 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointQ-Bench: Benchmarking Diagnostic and Interpretable Point Cloud Quality Assessment
May 27, 2026Point cloud quality plays a critical role in 3D acquisition, reconstruction, rendering, and perception, yet existing point cloud quality assessment (PCQA) research remains largely centered on scalar score prediction. In practical inspection scenarios, quality assessment often involves identifying defects, characterizing dominant issue types, assessing downstream usability, and providing evidence-supported descriptions, which are not explicitly evaluated by current benchmarks. We introduce PointQ-Bench, a benchmark designed to extend PCQA from scalar scoring toward comprehensive quality understanding. PointQ-Bench consists of 3,083 point clouds spanning authentic scans, simulated distortions, and AI-generated content, covering eight major issue types. Each sample is annotated with mean opinion scores (MOS), quality levels, issue tags, expert-grounded descriptions, and 12,332 question-answer pairs. The benchmark supports three perception-oriented tasks: anomaly sensing, defect diagnosis, and usability grading, as well as a cognition-oriented task of open-ended quality reporting. To evaluate free-form quality descriptions, we further propose SSFRQ-5D, a five-dimensional evaluation protocol validated through human-AI agreement analysis. Extensive experiments on 14 vision-language models and traditional PCQA baselines reveal a consistent perception-diagnosis gap: while current models exhibit emerging abilities in coarse defect perception, they struggle with grounded diagnosis and quality calibration. Strong 2D MLLMs generally outperform existing 3D VLMs, and the benefit of additional views or point-level inputs is non-uniform, varying across tasks, data sources, and models, particularly under boundary-ambiguous conditions. Overall, PointQ-Bench provides a diagnostic testbed for advancing reliable and interpretable point cloud quality understanding.
Seeing Through Fog: Towards Fog-Invariant Action Recognition
May 20, 2026Foggy conditions are commonly encountered in real-world applications; however, existing action recognition approaches typically assume favorable weather and high-quality video inputs. On foggy days, unpredictable visibility degradation and reduced contrast obstruct the extraction of semantic cues, posing significant challenges for current action recognition methods. In this paper, we mitigate the issues faced in action recognition under foggy conditions by employing two strategies. First, we present FogAct, the first benchmark dataset for foggy action recognition, consisting of paired clean and foggy videos captured with a stereo camera system. The dataset spans 10 scenes and 55 action categories, comprising nearly 10,000 video clips. Second, we propose FogNet, a two-stream CLIP model that discovers fog-invariant semantic information hidden behind the degraded videos. FogNet learns robust representations of foggy videos with guidance from clean videos, effectively capturing shared structural and motion cues between clean and foggy videos. Extensive experiments on FogAct and three other popular datasets demonstrate that our method achieves competitive performance compared with state-of-the-art (SOTA) approaches. Our FogAct and FogNet are given in our project page.
Benchmarking and Improving GUI Agents in High-Dynamic Environments
Apr 28, 2026Recent advancements in Graphical User Interface (GUI) agents have predominantly focused on training paradigms like supervised fine-tuning (SFT) and reinforcement learning (RL). However, the challenge of high-dynamic GUI environments remains largely underexplored. Existing agents typically rely on a single screenshot after each action for decision-making, leading to a partially observable (or even unobservable) Markov decision process, where the key GUI state including important information for actions is often inadequately captured. To systematically explore this challenge, we introduce DynamicGUIBench, a comprehensive online GUI benchmark spanning ten applications and diverse interaction scenarios characterized by important interface changes between actions. Furthermore, we present DynamicUI, an agent designed for dynamic interfaces, which takes screen-recording videos of the interaction process as input and consists of three components: a dynamic perceiver, a refinement strategy, and a reflection. Specifically, the dynamic perceiver clusters frames of the GUI video, generates captions for the centroids, and iteratively selects the most informative frames as the salient dynamic context. Considering that there may be inconsistencies and noise between the selected frames and the textual context of the agent, the refinement strategy employs an action-conditioned filtering to refine thoughts to mitigate thought-action inconsistency and redundancy. Based on the refined agent trajectories, the reflection module provides effective and accurate guidance for further actions. Experiments on DynamicGUIBench demonstrate that DynamicUI significantly improves the performance in dynamic GUI environments, while maintaining competitive performance on other public benchmarks.
