 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023



We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.
A Real-Time Model-Based Reinforcement Learning Architecture for Robot Control
May 21, 2011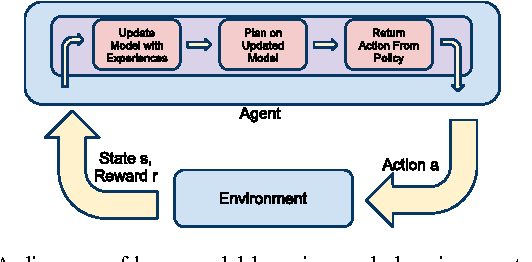
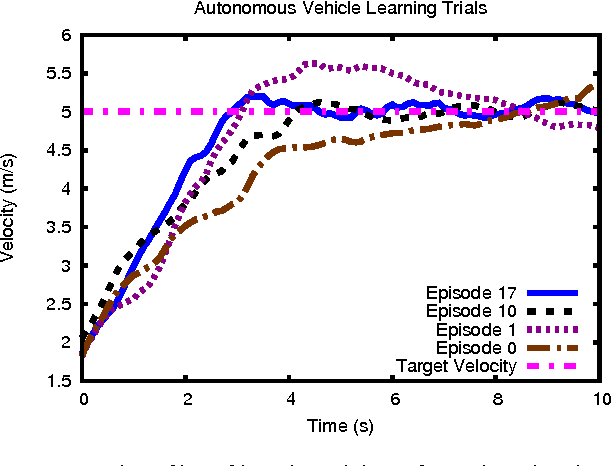
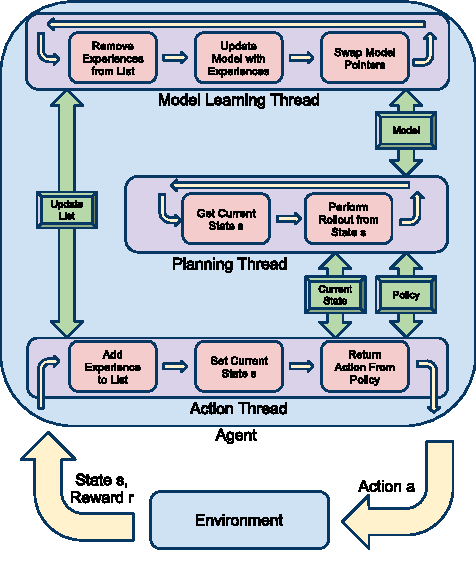

Reinforcement Learning (RL) is a method for learning decision-making tasks that could enable robots to learn and adapt to their situation on-line. For an RL algorithm to be practical for robotic control tasks, it must learn in very few actions, while continually taking those actions in real-time. Existing model-based RL methods learn in relatively few actions, but typically take too much time between each action for practical on-line learning. In this paper, we present a novel parallel architecture for model-based RL that runs in real-time by 1) taking advantage of sample-based approximate planning methods and 2) parallelizing the acting, model learning, and planning processes such that the acting process is sufficiently fast for typical robot control cycles. We demonstrate that algorithms using this architecture perform nearly as well as methods using the typical sequential architecture when both are given unlimited time, and greatly out-perform these methods on tasks that require real-time actions such as controlling an autonomous vehicle.