 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Multimodal Learning for Interpretable Property Energy Performance Prediction and Retrofit Scenario Analysis
May 06, 2026Achieving resilient and sustainable cities requires scalable approaches to decarbonising residential buildings, which account for about 20% of UK greenhouse gas emissions and 25% of energy-related emissions in the European Union. Energy Performance Certificates (EPCs) support regulation and retrofit planning, but their reliance on on-site inspections limits timely city-scale assessment. This study introduces a gated multimodal model to predict Standard Assessment Procedure (SAP) energy efficiency and Environmental Impact (EI) scores by integrating EPC tabular variables, assessor-written free text, and Geographic Information System (GIS)-derived spatial features describing footprint geometry, height, area, and orientation. Sample-wise gating learns property-specific modality weights, while an auxiliary band classification head stabilises training. In a Westminster, London case study, the model predicts SAP and EI scores with MAEs of 4.03 and 4.76 points and R2 values of 0.757 and 0.748, respectively, achieving a mean MAE of 4.39. Ablation results show that full multimodal fusion outperforms unimodal and bimodal baselines for both score prediction and band-level classification. Interpretability analyses provide decision-relevant evidence: gating weights indicate strong reliance on assessor text; SHAP highlights main fuel, built form, and construction age band; text occlusion prioritises roof and wall fields; and spatial attribution is dominated by height and footprint area, with sensitivity to footprint shape. The validated framework is further applied to retrofit scenarios for wall insulation, roof insulation, and window glazing upgrades, indicating projected improvements in SAP, EI, annual energy cost, and equivalent CO2 emissions. Overall, the framework provides scalable property-level evidence for retrofit screening, intervention prioritisation, and net-zero housing transitions.
Chart-RL: Policy Optimization Reinforcement Learning for Enhanced Visual Reasoning in Chart Question Answering with Vision Language Models
Apr 03, 2026The recent advancements in Vision Language Models (VLMs) have demonstrated progress toward true intelligence requiring robust reasoning capabilities. Beyond pattern recognition, linguistic reasoning must integrate with visual comprehension, particularly for Chart Question Answering (CQA) tasks involving complex data visualizations. Current VLMs face significant limitations in CQA, including imprecise numerical extraction, difficulty interpreting implicit visual relationships, and inadequate attention mechanisms for capturing spatial relationships in charts. In this work, we address these challenges by presenting Chart-RL, a novel reinforcement learning framework that enhances VLMs chart understanding through feedback-driven policy optimization of visual perception and logical inference. Our key innovation includes a comprehensive framework integrating Reinforcement Learning (RL) from Policy Optimization techniques along with adaptive reward functions, that demonstrates superior performance compared to baseline foundation models and competitive results against larger state-of-the-art architectures. We also integrated Parameter-Efficient Fine-Tuning through Low-Rank Adaptation (LoRA) in the RL framework that only requires single GPU configurations while preserving performance integrity. We conducted extensive benchmarking across open-source, proprietary, and state-of-the-art closed-source models utilizing the ChartQAPro dataset. The RL fine-tuned Qwen3-VL-4B-Instruct model achieved an answer accuracy of 0.634, surpassing the 0.580 accuracy of the Qwen3-VL-8B-Instruct foundation model despite utilizing half the parameter count, while simultaneously reducing inference latency from 31 seconds to 9 seconds.
MedCausalX: Adaptive Causal Reasoning with Self-Reflection for Trustworthy Medical Vision-Language Models
Mar 24, 2026Vision-Language Models (VLMs) have enabled interpretable medical diagnosis by integrating visual perception with linguistic reasoning. Yet, existing medical chain-of-thought (CoT) models lack explicit mechanisms to represent and enforce causal reasoning, leaving them vulnerable to spurious correlations and limiting their clinical reliability. We pinpoint three core challenges in medical CoT reasoning: how to adaptively trigger causal correction, construct high-quality causal-spurious contrastive samples, and maintain causal consistency across reasoning trajectories. To address these challenges, we propose MedCausalX, an end-to-end framework explicitly models causal reasoning chains in medical VLMs. We first introduce the CRMed dataset providing fine-grained anatomical annotations, structured causal reasoning chains, and counterfactual variants that guide the learning of causal relationships beyond superficial correlations. Building upon CRMed, MedCausalX employs a two-stage adaptive reflection architecture equipped with $\langle$causal$\rangle$ and $\langle$verify$\rangle$ tokens, enabling the model to autonomously determine when and how to perform causal analysis and verification. Finally, a trajectory-level causal correction objective optimized through error-attributed reinforcement learning refines the reasoning chain, allowing the model to distinguish genuine causal dependencies from shortcut associations. Extensive experiments on multiple benchmarks show that MedCausalX consistently outperforms state-of-the-art methods, improving diagnostic consistency by +5.4 points, reducing hallucination by over 10 points, and attaining top spatial grounding IoU, thereby setting a new standard for causally grounded medical reasoning.