GUIDE: Resolving Domain Bias in GUI Agents through Real-Time Web Video Retrieval and Plug-and-Play Annotation
Mar 27, 2026Large vision-language models have endowed GUI agents with strong general capabilities for interface understanding and interaction. However, due to insufficient exposure to domain-specific software operation data during training, these agents exhibit significant domain bias - they lack familiarity with the specific operation workflows (planning) and UI element layouts (grounding) of particular applications, limiting their real-world task performance. In this paper, we present GUIDE (GUI Unbiasing via Instructional-Video Driven Expertise), a training-free, plug-and-play framework that resolves GUI agent domain bias by autonomously acquiring domain-specific expertise from web tutorial videos through a retrieval-augmented automated annotation pipeline. GUIDE introduces two key innovations. First, a subtitle-driven Video-RAG pipeline unlocks video semantics through subtitle analysis, performing progressive three-stage retrieval - domain classification, topic extraction, and relevance matching - to identify task-relevant tutorial videos. Second, a fully automated annotation pipeline built on an inverse dynamics paradigm feeds consecutive keyframes enhanced with UI element detection into VLMs, inferring the required planning and grounding knowledge that are injected into the agent's corresponding modules to address both manifestations of domain bias. Extensive experiments on OSWorld demonstrate GUIDE's generality as a plug-and-play component for both multi-agent systems and single-model agents. It consistently yields over 5% improvements and reduces execution steps - without modifying any model parameters or architecture - validating GUIDE as an architecture-agnostic enhancement to bridge GUI agent domain bias.
RoboGene: Boosting VLA Pre-training via Diversity-Driven Agentic Framework for Real-World Task Generation
Feb 19, 2026The pursuit of general-purpose robotic manipulation is hindered by the scarcity of diverse, real-world interaction data. Unlike data collection from web in vision or language, robotic data collection is an active process incurring prohibitive physical costs. Consequently, automated task curation to maximize data value remains a critical yet under-explored challenge. Existing manual methods are unscalable and biased toward common tasks, while off-the-shelf foundation models often hallucinate physically infeasible instructions. To address this, we introduce RoboGene, an agentic framework designed to automate the generation of diverse, physically plausible manipulation tasks across single-arm, dual-arm, and mobile robots. RoboGene integrates three core components: diversity-driven sampling for broad task coverage, self-reflection mechanisms to enforce physical constraints, and human-in-the-loop refinement for continuous improvement. We conduct extensive quantitative analysis and large-scale real-world experiments, collecting datasets of 18k trajectories and introducing novel metrics to assess task quality, feasibility, and diversity. Results demonstrate that RoboGene significantly outperforms state-of-the-art foundation models (e.g., GPT-4o, Gemini 2.5 Pro). Furthermore, real-world experiments show that VLA models pre-trained with RoboGene achieve higher success rates and superior generalization, underscoring the importance of high-quality task generation. Our project is available at https://robogene-boost-vla.github.io.
STVG-R1: Incentivizing Instance-Level Reasoning and Grounding in Videos via Reinforcement Learning
Feb 12, 2026In vision-language models (VLMs), misalignment between textual descriptions and visual coordinates often induces hallucinations. This issue becomes particularly severe in dense prediction tasks such as spatial-temporal video grounding (STVG). Prior approaches typically focus on enhancing visual-textual alignment or attaching auxiliary decoders. However, these strategies inevitably introduce additional trainable modules, leading to significant annotation costs and computational overhead. In this work, we propose a novel visual prompting paradigm that avoids the difficult problem of aligning coordinates across modalities. Specifically, we reformulate per-frame coordinate prediction as a compact instance-level identification problem by assigning each object a unique, temporally consistent ID. These IDs are embedded into the video as visual prompts, providing explicit and interpretable inputs to the VLMs. Furthermore, we introduce STVG-R1, the first reinforcement learning framework for STVG, which employs a task-driven reward to jointly optimize temporal accuracy, spatial consistency, and structural format regularization. Extensive experiments on six benchmarks demonstrate the effectiveness of our approach. STVG-R1 surpasses the baseline Qwen2.5-VL-7B by a remarkable margin of 20.9% on m_IoU on the HCSTVG-v2 benchmark, establishing a new state of the art (SOTA). Surprisingly, STVG-R1 also exhibits strong zero-shot generalization to multi-object referring video object segmentation tasks, achieving a SOTA 47.3% J&F on MeViS.
