 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM-AutoDrive: Post-Training Vision-Language Models for Safety-Critical Autonomous Driving Events
Mar 18, 2026The rapid growth of ego-centric dashcam footage presents a major challenge for detecting safety-critical events such as collisions and near-collisions, scenarios that are brief, rare, and difficult for generic vision models to capture. While multimodal large language models (MLLMs) demonstrate strong general reasoning ability, they underperform in driving contexts due to domain and temporal misalignment. We introduce VLM-AutoDrive, a modular post-training framework for adapting pretrained Vision-Language Models (VLMs) to high-fidelity anomaly detection. The framework integrates metadata-derived captions, LLM-generated descriptions, visual question answering (VQA) pairs, and chain-of-thought (CoT) reasoning supervision to enable domain-aligned and interpretable learning. Off-the-shelf VLMs such as NVIDIA's Cosmos-Reason1 7B (CR1) exhibit near-zero Collision recall in zero-shot settings; fine-tuning with VLM-AutoDrive improves Collision F1 from 0.00 to 0.69 and overall accuracy from 35.35% to 77.27%. VLM-AutoDrive offers a scalable recipe for adapting general-purpose VLMs to safety-critical, temporally localized perception tasks. Evaluated on real-world Nexar dashcam videos, it achieves substantial gains in Collision and Near-Collision detection while producing interpretable reasoning traces, bridging the gap between perception, causality, and decision reasoning in autonomous driving.
Training Video Foundation Models with NVIDIA NeMo
Mar 17, 2025Video Foundation Models (VFMs) have recently been used to simulate the real world to train physical AI systems and develop creative visual experiences. However, there are significant challenges in training large-scale, high quality VFMs that can generate high-quality videos. We present a scalable, open-source VFM training pipeline with NVIDIA NeMo, providing accelerated video dataset curation, multimodal data loading, and parallelized video diffusion model training and inference. We also provide a comprehensive performance analysis highlighting best practices for efficient VFM training and inference.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
RecD: Deduplication for End-to-End Deep Learning Recommendation Model Training Infrastructure
Nov 14, 2022



We present RecD (Recommendation Deduplication), a suite of end-to-end infrastructure optimizations across the Deep Learning Recommendation Model (DLRM) training pipeline. RecD addresses immense storage, preprocessing, and training overheads caused by feature duplication inherent in industry-scale DLRM training datasets. Feature duplication arises because DLRM datasets are generated from interactions. While each user session can generate multiple training samples, many features' values do not change across these samples. We demonstrate how RecD exploits this property, end-to-end, across a deployed training pipeline. RecD optimizes data generation pipelines to decrease dataset storage and preprocessing resource demands and to maximize duplication within a training batch. RecD introduces a new tensor format, InverseKeyedJaggedTensors (IKJTs), to deduplicate feature values in each batch. We show how DLRM model architectures can leverage IKJTs to drastically increase training throughput. RecD improves the training and preprocessing throughput and storage efficiency by up to 2.49x, 1.79x, and 3.71x, respectively, in an industry-scale DLRM training system.
