 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023



We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
Open-vocabulary Queryable Scene Representations for Real World Planning
Sep 20, 2022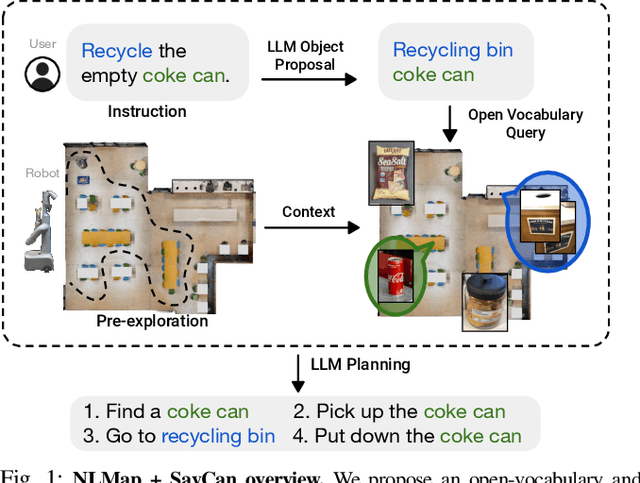
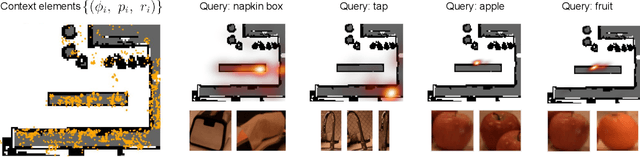
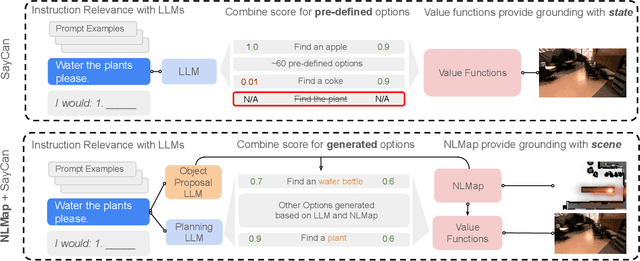
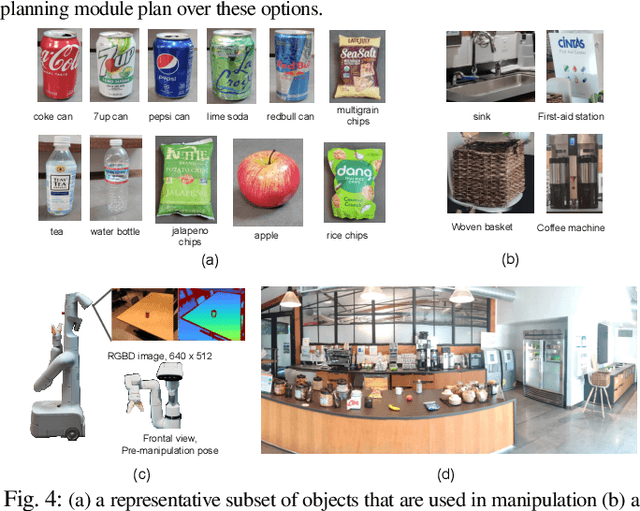
Large language models (LLMs) have unlocked new capabilities of task planning from human instructions. However, prior attempts to apply LLMs to real-world robotic tasks are limited by the lack of grounding in the surrounding scene. In this paper, we develop NLMap, an open-vocabulary and queryable scene representation to address this problem. NLMap serves as a framework to gather and integrate contextual information into LLM planners, allowing them to see and query available objects in the scene before generating a context-conditioned plan. NLMap first establishes a natural language queryable scene representation with Visual Language models (VLMs). An LLM based object proposal module parses instructions and proposes involved objects to query the scene representation for object availability and location. An LLM planner then plans with such information about the scene. NLMap allows robots to operate without a fixed list of objects nor executable options, enabling real robot operation unachievable by previous methods. Project website: https://nlmap-saycan.github.io
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
Feb 04, 2022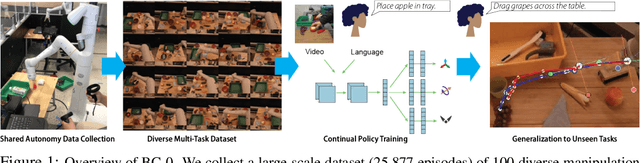
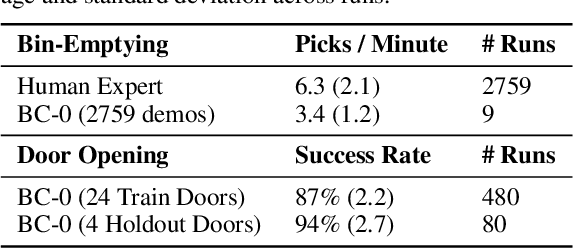

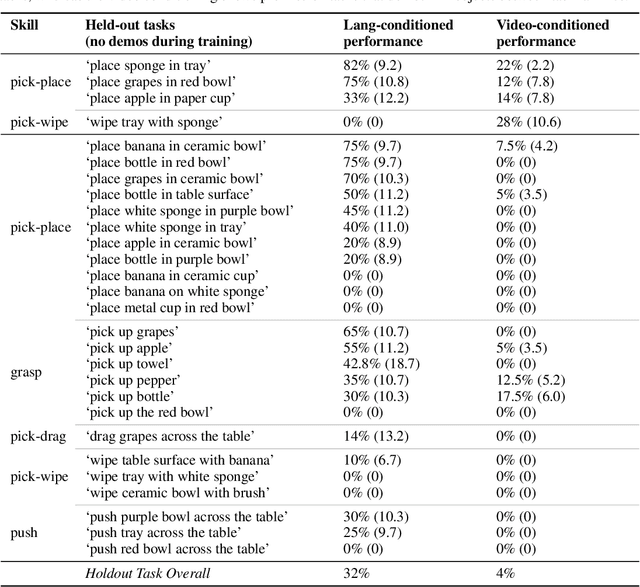
In this paper, we study the problem of enabling a vision-based robotic manipulation system to generalize to novel tasks, a long-standing challenge in robot learning. We approach the challenge from an imitation learning perspective, aiming to study how scaling and broadening the data collected can facilitate such generalization. To that end, we develop an interactive and flexible imitation learning system that can learn from both demonstrations and interventions and can be