AdaptMMBench: Benchmarking Adaptive Multimodal Reasoning for Mode Selection and Reasoning Process
Feb 02, 2026Adaptive multimodal reasoning has emerged as a promising frontier in Vision-Language Models (VLMs), aiming to dynamically modulate between tool-augmented visual reasoning and text reasoning to enhance both effectiveness and efficiency. However, existing evaluations rely on static difficulty labels and simplistic metrics, which fail to capture the dynamic nature of difficulty relative to varying model capacities. Consequently, they obscure the distinction between adaptive mode selection and general performance while neglecting fine-grained process analyses. In this paper, we propose AdaptMMBench, a comprehensive benchmark for adaptive multimodal reasoning across five domains: real-world, OCR, GUI, knowledge, and math, encompassing both direct perception and complex reasoning tasks. AdaptMMBench utilizes a Matthews Correlation Coefficient (MCC) metric to evaluate the selection rationality of different reasoning modes, isolating this meta-cognition ability by dynamically identifying task difficulties based on models' capability boundaries. Moreover, AdaptMMBench facilitates multi-dimensional process evaluation across key step coverage, tool effectiveness, and computational efficiency. Our evaluation reveals that while adaptive mode selection scales with model capacity, it notably decouples from final accuracy. Conversely, key step coverage aligns with performance, though tool effectiveness remains highly inconsistent across model architectures.
From Visual Perception to Deep Empathy: An Automated Assessment Framework for House-Tree-Person Drawings Using Multimodal LLMs and Multi-Agent Collaboration
Dec 23, 2025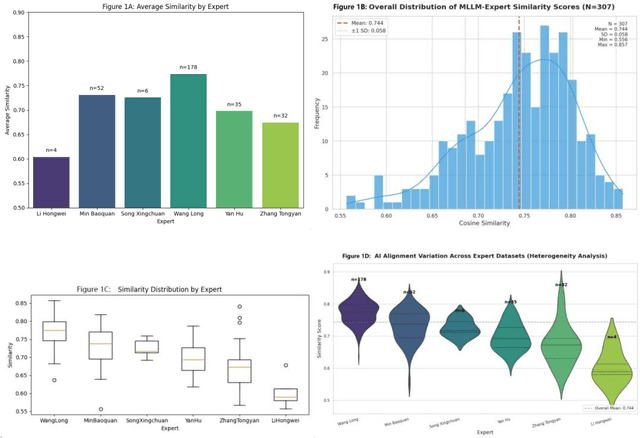
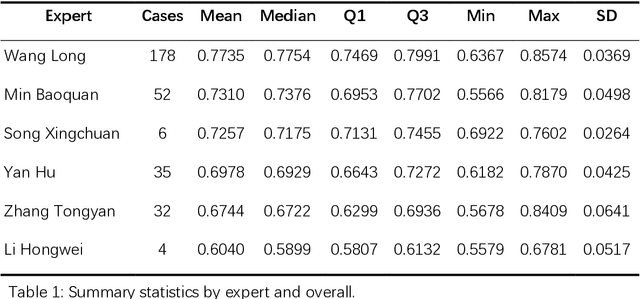
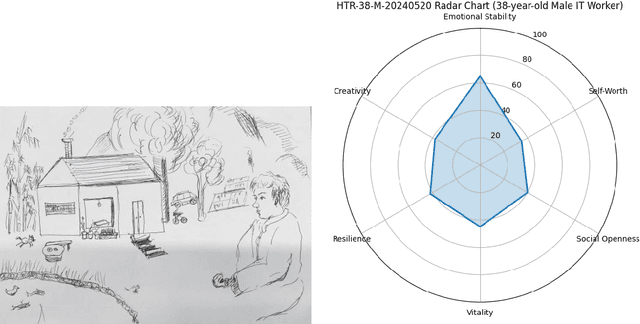
Background: The House-Tree-Person (HTP) drawing test, introduced by John Buck in 1948, remains a widely used projective technique in clinical psychology. However, it has long faced challenges such as heterogeneous scoring standards, reliance on examiners subjective experience, and a lack of a unified quantitative coding system. Results: Quantitative experiments showed that the mean semantic similarity between Multimodal Large Language Model (MLLM) interpretations and human expert interpretations was approximately 0.75 (standard deviation about 0.05). In structurally oriented expert data sets, this similarity rose to 0.85, indicating expert-level baseline comprehension. Qualitative analyses demonstrated that the multi-agent system, by integrating social-psychological perspectives and destigmatizing narratives, effectively corrected visual hallucinations and produced psychological reports with high ecological validity and internal coherence. Conclusions: The findings confirm the potential of multimodal large models as standardized tools for projective assessment. The proposed multi-agent framework, by dividing roles, decouples feature recognition from psychological inference and offers a new paradigm for digital mental-health services. Keywords: House-Tree-Person test; multimodal large language model; multi-agent collaboration; cosine similarity; computational psychology; artificial intelligence
