 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering LLMs for Culturally Localized Generation
Mar 24, 2026LLMs are deployed globally, yet produce responses biased towards cultures with abundant training data. Existing cultural localization approaches such as prompting or post-training alignment are black-box, hard to control, and do not reveal whether failures reflect missing knowledge or poor elicitation. In this paper, we address these gaps using mechanistic interpretability to uncover and manipulate cultural representations in LLMs. Leveraging sparse autoencoders, we identify interpretable features that encode culturally salient information and aggregate them into Cultural Embeddings (CuE). We use CuE both to analyze implicit cultural biases under underspecified prompts and to construct white-box steering interventions. Across multiple models, we show that CuE-based steering increases cultural faithfulness and elicits significantly rarer, long-tail cultural concepts than prompting alone. Notably, CuE-based steering is complementary to black-box localization methods, offering gains when applied on top of prompt-augmented inputs. This also suggests that models do benefit from better elicitation strategies, and don't necessarily lack long-tail knowledge representation, though this varies across cultures. Our results provide both diagnostic insight into cultural representations in LLMs and a controllable method to steer towards desired cultures.
MUSIC: MUlti-Step Instruction Contrast for Multi-Turn Reward Models
Dec 31, 2025Evaluating the quality of multi-turn conversations is crucial for developing capable Large Language Models (LLMs), yet remains a significant challenge, often requiring costly human evaluation. Multi-turn reward models (RMs) offer a scalable alternative and can provide valuable signals for guiding LLM training. While recent work has advanced multi-turn \textit{training} techniques, effective automated \textit{evaluation} specifically for multi-turn interactions lags behind. We observe that standard preference datasets, typically contrasting responses based only on the final conversational turn, provide insufficient signal to capture the nuances of multi-turn interactions. Instead, we find that incorporating contrasts spanning \textit{multiple} turns is critical for building robust multi-turn RMs. Motivated by this finding, we propose \textbf{MU}lti-\textbf{S}tep \textbf{I}nstruction \textbf{C}ontrast (MUSIC), an unsupervised data augmentation strategy that synthesizes contrastive conversation pairs exhibiting differences across multiple turns. Leveraging MUSIC on the Skywork preference dataset, we train a multi-turn RM based on the Gemma-2-9B-Instruct model. Empirical results demonstrate that our MUSIC-augmented RM outperforms baseline methods, achieving higher alignment with judgments from advanced proprietary LLM judges on multi-turn conversations, crucially, without compromising performance on standard single-turn RM benchmarks.
Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process
Dec 30, 2025Despite the growing reasoning capabilities of recent large language models (LLMs), their internal mechanisms during the reasoning process remain underexplored. Prior approaches often rely on human-defined concepts (e.g., overthinking, reflection) at the word level to analyze reasoning in a supervised manner. However, such methods are limited, as it is infeasible to capture the full spectrum of potential reasoning behaviors, many of which are difficult to define in token space. In this work, we propose an unsupervised framework (namely, RISE: Reasoning behavior Interpretability via Sparse auto-Encoder) for discovering reasoning vectors, which we define as directions in the activation space that encode distinct reasoning behaviors. By segmenting chain-of-thought traces into sentence-level 'steps' and training sparse auto-encoders (SAEs) on step-level activations, we uncover disentangled features corresponding to interpretable behaviors such as reflection and backtracking. Visualization and clustering analyses show that these behaviors occupy separable regions in the decoder column space. Moreover, targeted interventions on SAE-derived vectors can controllably amplify or suppress specific reasoning behaviors, altering inference trajectories without retraining. Beyond behavior-specific disentanglement, SAEs capture structural properties such as response length, revealing clusters of long versus short reasoning traces. More interestingly, SAEs enable the discovery of novel behaviors beyond human supervision. We demonstrate the ability to control response confidence by identifying confidence-related vectors in the SAE decoder space. These findings underscore the potential of unsupervised latent discovery for both interpreting and controllably steering reasoning in LLMs.