RecShard: Statistical Feature-Based Memory Optimization for Industry-Scale Neural Recommendation
Jan 25, 2022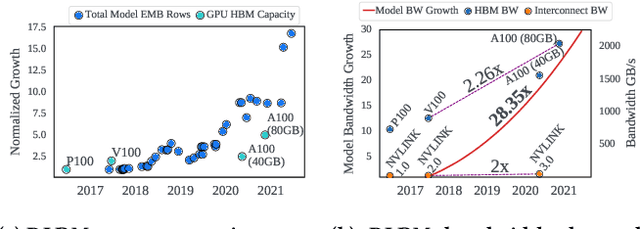
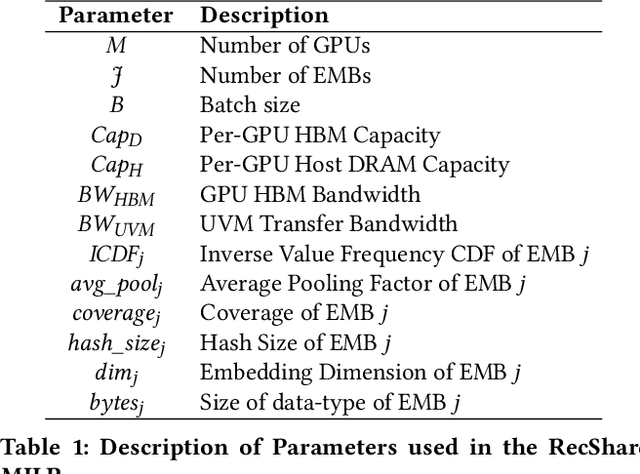
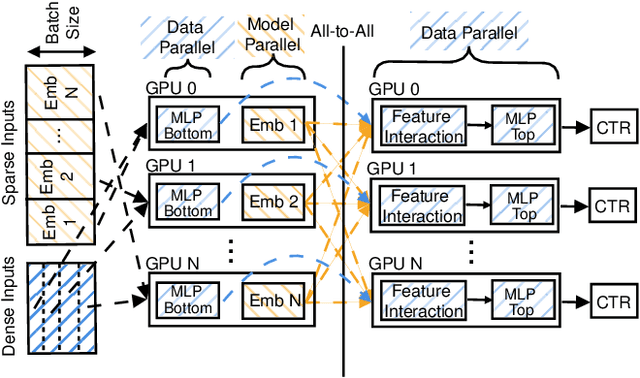
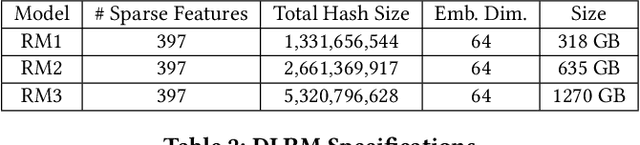
We propose RecShard, a fine-grained embedding table (EMB) partitioning and placement technique for deep learning recommendation models (DLRMs). RecShard is designed based on two key observations. First, not all EMBs are equal, nor all rows within an EMB are equal in terms of access patterns. EMBs exhibit distinct memory characteristics, providing performance optimization opportunities for intelligent EMB partitioning and placement across a tiered memory hierarchy. Second, in modern DLRMs, EMBs function as hash tables. As a result, EMBs display interesting phenomena, such as the birthday paradox, leaving EMBs severely under-utilized. RecShard determines an optimal EMB sharding strategy for a set of EMBs based on training data distributions and model characteristics, along with the bandwidth characteristics of the underlying tiered memory hierarchy. In doing so, RecShard achieves over 6 times higher EMB training throughput on average for capacity constrained DLRMs. The throughput increase comes from improved EMB load balance by over 12 times and from the reduced access to the slower memory by over 87 times.
Understanding and Co-designing the Data Ingestion Pipeline for Industry-Scale RecSys Training
Aug 20, 2021
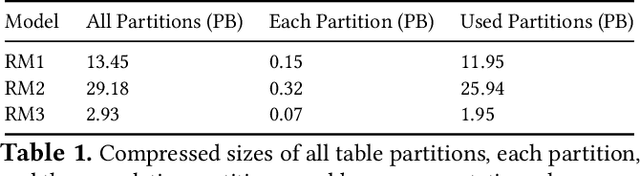
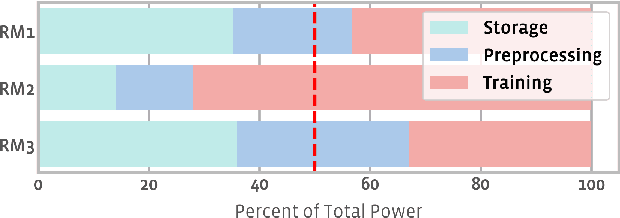

The data ingestion pipeline, responsible for storing and preprocessing training data, is an important component of any machine learning training job. At Facebook, we use recommendation models extensively across our services. The data ingestion requirements to train these models are substantial. In this paper, we present an extensive characterization of the data ingestion challenges for industry-scale recommendation model training. First, dataset storage requirements are massive and variable; exceeding local storage capacities. Secondly, reading and preprocessing data is computationally expensive, requiring substantially more compute, memory, and network resources than are available on trainers themselves. These demands result in drastically reduced training throughput, and thus wasted GPU resources, when current on-trainer preprocessing solutions are used. To address these challenges, we present a disaggregated data ingestion pipeline. It includes a central data warehouse built on distributed storage nodes. We introduce Data PreProcessing Service (DPP), a fully disaggregated preprocessing service that scales to hundreds of nodes, eliminating data stalls that can reduce training throughput by 56%. We implement important optimizations across storage and DPP, increasing storage and preprocessing throughput by 1.9x and 2.3x, respectively, addressing the substantial power requirements of data ingestion. We close with lessons learned and cover the important remaining challenges and opportunities surrounding data ingestion at scale.