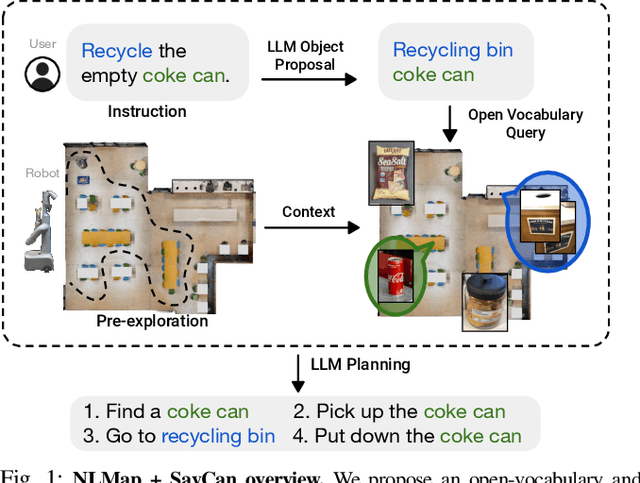
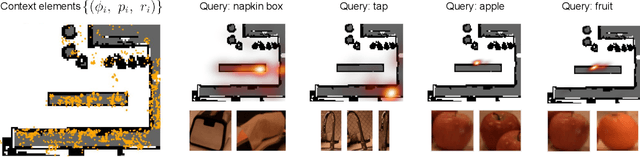
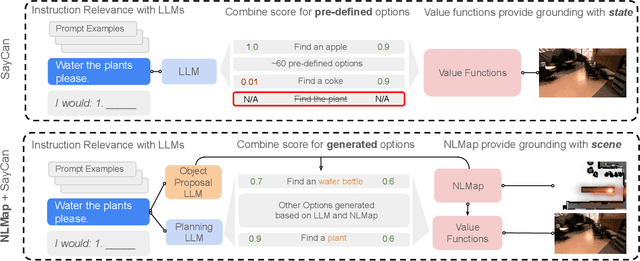
Large language models (LLMs) have unlocked new capabilities of task planning from human instructions. However, prior attempts to apply LLMs to real-world robotic tasks are limited by the lack of grounding in the surrounding scene. In this paper, we develop NLMap, an open-vocabulary and queryable scene representation to address this problem. NLMap serves as a framework to gather and integrate contextual information into LLM planners, allowing them to see and query available objects in the scene before generating a context-conditioned plan. NLMap first establishes a natural language queryable scene representation with Visual Language models (VLMs). An LLM based object proposal module parses instructions and proposes involved objects to query the scene representation for object availability and location. An LLM planner then plans with such information about the scene. NLMap allows robots to operate without a fixed list of objects nor executable options, enabling real robot operation unachievable by previous methods. Project website: https://nlmap-saycan.github.io
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Apr 04, 2022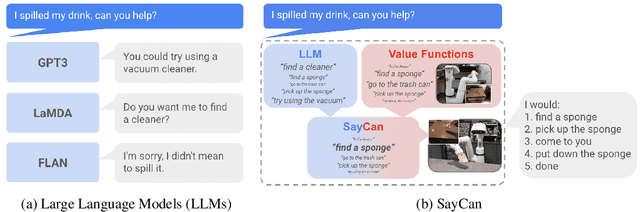
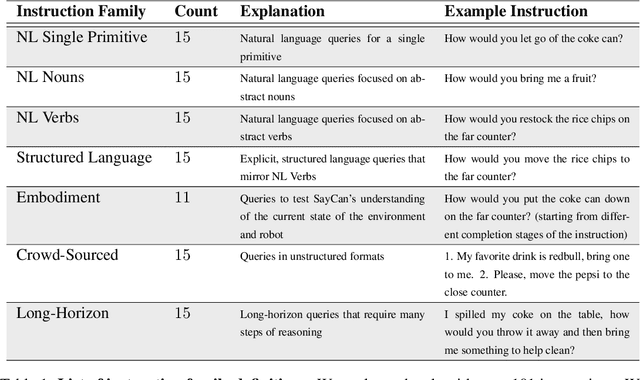
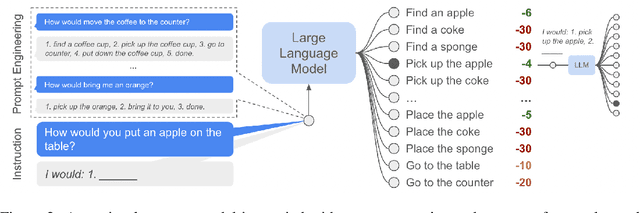
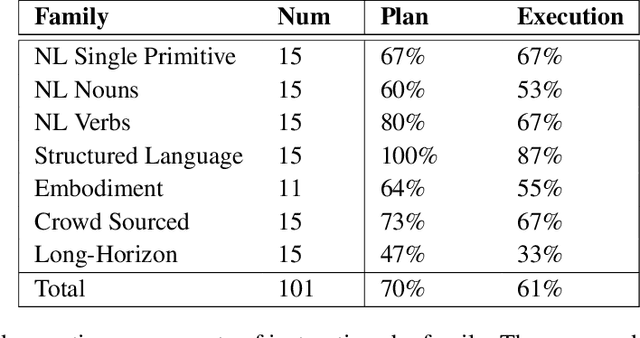
Large language models can encode a wealth of semantic knowledge about the world. Such knowledge could be extremely useful to robots aiming to act upon high-level, temporally extended instructions expressed in natural language. However, a significant weakness of language models is that they lack real-world experience, which makes it difficult to leverage them for decision making within a given embodiment. For example, asking a language model to describe how to clean a spill might result in a reasonable narrative, but it may not be applicable to a particular agent, such as a robot, that needs to perform this task in a particular environment. We