Modality Alignment across Trees on Heterogeneous Hyperbolic Manifolds
Oct 31, 2025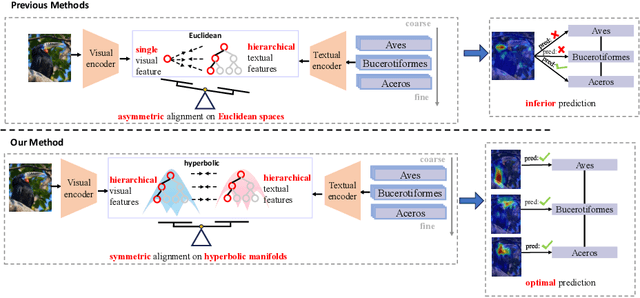
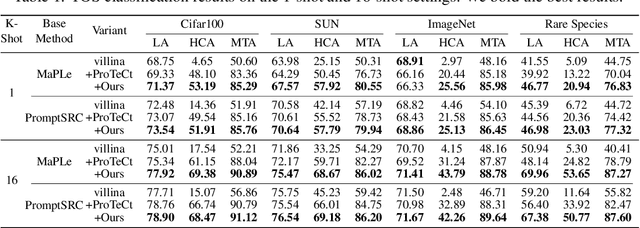
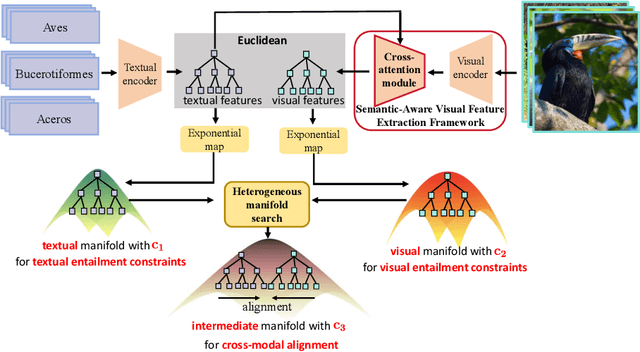

Modality alignment is critical for vision-language models (VLMs) to effectively integrate information across modalities. However, existing methods extract hierarchical features from text while representing each image with a single feature, leading to asymmetric and suboptimal alignment. To address this, we propose Alignment across Trees, a method that constructs and aligns tree-like hierarchical features for both image and text modalities. Specifically, we introduce a semantic-aware visual feature extraction framework that applies a cross-attention mechanism to visual class tokens from intermediate Transformer layers, guided by textual cues to extract visual features with coarse-to-fine semantics. We then embed the feature trees of the two modalities into hyperbolic manifolds with distinct curvatures to effectively model their hierarchical structures. To align across the heterogeneous hyperbolic manifolds with different curvatures, we formulate a KL distance measure between distributions on heterogeneous manifolds, and learn an intermediate manifold for manifold alignment by minimizing the distance. We prove the existence and uniqueness of the optimal intermediate manifold. Experiments on taxonomic open-set classification tasks across multiple image datasets demonstrate that our method consistently outperforms strong baselines under few-shot and cross-domain settings.
GUI Knowledge Bench: Revealing the Knowledge Gap Behind VLM Failures in GUI Tasks
Oct 30, 2025Large vision language models (VLMs) have advanced graphical user interface (GUI) task automation but still lag behind humans. We hypothesize this gap stems from missing core GUI knowledge, which existing training schemes (such as supervised fine tuning and reinforcement learning) alone cannot fully address. By analyzing common failure patterns in GUI task execution, we distill GUI knowledge into three dimensions: (1) interface perception, knowledge about recognizing widgets and system states; (2) interaction prediction, knowledge about reasoning action state transitions; and (3) instruction understanding, knowledge about planning, verifying, and assessing task completion progress. We further introduce GUI Knowledge Bench, a benchmark with multiple choice and yes/no questions across six platforms (Web, Android, MacOS, Windows, Linux, IOS) and 292 applications. Our evaluation shows that current VLMs identify widget functions but struggle with perceiving system states, predicting actions, and verifying task completion. Experiments on real world GUI tasks further validate the close link between GUI knowledge and task success. By providing a structured framework for assessing GUI knowledge, our work supports the selection of VLMs with greater potential prior to downstream training and provides insights for building more capable GUI agents.