 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKD-TSTSAN: Three-Stream Temporal-Shift Attention Network Based on Self-Knowledge Distillation for Micro-Expression Recognition
Jun 25, 2024



Micro-expressions (MEs) are subtle facial movements that occur spontaneously when people try to conceal the real emotions. Micro-expression recognition (MER) is crucial in many fields, including criminal analysis and psychotherapy. However, MER is challenging since MEs have low intensity and ME datasets are small in size. To this end, a three-stream temporal-shift attention network based on self-knowledge distillation (SKD-TSTSAN) is proposed in this paper. Firstly, to address the low intensity of ME muscle movements, we utilize learning-based motion magnification modules to enhance the intensity of ME muscle movements. Secondly, we employ efficient channel attention (ECA) modules in the local-spatial stream to make the network focus on facial regions that are highly relevant to MEs. In addition, temporal shift modules (TSMs) are used in the dynamic-temporal stream, which enables temporal modeling with no additional parameters by mixing ME motion information from two different temporal domains. Furthermore, we introduce self-knowledge distillation (SKD) into the MER task by introducing auxiliary classifiers and using the deepest section of the network for supervision, encouraging all blocks to fully explore the features of the training set. Finally, extensive experiments are conducted on four ME datasets: CASME II, SAMM, MMEW, and CAS(ME)3. The experimental results demonstrate that our SKD-TSTSAN outperforms other existing methods and achieves new state-of-the-art performance. Our code will be available at https://github.com/GuanghaoZhu663/SKD-TSTSAN.
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.
SpreadsheetBench: Towards Challenging Real World Spreadsheet Manipulation
Jun 21, 2024



We introduce SpreadsheetBench, a challenging spreadsheet manipulation benchmark exclusively derived from real-world scenarios, designed to immerse current large language models (LLMs) in the actual workflow of spreadsheet users. Unlike existing benchmarks that rely on synthesized queries and simplified spreadsheet files, SpreadsheetBench is built from 912 real questions gathered from online Excel forums, which reflect the intricate needs of users. The associated spreadsheets from the forums contain a variety of tabular data such as multiple tables, non-standard relational tables, and abundant non-textual elements. Furthermore, we propose a more reliable evaluation metric akin to online judge platforms, where multiple spreadsheet files are created as test cases for each instruction, ensuring the evaluation of robust solutions capable of handling spreadsheets with varying values. Our comprehensive evaluation of various LLMs under both single-round and multi-round inference settings reveals a substantial gap between the state-of-the-art (SOTA) models and human performance, highlighting the benchmark's difficulty.
A Learn-Then-Reason Model Towards Generalization in Knowledge Base Question Answering
Jun 20, 2024



Large-scale knowledge bases (KBs) like Freebase and Wikidata house millions of structured knowledge. Knowledge Base Question Answering (KBQA) provides a user-friendly way to access these valuable KBs via asking natural language questions. In order to improve the generalization capabilities of KBQA models, extensive research has embraced a retrieve-then-reason framework to retrieve relevant evidence for logical expression generation. These multi-stage efforts prioritize acquiring external sources but overlook the incorporation of new knowledge into their model parameters. In effect, even advanced language models and retrievers have knowledge boundaries, thereby limiting the generalization capabilities of previous KBQA models. Therefore, this paper develops KBLLaMA, which follows a learn-then-reason framework to inject new KB knowledge into a large language model for flexible end-to-end KBQA. At the core of KBLLaMA, we study (1) how to organize new knowledge about KBQA and (2) how to facilitate the learning of the organized knowledge. Extensive experiments on various KBQA generalization tasks showcase the state-of-the-art performance of KBLLaMA. Especially on the general benchmark GrailQA and domain-specific benchmark Bio-chemical, KBLLaMA respectively derives a performance gain of up to 3.8% and 9.8% compared to the baselines.
PoseBench: Benchmarking the Robustness of Pose Estimation Models under Corruptions
Jun 20, 2024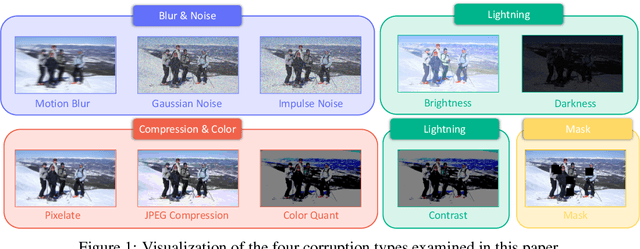
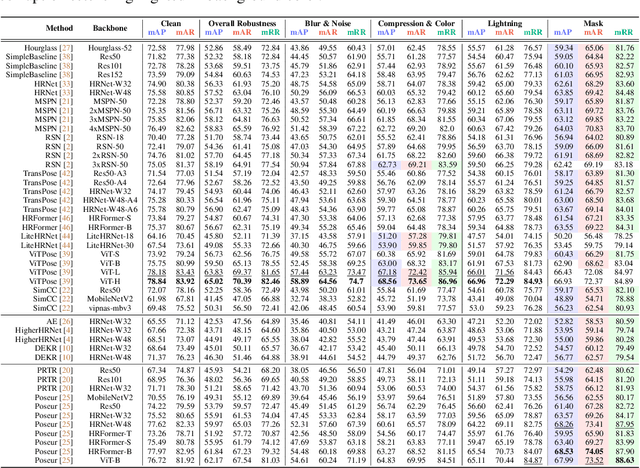