propose to provide real-world grounding by means of pretrained skills, which are used to constrain the model to propose natural language actions that are both feasible and contextually appropriate. The robot can act as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task. We show how low-level skills can be combined with large language models so that the language model provides high-level knowledge about the procedures for performing complex and temporally-extended instructions, while value functions associated with these skills provide the grounding necessary to connect this knowledge to a particular physical environment. We evaluate our method on a number of real-world robotic tasks, where we show the need for real-world grounding and that this approach is capable of completing long-horizon, abstract, natural language instructions on a mobile manipulator. The project's website and the video can be found at https://say-can.github.io/
RetinaGAN: An Object-aware Approach to Sim-to-Real Transfer
Nov 06, 2020

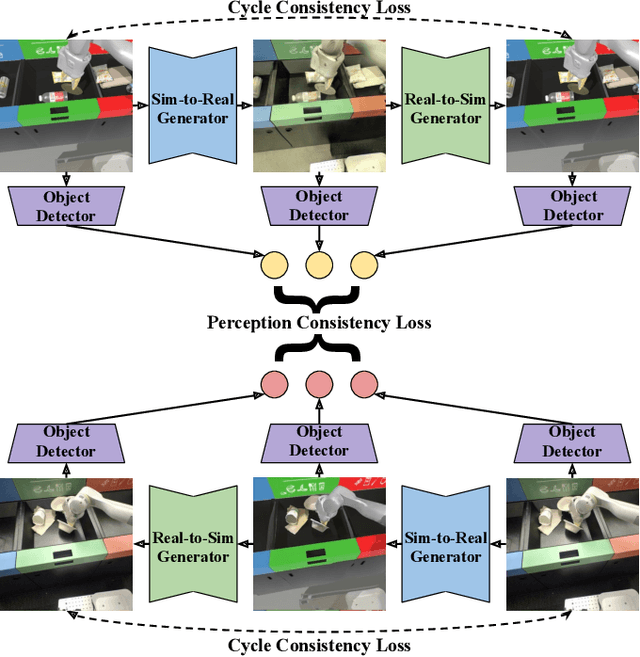
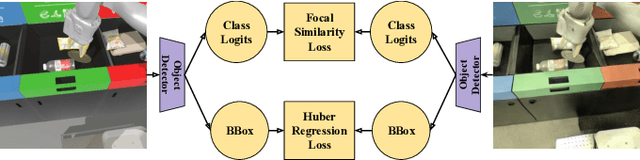
The success of deep reinforcement learning (RL) and imitation learning (IL) in vision-based robotic manipulation typically hinges on the expense of large scale data collection. With simulation, data to train a policy can be collected efficiently at scale, but the visual gap between sim and real makes deployment in the real world difficult. We introduce RetinaGAN, a generative adversarial network (GAN) approach to adapt simulated images to realistic ones with object-detection consistency. RetinaGAN is trained in an unsupervised manner without task loss dependencies, and preserves general object structure and texture in adapted images. We evaluate our method on three real world tasks: grasping, pushing, and door opening. RetinaGAN improves upon the performance of prior sim-to-real methods for RL-based object instance grasping and continues to be effective even in the limited data regime. When applied to a pushing task in a similar visual domain, RetinaGAN demonstrates transfer with no additional real data requirements. We also show our method bridges the visual gap for a novel door opening task using imitation learning in a new visual domain. Visit the project website at https://retinagan.github.io/