conditioned on different forms of information that convey the task, including pre-trained embeddings of natural language or videos of humans performing the task. When scaling data collection on a real robot to more than 100 distinct tasks, we find that this system can perform 24 unseen manipulation tasks with an average success rate of 44%, without any robot demonstrations for those tasks.
* CoRL 2021, 23 pages
Action Image Representation: Learning Scalable Deep Grasping Policies with Zero Real World Data
May 13, 2020

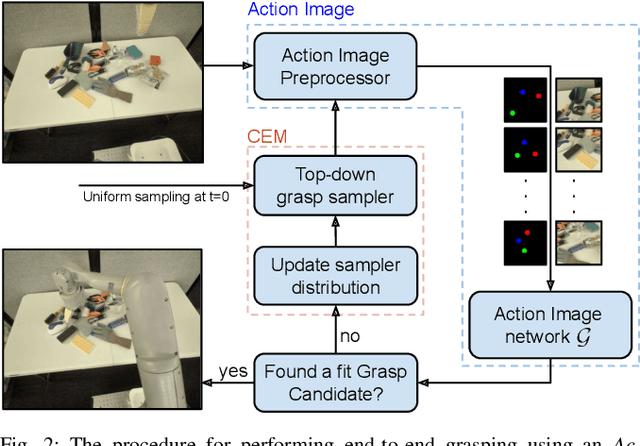
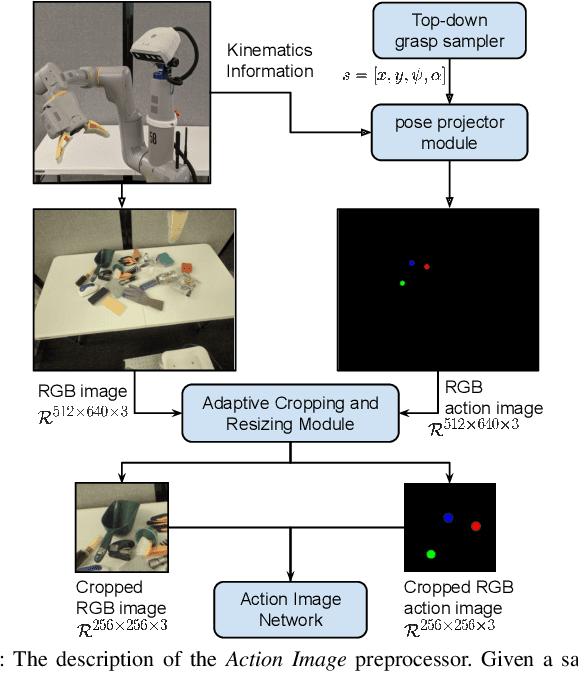
This paper introduces Action Image, a new grasp proposal representation that allows learning an end-to-end deep-grasping policy. Our model achieves $84\%$ grasp success on $172$ real world objects while being trained only in simulation on $48$ objects with just naive domain randomization. Similar to computer vision problems, such as object detection, Action Image builds on the idea that object features are invariant to translation in image space. Therefore, grasp quality is invariant when evaluating the object-gripper relationship; a successful grasp for an object depends on its local context, but is independent of the surrounding environment. Action Image represents a grasp proposal as an image and uses a deep convolutional network to infer grasp quality. We show that by using an Action Image representation, trained networks are able to extract local, salient features of grasping tasks that generalize across different objects and environments. We show that this representation works on a variety of inputs, including color images (RGB), depth images (D), and combined color-depth (RGB-D). Our experimental results demonstrate that networks utilizing an Action Image representation exhibit strong domain transfer between training on simulated data and inference on real-world sensor streams. Finally, our experiments show that a network trained with Action Image improves grasp success ($84\%$ vs. $53\%$) over a baseline model with the same structure, but using actions encoded as vectors.
