 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-CycleGAN: Reinforcement Learning Aware Simulation-To-Real
Paper and Code
Jun 16, 2020
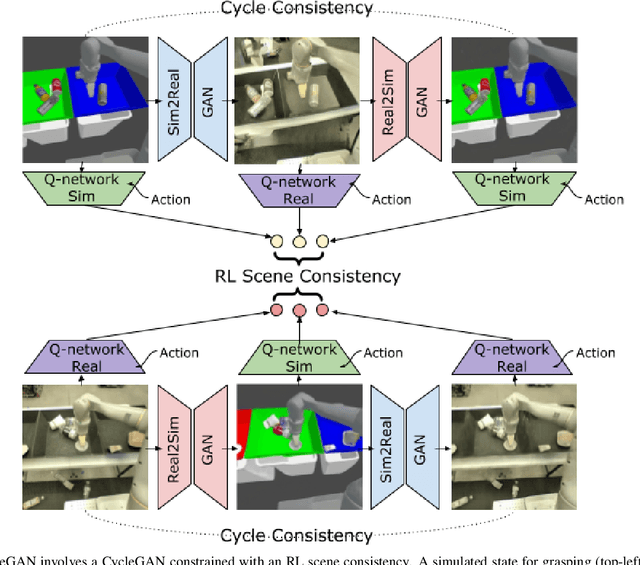


Deep neural network based reinforcement learning (RL) can learn appropriate visual representations for complex tasks like vision-based robotic grasping without the need for manually engineering or prior learning a perception system. However, data for RL is collected via running an agent in the desired environment, and for applications like robotics, running a robot in the real world may be extremely costly and time consuming. Simulated training offers an appealing alternative, but ensuring that policies trained in simulation can transfer effectively into the real world requires additional machinery. Simulations may not match reality, and typically bridging the simulation-to-reality gap requires domain knowledge and task-specific engineering. We can automate this process by employing generative models to translate simulated images into realistic ones. However, this sort of translation is typically task-agnostic, in that the translated images may not preserve all features that are relevant to the task. In this paper, we introduce the RL-scene consistency loss for image translation, which ensures that the translation operation is invariant with respect to the Q-values associated with the image. This allows us to learn a task-aware translation. Incorporating this loss into unsupervised domain translation, we obtain RL-CycleGAN, a new approach for simulation-to-real-world transfer for reinforcement learning. In evaluations of RL-CycleGAN on two vision-based robotics grasping tasks, we show that RL-CycleGAN offers a substantial improvement over a number of prior methods for sim-to-real transfer, attaining excellent real-world performance with only a modest number of real-world observations.