RL-CycleGAN: Reinforcement Learning Aware Simulation-To-Real
Jun 16, 2020
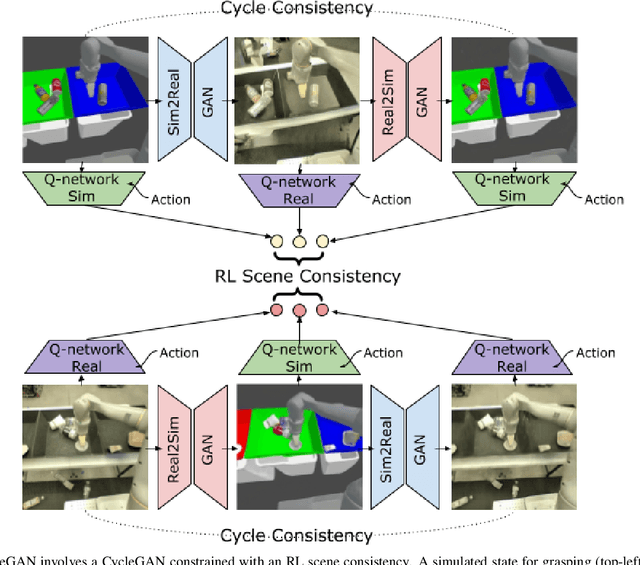


Deep neural network based reinforcement learning (RL) can learn appropriate visual representations for complex tasks like vision-based robotic grasping without the need for manually engineering or prior learning a perception system. However, data for RL is collected via running an agent in the desired environment, and for applications like robotics, running a robot in the real world may be extremely costly and time consuming. Simulated training offers an appealing alternative, but ensuring that policies trained in simulation can transfer effectively into the real world requires additional machinery. Simulations may not match reality, and typically bridging the simulation-to-reality gap requires domain knowledge and task-specific engineering. We can automate this process by employing generative models to translate simulated images into realistic ones. However, this sort of translation is typically task-agnostic, in that the translated images may not preserve all features that are relevant to the task. In this paper, we introduce the RL-scene consistency loss for image translation, which ensures that the translation operation is invariant with respect to the Q-values associated with the image. This allows us to learn a task-aware translation. Incorporating this loss into unsupervised domain translation, we obtain RL-CycleGAN, a new approach for simulation-to-real-world transfer for reinforcement learning. In evaluations of RL-CycleGAN on two vision-based robotics grasping tasks, we show that RL-CycleGAN offers a substantial improvement over a number of prior methods for sim-to-real transfer, attaining excellent real-world performance with only a modest number of real-world observations.