Scalable Multi-Task Imitation Learning with Autonomous Improvement
Feb 25, 2020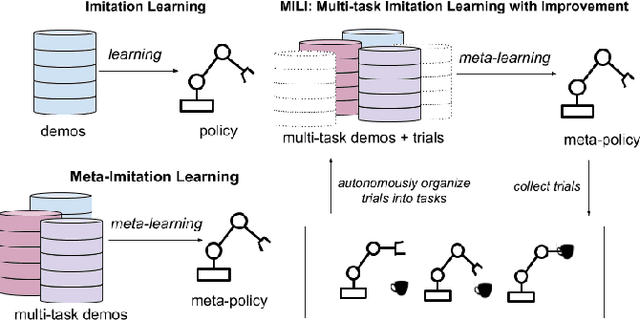
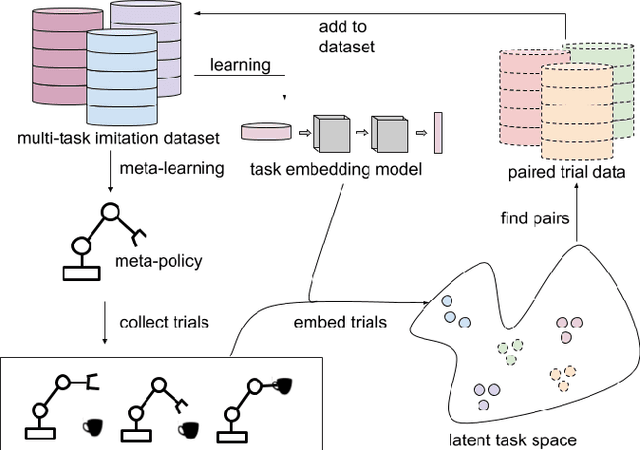

While robot learning has demonstrated promising results for enabling robots to automatically acquire new skills, a critical challenge in deploying learning-based systems is scale: acquiring enough data for the robot to effectively generalize broadly. Imitation learning, in particular, has remained a stable and powerful approach for robot learning, but critically relies on expert operators for data collection. In this work, we target this challenge, aiming to build an imitation learning system that can continuously improve through autonomous data collection, while simultaneously avoiding the explicit use of reinforcement learning, to maintain the stability, simplicity, and scalability of supervised imitation. To accomplish this, we cast the problem of imitation with autonomous improvement into a multi-task setting. We utilize the insight that, in a multi-task setting, a failed attempt at one task might represent a successful attempt at another task. This allows us to leverage the robot's own trials as demonstrations for tasks other than the one that the robot actually attempted. Using an initial dataset of multi-task demonstration data, the robot autonomously collects trials which are only sparsely labeled with a binary indication of whether the trial accomplished any useful task or not. We then embed the trials into a learned latent space of tasks, trained using only the initial demonstration dataset, to draw similarities between various trials, enabling the robot to achieve one-shot generalization to new tasks. In contrast to prior imitation learning approaches, our method can autonomously collect data with sparse supervision for continuous improvement, and in contrast to reinforcement learning algorithms, our method can effectively improve from sparse, task-agnostic reward signals.
