 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Hour-Scale Video Training for Long Video-Language Understanding
Jun 05, 2025Recent long-form video-language understanding benchmarks have driven progress in video large multimodal models (Video-LMMs). However, the scarcity of well-annotated long videos has left the training of hour-long Video-LLMs underexplored. To close this gap, we present VideoMarathon, a large-scale hour-long video instruction-following dataset. This dataset includes around 9,700 hours of long videos sourced from diverse domains, ranging from 3 to 60 minutes per video. Specifically, it contains 3.3M high-quality QA pairs, spanning six fundamental topics: temporality, spatiality, object, action, scene, and event. Compared to existing video instruction datasets, VideoMarathon significantly extends training video durations up to 1 hour, and supports 22 diverse tasks requiring both short- and long-term video comprehension. Building on VideoMarathon, we propose Hour-LLaVA, a powerful and efficient Video-LMM for hour-scale video-language modeling. It enables hour-long video training and inference at 1-FPS sampling by leveraging a memory augmentation module, which adaptively integrates user question-relevant and spatiotemporal-informative semantics from a cached full video context. In our experiments, Hour-LLaVA achieves the best performance on multiple long video-language benchmarks, demonstrating the high quality of the VideoMarathon dataset and the superiority of the Hour-LLaVA model.
Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese
May 28, 2025



While the capabilities of Large Language Models (LLMs) have been studied in both Simplified and Traditional Chinese, it is yet unclear whether LLMs exhibit differential performance when prompted in these two variants of written Chinese. This understanding is critical, as disparities in the quality of LLM responses can perpetuate representational harms by ignoring the different cultural contexts underlying Simplified versus Traditional Chinese, and can exacerbate downstream harms in LLM-facilitated decision-making in domains such as education or hiring. To investigate potential LLM performance disparities, we design two benchmark tasks that reflect real-world scenarios: regional term choice (prompting the LLM to name a described item which is referred to differently in Mainland China and Taiwan), and regional name choice (prompting the LLM to choose who to hire from a list of names in both Simplified and Traditional Chinese). For both tasks, we audit the performance of 11 leading commercial LLM services and open-sourced models -- spanning those primarily trained on English, Simplified Chinese, or Traditional Chinese. Our analyses indicate that biases in LLM responses are dependent on both the task and prompting language: while most LLMs disproportionately favored Simplified Chinese responses in the regional term choice task, they surprisingly favored Traditional Chinese names in the regional name choice task. We find that these disparities may arise from differences in training data representation, written character preferences, and tokenization of Simplified and Traditional Chinese. These findings highlight the need for further analysis of LLM biases; as such, we provide an open-sourced benchmark dataset to foster reproducible evaluations of future LLM behavior across Chinese language variants (https://github.com/brucelyu17/SC-TC-Bench).
OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation
May 28, 2025Subject-to-Video (S2V) generation aims to create videos that faithfully incorporate reference content, providing enhanced flexibility in the production of videos. To establish the infrastructure for S2V generation, we propose OpenS2V-Nexus, consisting of (i) OpenS2V-Eval, a fine-grained benchmark, and (ii) OpenS2V-5M, a million-scale dataset. In contrast to existing S2V benchmarks inherited from VBench that focus on global and coarse-grained assessment of generated videos, OpenS2V-Eval focuses on the model's ability to generate subject-consistent videos with natural subject appearance and identity fidelity. For these purposes, OpenS2V-Eval introduces 180 prompts from seven major categories of S2V, which incorporate both real and synthetic test data. Furthermore, to accurately align human preferences with S2V benchmarks, we propose three automatic metrics, NexusScore, NaturalScore and GmeScore, to separately quantify subject consistency, naturalness, and text relevance in generated videos. Building on this, we conduct a comprehensive evaluation of 16 representative S2V models, highlighting their strengths and weaknesses across different content. Moreover, we create the first open-source large-scale S2V generation dataset OpenS2V-5M, which consists of five million high-quality 720P subject-text-video triples. Specifically, we ensure subject-information diversity in our dataset by (1) segmenting subjects and building pairing information via cross-video associations and (2) prompting GPT-Image-1 on raw frames to synthesize multi-view representations. Through OpenS2V-Nexus, we deliver a robust infrastructure to accelerate future S2V generation research.
MMIG-Bench: Towards Comprehensive and Explainable Evaluation of Multi-Modal Image Generation Models
May 26, 2025Recent multimodal image generators such as GPT-4o, Gemini 2.0 Flash, and Gemini 2.5 Pro excel at following complex instructions, editing images and maintaining concept consistency. However, they are still evaluated by disjoint toolkits: text-to-image (T2I) benchmarks that lacks multi-modal conditioning, and customized image generation benchmarks that overlook compositional semantics and common knowledge. We propose MMIG-Bench, a comprehensive Multi-Modal Image Generation Benchmark that unifies these tasks by pairing 4,850 richly annotated text prompts with 1,750 multi-view reference images across 380 subjects, spanning humans, animals, objects, and artistic styles. MMIG-Bench is equipped with a three-level evaluation framework: (1) low-level metrics for visual artifacts and identity preservation of objects; (2) novel Aspect Matching Score (AMS): a VQA-based mid-level metric that delivers fine-grained prompt-image alignment and shows strong correlation with human judgments; and (3) high-level metrics for aesthetics and human preference. Using MMIG-Bench, we benchmark 17 state-of-the-art models, including Gemini 2.5 Pro, FLUX, DreamBooth, and IP-Adapter, and validate our metrics with 32k human ratings, yielding in-depth insights into architecture and data design. We will release the dataset and evaluation code to foster rigorous, unified evaluation and accelerate future innovations in multi-modal image generation.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
WorldGenBench: A World-Knowledge-Integrated Benchmark for Reasoning-Driven Text-to-Image Generation
May 02, 2025Recent advances in text-to-image (T2I) generation have achieved impressive results, yet existing models still struggle with prompts that require rich world knowledge and implicit reasoning: both of which are critical for producing semantically accurate, coherent, and contextually appropriate images in real-world scenarios. To address this gap, we introduce \textbf{WorldGenBench}, a benchmark designed to systematically evaluate T2I models' world knowledge grounding and implicit inferential capabilities, covering both the humanities and nature domains. We propose the \textbf{Knowledge Checklist Score}, a structured metric that measures how well generated images satisfy key semantic expectations. Experiments across 21 state-of-the-art models reveal that while diffusion models lead among open-source methods, proprietary auto-regressive models like GPT-4o exhibit significantly stronger reasoning and knowledge integration. Our findings highlight the need for deeper understanding and inference capabilities in next-generation T2I systems. Project Page: \href{https://dwanzhang-ai.github.io/WorldGenBench/}{https://dwanzhang-ai.github.io/WorldGenBench/}
SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
Apr 14, 2025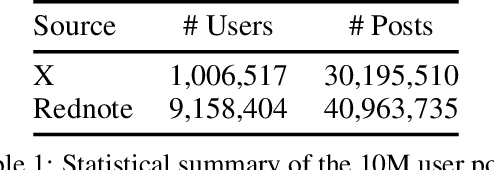
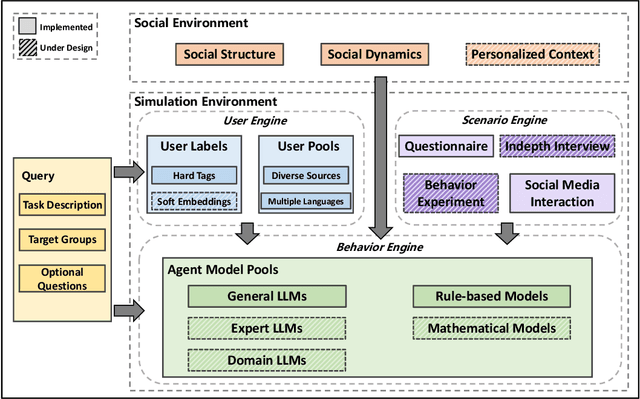