SQL-Trail: Multi-Turn Reinforcement Learning with Interleaved Feedback for Text-to-SQL
Jan 25, 2026While large language models (LLMs) have substantially improved Text-to-SQL generation, a pronounced gap remains between AI systems and human experts on challenging benchmarks such as BIRD-SQL. We argue this gap stems largely from the prevailing single-pass paradigm, which lacks the iterative reasoning, schema exploration, and error-correction behaviors that humans naturally employ. To address this limitation, we introduce SQL-Trail, a multi-turn reinforcement learning (RL) agentic framework for Text-to-SQL. Rather than producing a query in one shot, SQL-Trail interacts with the database environment and uses execution feedback to iteratively refine its predictions. Our approach centers on two key ideas: (i) an adaptive turn-budget allocation mechanism that scales the agent's interaction depth to match question difficulty, and (ii) a composite reward panel that jointly incentivizes SQL correctness and efficient exploration. Across benchmarks, SQL-Trail sets a new state of the art and delivers strong data efficiency--up to 18x higher than prior single-pass RL state-of-the-art methods. Notably, our 7B and 14B models outperform substantially larger proprietary systems by 5% on average, underscoring the effectiveness of interactive, agentic workflows for robust Text-to-SQL generation.
An Explainable Natural Language Framework for Identifying and Notifying Target Audiences In Enterprise Communication
Aug 07, 2025In large-scale maintenance organizations, identifying subject matter experts and managing communications across complex entities relationships poses significant challenges -- including information overload and longer response times -- that traditional communication approaches fail to address effectively. We propose a novel framework that combines RDF graph databases with LLMs to process natural language queries for precise audience targeting, while providing transparent reasoning through a planning-orchestration architecture. Our solution enables communication owners to formulate intuitive queries combining concepts such as equipment, manufacturers, maintenance engineers, and facilities, delivering explainable results that maintain trust in the system while improving communication efficiency across the organization.
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023



We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
On Designing a Learning Robot: Improving Morphology for Enhanced Task Performance and Learning
Mar 23, 2023As robots become more prevalent, optimizing their design for better performance and efficiency is becoming increasingly important. However, current robot design practices overlook the impact of perception and design choices on a robot's learning capabilities. To address this gap, we propose a comprehensive methodology that accounts for the interplay between the robot's perception, hardware characteristics, and task requirements. Our approach optimizes the robot's morphology holistically, leading to improved learning and task execution proficiency. To achieve this, we introduce a Morphology-AGnostIc Controller (MAGIC), which helps with the rapid assessment of different robot designs. The MAGIC policy is efficiently trained through a novel PRIvileged Single-stage learning via latent alignMent (PRISM) framework, which also encourages behaviors that are typical of robot onboard observation. Our simulation-based results demonstrate that morphologies optimized holistically improve the robot performance by 15-20% on various manipulation tasks, and require 25x less data to match human-expert made morphology performance. In summary, our work contributes to the growing trend of learning-based approaches in robotics and emphasizes the potential in designing robots that facilitate better learning.