Off-Policy Evaluation via Off-Policy Classification
Jun 20, 2019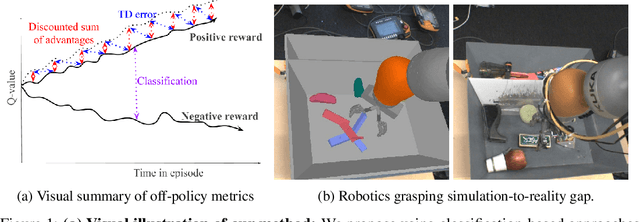

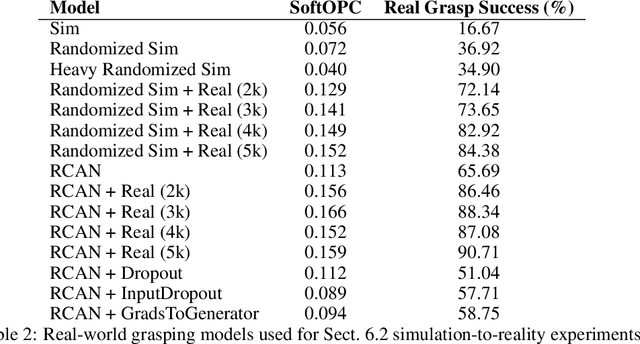

In this work, we consider the problem of model selection for deep reinforcement learning (RL) in real-world environments. Typically, the performance of deep RL algorithms is evaluated via on-policy interactions with the target environment. However, comparing models in a real-world environment for the purposes of early stopping or hyperparameter tuning is costly and often practically infeasible. This leads us to examine off-policy policy evaluation (OPE) in such settings. We focus on OPE for value-based methods, which are of particular interest in deep RL, with applications like robotics, where off-policy algorithms based on Q-function estimation can often attain better sample complexity than direct policy optimization. Existing OPE metrics either rely on a model of the environment, or the use of importance sampling (IS) to correct for the data being off-policy. However, for high-dimensional observations, such as images, models of the environment can be difficult to fit and value-based methods can make IS hard to use or even ill-conditioned, especially when dealing with continuous action spaces. In this paper, we focus on the specific case of MDPs with continuous action spaces and sparse binary rewards, which is representative of many important real-world applications. We propose an alternative metric that relies on neither models nor IS, by framing OPE as a positive-unlabeled (PU) classification problem with the Q-function as the decision function. We experimentally show that this metric outperforms baselines on a number of tasks. Most importantly, it can reliably predict the relative performance of different policies in a number of generalization scenarios, including the transfer to the real-world of policies trained in simulation for an image-based robotic manipulation task.
Federated Learning for Emoji Prediction in a Mobile Keyboard
Jun 11, 2019

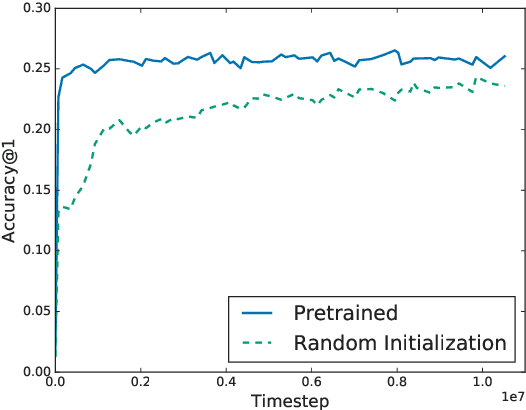
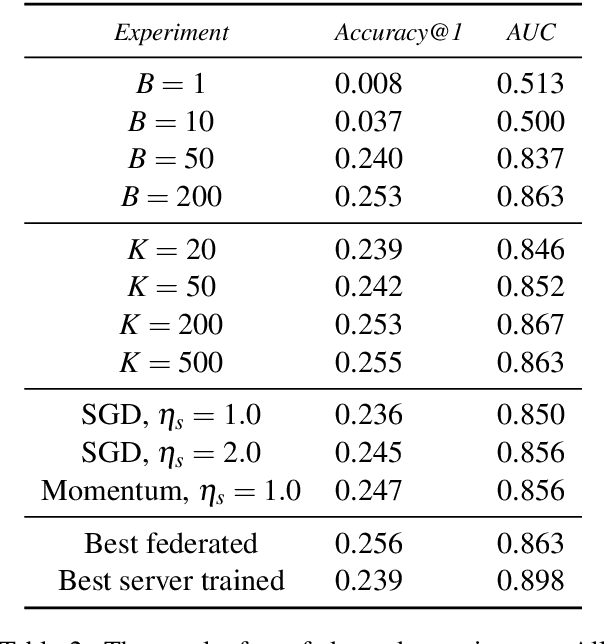
We show that a word-level recurrent neural network can predict emoji from text typed on a mobile keyboard. We demonstrate the usefulness of transfer learning for predicting emoji by pretraining the model using a language modeling task. We also propose mechanisms to trigger emoji and tune the diversity of candidates. The model is trained using a distributed on-device learning framework called federated learning. The federated model is shown to achieve better performance than a server-trained model. This work demonstrates the feasibility of using federated learning to train production-quality models for natural language understanding tasks while keeping users' data on their devices.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.