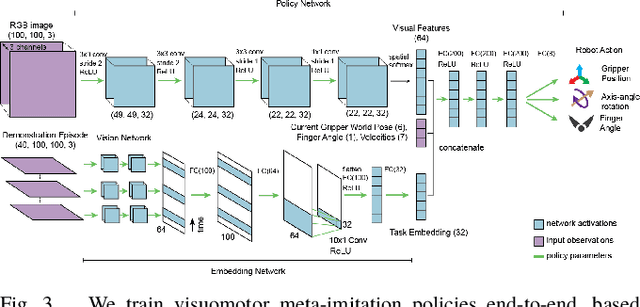
Watch, Try, Learn: Meta-Learning from Demonstrations and Reward
Jun 07, 2019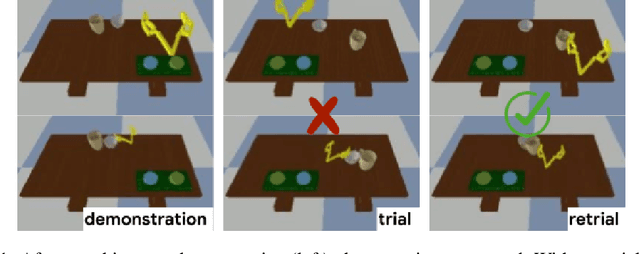
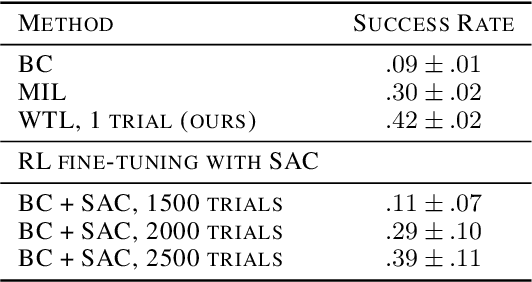
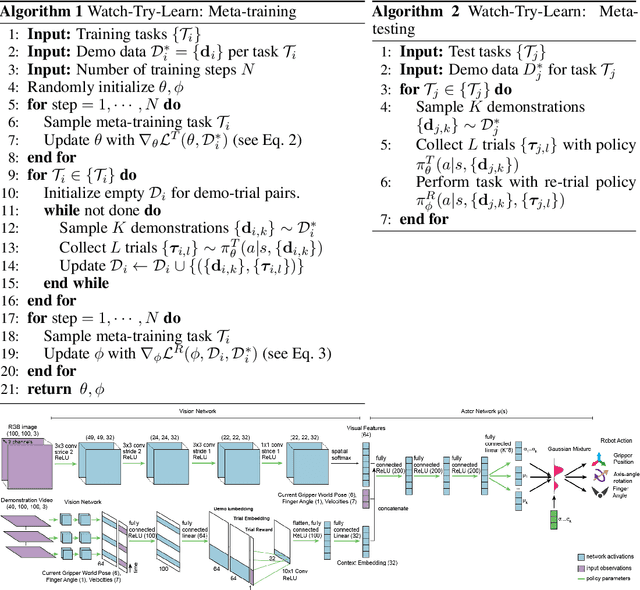
Imitation learning allows agents to learn complex behaviors from demonstrations. However, learning a complex vision-based task may require an impractical number of demonstrations. Meta-imitation learning is a promising approach towards enabling agents to learn a new task from one or a few demonstrations by leveraging experience from learning similar tasks. In the presence of task ambiguity or unobserved dynamics, demonstrations alone may not provide enough information; an agent must also try the task to successfully infer a policy. In this work, we propose a method that can learn to learn from both demonstrations and trial-and-error experience with sparse reward feedback. In comparison to meta-imitation, this approach enables the agent to effectively and efficiently improve itself autonomously beyond the demonstration data. In comparison to meta-reinforcement learning, we can scale to substantially broader distributions of tasks, as the demonstration reduces the burden of exploration. Our experiments show that our method significantly outperforms prior approaches on a set of challenging, vision-based control tasks.
Leveraging Contact Forces for Learning to Grasp
Sep 19, 2018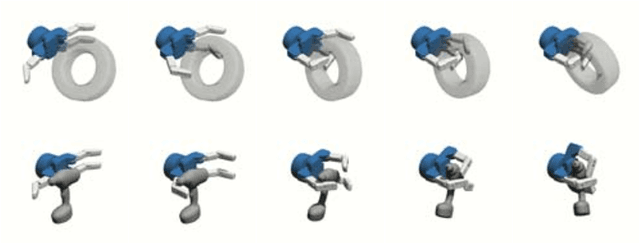


Grasping objects under uncertainty remains an open problem in robotics research. This uncertainty is often due to noisy or partial observations of the object pose or shape. To enable a robot to react appropriately to unforeseen effects, it is crucial that it continuously takes sensor feedback into account. While visual feedback is important for inferring a grasp pose and reaching for an object, contact feedback offers valuable information during manipulation and grasp acquisition. In this paper, we use model-free deep reinforcement learning to synthesize control policies that exploit contact sensing to generate robust grasping under uncertainty. We demonstrate our approach on a multi-fingered hand that exhibits more complex finger coordination than the commonly used two-fingered grippers. We conduct extensive experiments in order to assess the performance of the learned policies, with and without contact sensing. While it is possible to learn grasping policies without contact sensing, our results suggest that contact feedback allows for a significant improvement of grasping robustness under object pose uncertainty and for objects with a complex shape.