Practical Imitation Learning in the Real World via Task Consistency Loss
Feb 03, 2022

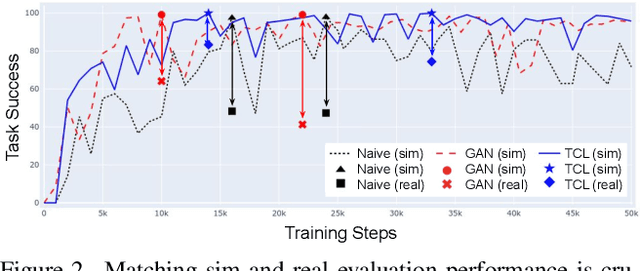
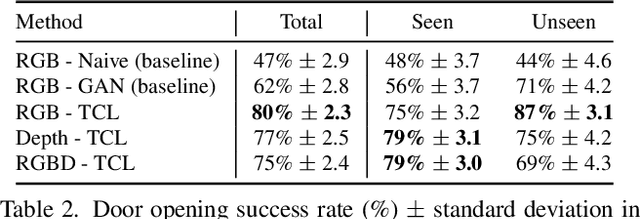
Recent work in visual end-to-end learning for robotics has shown the promise of imitation learning across a variety of tasks. Such approaches are expensive both because they require large amounts of real world training demonstrations and because identifying the best model to deploy in the real world requires time-consuming real-world evaluations. These challenges can be mitigated by simulation: by supplementing real world data with simulated demonstrations and using simulated evaluations to identify high performing policies. However, this introduces the well-known "reality gap" problem, where simulator inaccuracies decorrelate performance in simulation from that of reality. In this paper, we build on top of prior work in GAN-based domain adaptation and introduce the notion of a Task Consistency Loss (TCL), a self-supervised loss that encourages sim and real alignment both at the feature and action-prediction levels. We demonstrate the effectiveness of our approach by teaching a mobile manipulator to autonomously approach a door, turn the handle to open the door, and enter the room. The policy performs control from RGB and depth images and generalizes to doors not encountered in training data. We achieve 80% success across ten seen and unseen scenes using only ~16.2 hours of teleoperated demonstrations in sim and real. To the best of our knowledge, this is the first work to tackle latched door opening from a purely end-to-end learning approach, where the task of navigation and manipulation are jointly modeled by a single neural network.
SimGAN: Hybrid Simulator Identification for Domain Adaptation via Adversarial Reinforcement Learning
Jan 15, 2021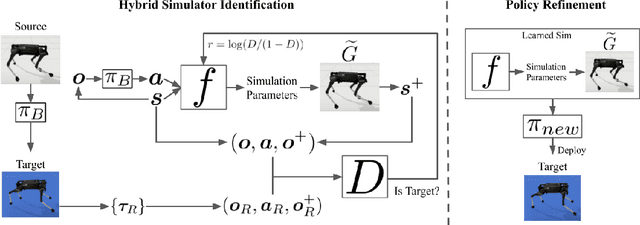
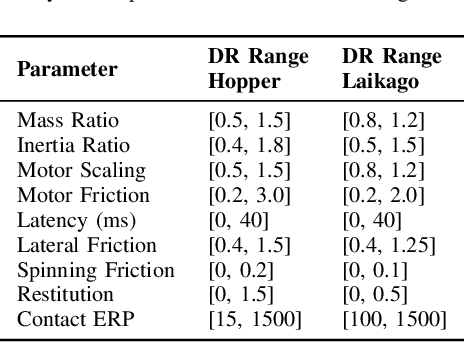
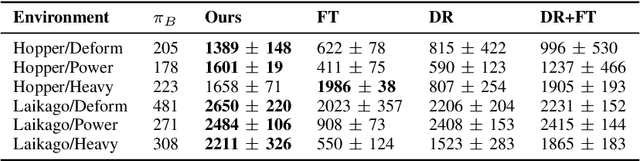

As learning-based approaches progress towards automating robot controllers design, transferring learned policies to new domains with different dynamics (e.g. sim-to-real transfer) still demands manual effort. This paper introduces SimGAN, a framework to tackle domain adaptation by identifying a hybrid physics simulator to match the simulated trajectories to the ones from the target domain, using a learned discriminative loss to address the limitations associated with manual loss design. Our hybrid simulator combines neural networks and traditional physics simulaton to balance expressiveness and generalizability, and alleviates the need for a carefully selected parameter set in System ID. Once the hybrid simulator is identified via adversarial reinforcement learning, it can be used to refine policies for the target domain, without the need to collect more data. We show that our approach outperforms multiple strong baselines on six robotic locomotion tasks for domain adaptation.