Pose estimation aims to accurately identify anatomical keypoints in humans and animals using monocular images, which is crucial for various applications such as human-machine interaction, embodied AI, and autonomous driving. While current models show promising results, they are typically trained and tested on clean data, potentially overlooking the corruption during real-world deployment and thus posing safety risks in practical scenarios. To address this issue, we introduce PoseBench, a comprehensive benchmark designed to evaluate the robustness of pose estimation models against real-world corruption. We evaluated 60 representative models, including top-down, bottom-up, heatmap-based, regression-based, and classification-based methods, across three datasets for human and animal pose estimation. Our evaluation involves 10 types of corruption in four categories: 1) blur and noise, 2) compression and color loss, 3) severe lighting, and 4) masks. Our findings reveal that state-of-the-art models are vulnerable to common real-world corruptions and exhibit distinct behaviors when tackling human and animal pose estimation tasks. To improve model robustness, we delve into various design considerations, including input resolution, pre-training datasets, backbone capacity, post-processing, and data augmentations. We hope that our benchmark will serve as a foundation for advancing research in robust pose estimation. The benchmark and source code will be released at https://xymsh.github.io/PoseBench
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024



We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
Is Your HD Map Constructor Reliable under Sensor Corruptions?
Jun 18, 2024



Driving systems often rely on high-definition (HD) maps for precise environmental information, which is crucial for planning and navigation. While current HD map constructors perform well under ideal conditions, their resilience to real-world challenges, \eg, adverse weather and sensor failures, is not well understood, raising safety concerns. This work introduces MapBench, the first comprehensive benchmark designed to evaluate the robustness of HD map construction methods against various sensor corruptions. Our benchmark encompasses a total of 29 types of corruptions that occur from cameras and LiDAR sensors. Extensive evaluations across 31 HD map constructors reveal significant performance degradation of existing methods under adverse weather conditions and sensor failures, underscoring critical safety concerns. We identify effective strategies for enhancing robustness, including innovative approaches that leverage multi-modal fusion, advanced data augmentation, and architectural techniques. These insights provide a pathway for developing more reliable HD map construction methods, which are essential for the advancement of autonomous driving technology. The benchmark toolkit and affiliated code and model checkpoints have been made publicly accessible.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
R-Eval: A Unified Toolkit for Evaluating Domain Knowledge of Retrieval Augmented Large Language Models
Jun 17, 2024Large language models have achieved remarkable success on general NLP tasks, but they may fall short for domain-specific problems. Recently, various Retrieval-Augmented Large Language Models (RALLMs) are proposed to address this shortcoming. However, existing evaluation tools only provide a few baselines and evaluate them on various domains without mining the depth of domain knowledge. In this paper, we address the challenges of evaluating RALLMs by introducing the R-Eval toolkit, a Python toolkit designed to streamline the evaluation of different RAG workflows in conjunction with LLMs. Our toolkit, which supports popular built-in RAG workflows and allows for the incorporation of customized testing data on the specific domain, is designed to be user-friendly, modular, and extensible. We conduct an evaluation of 21 RALLMs across three task levels and two representative domains, revealing significant variations in the effectiveness of RALLMs across different tasks and domains. Our analysis emphasizes the importance of considering both task and domain requirements when choosing a RAG workflow and LLM combination. We are committed to continuously maintaining our platform at https://github.com/THU-KEG/R-Eval to facilitate both the industry and the researchers.
HyperSIGMA: Hyperspectral Intelligence Comprehension Foundation Model
Jun 17, 2024



Foundation models (FMs) are revolutionizing the analysis and understanding of remote sensing (RS) scenes, including aerial RGB, multispectral, and SAR images. However, hyperspectral images (HSIs), which are rich in spectral information, have not seen much application of FMs, with existing methods often restricted to specific tasks and lacking generality. To fill this gap, we introduce HyperSIGMA, a vision transformer-based foundation model for HSI interpretation, scalable to over a billion parameters. To tackle the spectral and spatial redundancy challenges in HSIs, we introduce a novel sparse sampling attention (SSA) mechanism, which effectively promotes the learning of diverse contextual features and serves as the basic block of HyperSIGMA. HyperSIGMA integrates spatial and spectral features using a specially designed spectral enhancement module. In addition, we construct a large-scale hyperspectral dataset, HyperGlobal-450K, for pre-training, which contains about 450K hyperspectral images, significantly surpassing existing datasets in scale. Extensive experiments on various high-level and low-level HSI tasks demonstrate HyperSIGMA's versatility and superior representational capability compared to current state-of-the-art methods. Moreover, HyperSIGMA shows significant advantages in scalability, robustness, cross-modal transferring capability, and real-world applicability.