Eliciting Behaviors in Multi-Turn Conversations
Dec 29, 2025Identifying specific and often complex behaviors from large language models (LLMs) in conversational settings is crucial for their evaluation. Recent work proposes novel techniques to find natural language prompts that induce specific behaviors from a target model, yet they are mainly studied in single-turn settings. In this work, we study behavior elicitation in the context of multi-turn conversations. We first offer an analytical framework that categorizes existing methods into three families based on their interactions with the target model: those that use only prior knowledge, those that use offline interactions, and those that learn from online interactions. We then introduce a generalized multi-turn formulation of the online method, unifying single-turn and multi-turn elicitation. We evaluate all three families of methods on automatically generating multi-turn test cases. We investigate the efficiency of these approaches by analyzing the trade-off between the query budget, i.e., the number of interactions with the target model, and the success rate, i.e., the discovery rate of behavior-eliciting inputs. We find that online methods can achieve an average success rate of 45/19/77% with just a few thousand queries over three tasks where static methods from existing multi-turn conversation benchmarks find few or even no failure cases. Our work highlights a novel application of behavior elicitation methods in multi-turn conversation evaluation and the need for the community to move towards dynamic benchmarks.
Parameter-Efficient Transfer Learning under Federated Learning for Automatic Speech Recognition
Aug 19, 2024



This work explores the challenge of enhancing Automatic Speech Recognition (ASR) model performance across various user-specific domains while preserving user data privacy. We employ federated learning and parameter-efficient domain adaptation methods to solve the (1) massive data requirement of ASR models from user-specific scenarios and (2) the substantial communication cost between servers and clients during federated learning. We demonstrate that when equipped with proper adapters, ASR models under federated tuning can achieve similar performance compared with centralized tuning ones, thus providing a potential direction for future privacy-preserved ASR services. Besides, we investigate the efficiency of different adapters and adapter incorporation strategies under the federated learning setting.
Learning from straggler clients in federated learning
Mar 14, 2024



How well do existing federated learning algorithms learn from client devices that return model updates with a significant time delay? Is it even possible to learn effectively from clients that report back minutes, hours, or days after being scheduled? We answer these questions by developing Monte Carlo simulations of client latency that are guided by real-world applications. We study synchronous optimization algorithms like FedAvg and FedAdam as well as the asynchronous FedBuff algorithm, and observe that all these existing approaches struggle to learn from severely delayed clients. To improve upon this situation, we experiment with modifications, including distillation regularization and exponential moving averages of model weights. Finally, we introduce two new algorithms, FARe-DUST and FeAST-on-MSG, based on distillation and averaging, respectively. Experiments with the EMNIST, CIFAR-100, and StackOverflow benchmark federated learning tasks demonstrate that our new algorithms outperform existing ones in terms of accuracy for straggler clients, while also providing better trade-offs between training time and total accuracy.
Unintended Memorization in Large ASR Models, and How to Mitigate It
Oct 18, 2023



It is well-known that neural networks can unintentionally memorize their training examples, causing privacy concerns. However, auditing memorization in large non-auto-regressive automatic speech recognition (ASR) models has been challenging due to the high compute cost of existing methods such as hardness calibration. In this work, we design a simple auditing method to measure memorization in large ASR models without the extra compute overhead. Concretely, we speed up randomly-generated utterances to create a mapping between vocal and text information that is difficult to learn from typical training examples. Hence, accurate predictions only for sped-up training examples can serve as clear evidence for memorization, and the corresponding accuracy can be used to measure memorization. Using the proposed method, we showcase memorization in the state-of-the-art ASR models. To mitigate memorization, we tried gradient clipping during training to bound the influence of any individual example on the final model. We empirically show that clipping each example's gradient can mitigate memorization for sped-up training examples with up to 16 repetitions in the training set. Furthermore, we show that in large-scale distributed training, clipping the average gradient on each compute core maintains neutral model quality and compute cost while providing strong privacy protection.
Heterogeneous Federated Learning Using Knowledge Codistillation
Oct 04, 2023



Federated Averaging, and many federated learning algorithm variants which build upon it, have a limitation: all clients must share the same model architecture. This results in unused modeling capacity on many clients, which limits model performance. To address this issue, we propose a method that involves training a small model on the entire pool and a larger model on a subset of clients with higher capacity. The models exchange information bidirectionally via knowledge distillation, utilizing an unlabeled dataset on a server without sharing parameters. We present two variants of our method, which improve upon federated averaging on image classification and language modeling tasks. We show this technique can be useful even if only out-of-domain or limited in-domain distillation data is available. Additionally, the bi-directional knowledge distillation allows for domain transfer between the models when different pool populations introduce domain shift.