COCOI: Contact-aware Online Context Inference for Generalizable Non-planar Pushing
Nov 23, 2020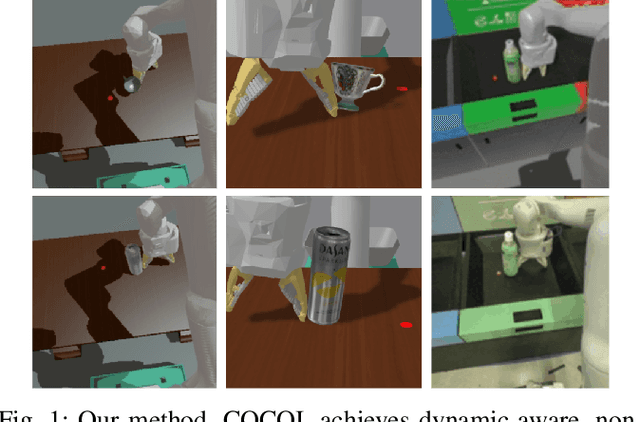
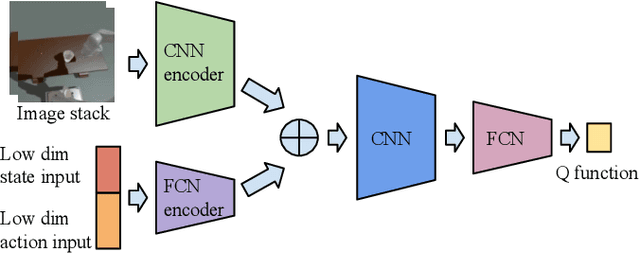
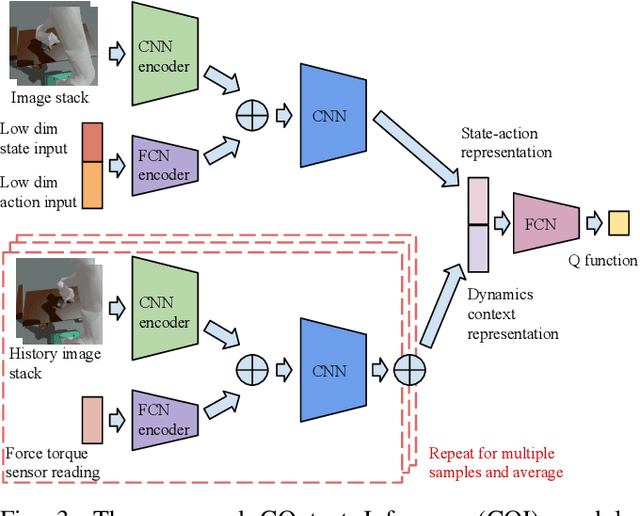
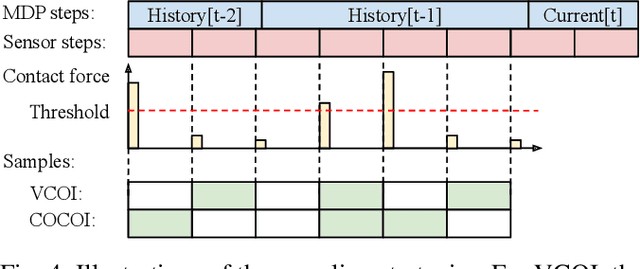
General contact-rich manipulation problems are long-standing challenges in robotics due to the difficulty of understanding complicated contact physics. Deep reinforcement learning (RL) has shown great potential in solving robot manipulation tasks. However, existing RL policies have limited adaptability to environments with diverse dynamics properties, which is pivotal in solving many contact-rich manipulation tasks. In this work, we propose Contact-aware Online COntext Inference (COCOI), a deep RL method that encodes a context embedding of dynamics properties online using contact-rich interactions. We study this method based on a novel and challenging non-planar pushing task, where the robot uses a monocular camera image and wrist force torque sensor reading to push an object to a goal location while keeping it upright. We run extensive experiments to demonstrate the capability of COCOI in a wide range of settings and dynamics properties in simulation, and also in a sim-to-real transfer scenario on a real robot (Video: https://youtu.be/nrmJYksh1Kc)