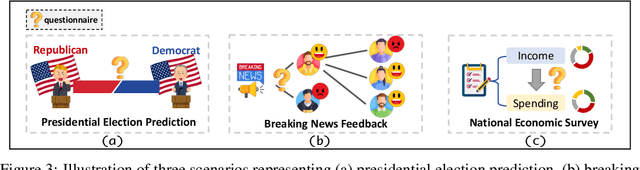
Social simulation is transforming traditional social science research by modeling human behavior through interactions between virtual individuals and their environments. With recent advances in large language models (LLMs), this approach has shown growing potential in capturing individual differences and predicting group behaviors. However, existing methods face alignment challenges related to the environment, target users, interaction mechanisms, and behavioral patterns. To this end, we introduce SocioVerse, an LLM-agent-driven world model for social simulation. Our framework features four powerful alignment components and a user pool of 10 million real individuals. To validate its effectiveness, we conducted large-scale simulation experiments across three distinct domains: politics, news, and economics. Results demonstrate that SocioVerse can reflect large-scale population dynamics while ensuring diversity, credibility, and representativeness through standardized procedures and minimal manual adjustments.
ZipIR: Latent Pyramid Diffusion Transformer for High-Resolution Image Restoration
Apr 11, 2025Recent progress in generative models has significantly improved image restoration capabilities, particularly through powerful diffusion models that offer remarkable recovery of semantic details and local fidelity. However, deploying these models at ultra-high resolutions faces a critical trade-off between quality and efficiency due to the computational demands of long-range attention mechanisms. To address this, we introduce ZipIR, a novel framework that enhances efficiency, scalability, and long-range modeling for high-res image restoration. ZipIR employs a highly compressed latent representation that compresses image 32x, effectively reducing the number of spatial tokens, and enabling the use of high-capacity models like the Diffusion Transformer (DiT). Toward this goal, we propose a Latent Pyramid VAE (LP-VAE) design that structures the latent space into sub-bands to ease diffusion training. Trained on full images up to 2K resolution, ZipIR surpasses existing diffusion-based methods, offering unmatched speed and quality in restoring high-resolution images from severely degraded inputs.
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning (v1)
Apr 04, 2025



Reasoning is central to human intelligence, enabling structured problem-solving across diverse tasks. Recent advances in large language models (LLMs) have greatly enhanced their reasoning abilities in arithmetic, commonsense, and symbolic domains. However, effectively extending these capabilities into multimodal contexts-where models must integrate both visual and textual inputs-continues to be a significant challenge. Multimodal reasoning introduces complexities, such as handling conflicting information across modalities, which require models to adopt advanced interpretative strategies. Addressing these challenges involves not only sophisticated algorithms but also robust methodologies for evaluating reasoning accuracy and coherence. This paper offers a concise yet insightful overview of reasoning techniques in both textual and multimodal LLMs. Through a thorough and up-to-date comparison, we clearly formulate core reasoning challenges and opportunities, highlighting practical methods for post-training optimization and test-time inference. Our work provides valuable insights and guidance, bridging theoretical frameworks and practical implementations, and sets clear directions for future research.