The Gift of Feedback: Improving ASR Model Quality by Learning from User Corrections through Federated Learning
Sep 29, 2023Automatic speech recognition (ASR) models are typically trained on large datasets of transcribed speech. As language evolves and new terms come into use, these models can become outdated and stale. In the context of models trained on the server but deployed on edge devices, errors may result from the mismatch between server training data and actual on-device usage. In this work, we seek to continually learn from on-device user corrections through Federated Learning (FL) to address this issue. We explore techniques to target fresh terms that the model has not previously encountered, learn long-tail words, and mitigate catastrophic forgetting. In experimental evaluations, we find that the proposed techniques improve model recognition of fresh terms, while preserving quality on the overall language distribution.
Recycling Scraps: Improving Private Learning by Leveraging Intermediate Checkpoints
Oct 04, 2022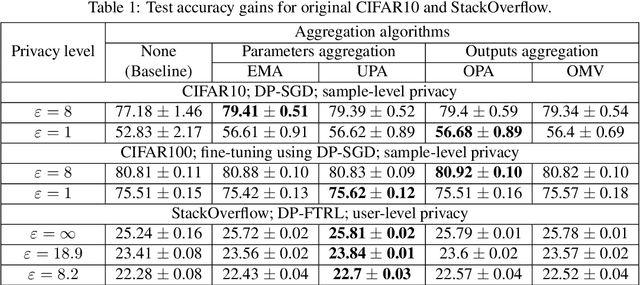
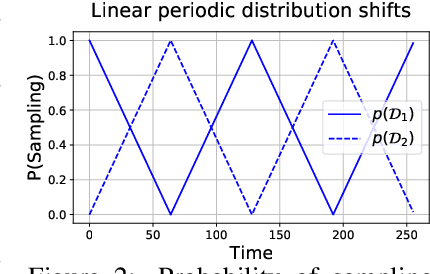
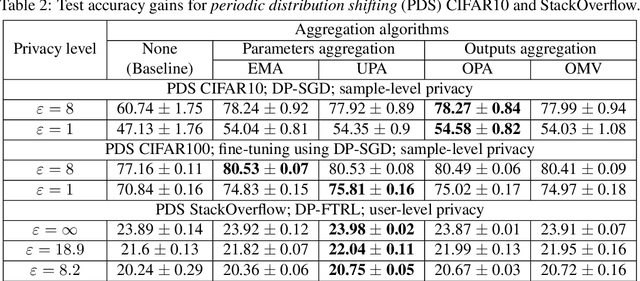
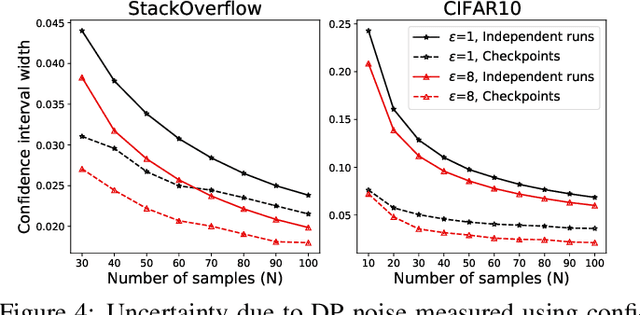
All state-of-the-art (SOTA) differentially private machine learning (DP ML) methods are iterative in nature, and their privacy analyses allow publicly releasing the intermediate training checkpoints. However, DP ML benchmarks, and even practical deployments, typically use only the final training checkpoint to make predictions. In this work, for the first time, we comprehensively explore various methods that aggregate intermediate checkpoints to improve the utility of DP training. Empirically, we demonstrate that checkpoint aggregations provide significant gains in the prediction accuracy over the existing SOTA for CIFAR10 and StackOverflow datasets, and that these gains get magnified in settings with periodically varying training data distributions. For instance, we improve SOTA StackOverflow accuracies to 22.7% (+0.43% absolute) for $\epsilon=8.2$, and 23.84% (+0.43%) for $\epsilon=18.9$. Theoretically, we show that uniform tail averaging of checkpoints improves the empirical risk minimization bound compared to the last checkpoint of DP-SGD. Lastly, we initiate an exploration into estimating the uncertainty that DP noise adds in the predictions of DP ML models. We prove that, under standard assumptions on the loss function, the sample variance from last few checkpoints provides a good approximation of the variance of the final model of a DP run. Empirically, we show that the last few checkpoints can provide a reasonable lower bound for the variance of a converged DP model.