 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training
Mar 12, 2026Reasoning LLMs-as-Judges, which can benefit from inference-time scaling, provide a promising path for extending the success of reasoning models to non-verifiable domains where the output correctness/quality cannot be directly checked. However, while reasoning judges have shown better performance on static evaluation benchmarks, their effectiveness in actual policy training has not been systematically examined. Therefore, we conduct a rigorous study to investigate the actual impact of non-reasoning and reasoning judges in reinforcement-learning-based LLM alignment. Our controlled synthetic setting, where a "gold-standard" judge (gpt-oss-120b) provides preference annotations to train smaller judges, reveals key differences between non-reasoning and reasoning judges: non-reasoning judges lead to reward hacking easily, while reasoning judges can lead to policies that achieve strong performance when evaluated by the gold-standard judge. Interestingly, we find that the reasoning-judge-trained policies achieve such strong performance by learning to generate highly effective adversarial outputs that can also score well on popular benchmarks such as Arena-Hard by deceiving other LLM-judges. Combined with our further analysis, our study highlights both important findings and room for improvements for applying (reasoning) LLM-judges in non-verifiable LLM post-training.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
From Solving to Verifying: A Unified Objective for Robust Reasoning in LLMs
Nov 19, 2025The reasoning capabilities of large language models (LLMs) have been significantly improved through reinforcement learning (RL). Nevertheless, LLMs still struggle to consistently verify their own reasoning traces. This raises the research question of how to enhance the self-verification ability of LLMs and whether such an ability can further improve reasoning performance. In this work, we propose GRPO-Verif, an algorithm that jointly optimizes solution generation and self-verification within a unified loss function, with an adjustable hyperparameter controlling the weight of the verification signal. Experimental results demonstrate that our method enhances self-verification capability while maintaining comparable performance in reasoning.
AI based signage classification for linguistic landscape studies
Oct 27, 2025Linguistic Landscape (LL) research traditionally relies on manual photography and annotation of public signages to examine distribution of languages in urban space. While such methods yield valuable findings, the process is time-consuming and difficult for large study areas. This study explores the use of AI powered language detection method to automate LL analysis. Using Honolulu Chinatown as a case study, we constructed a georeferenced photo dataset of 1,449 images collected by researchers and applied AI for optical character recognition (OCR) and language classification. We also conducted manual validations for accuracy checking. This model achieved an overall accuracy of 79%. Five recurring types of mislabeling were identified, including distortion, reflection, degraded surface, graffiti, and hallucination. The analysis also reveals that the AI model treats all regions of an image equally, detecting peripheral or background texts that human interpreters typically ignore. Despite these limitations, the results demonstrate the potential of integrating AI-assisted workflows into LL research to reduce such time-consuming processes. However, due to all the limitations and mis-labels, we recognize that AI cannot be fully trusted during this process. This paper encourages a hybrid approach combining AI automation with human validation for a more reliable and efficient workflow.
SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models
Oct 10, 2025Diffusion large language models (dLLMs) are emerging as an efficient alternative to autoregressive models due to their ability to decode multiple tokens in parallel. However, aligning dLLMs with human preferences or task-specific rewards via reinforcement learning (RL) is challenging because their intractable log-likelihood precludes the direct application of standard policy gradient methods. While prior work uses surrogates like the evidence lower bound (ELBO), these one-sided approximations can introduce significant policy gradient bias. To address this, we propose the Sandwiched Policy Gradient (SPG) that leverages both an upper and a lower bound of the true log-likelihood. Experiments show that SPG significantly outperforms baselines based on ELBO or one-step estimation. Specifically, SPG improves the accuracy over state-of-the-art RL methods for dLLMs by 3.6% in GSM8K, 2.6% in MATH500, 18.4% in Countdown and 27.0% in Sudoku.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
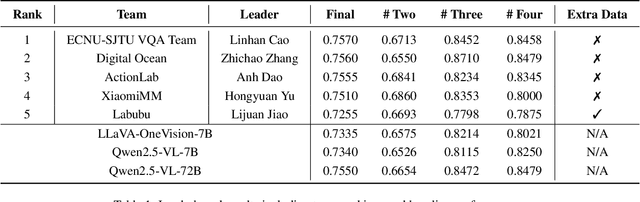
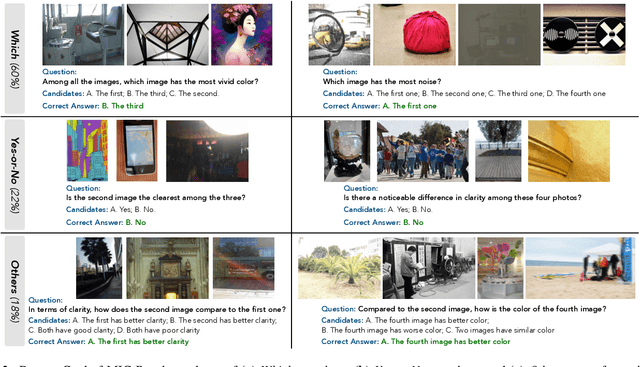
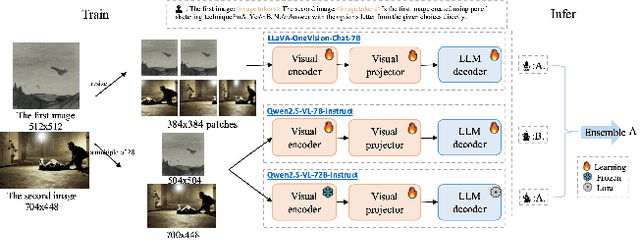
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
FUSE: Measure-Theoretic Compact Fuzzy Set Representation for Taxonomy Expansion
Jun 10, 2025Taxonomy Expansion, which models complex concepts and their relations, can be formulated as a set representation learning task. The generalization of set, fuzzy set, incorporates uncertainty and measures the information within a semantic concept, making it suitable for concept modeling. Existing works usually model sets as vectors or geometric objects such as boxes, which are not closed under set operations. In this work, we propose a sound and efficient formulation of set representation learning based on its volume approximation as a fuzzy set. The resulting embedding framework, Fuzzy Set Embedding (FUSE), satisfies all set operations and compactly approximates the underlying fuzzy set, hence preserving information while being efficient to learn, relying on minimum neural architecture. We empirically demonstrate the power of FUSE on the task of taxonomy expansion, where FUSE achieves remarkable improvements up to 23% compared with existing baselines. Our work marks the first attempt to understand and efficiently compute the embeddings of fuzzy sets.
100-LongBench: Are de facto Long-Context Benchmarks Literally Evaluating Long-Context Ability?
May 25, 2025



Long-context capability is considered one of the most important abilities of LLMs, as a truly long context-capable LLM enables users to effortlessly process many originally exhausting tasks -- e.g., digesting a long-form document to find answers vs. directly asking an LLM about it. However, existing real-task-based long-context evaluation benchmarks have two major shortcomings. First, benchmarks like LongBench often do not provide proper metrics to separate long-context performance from the model's baseline ability, making cross-model comparison unclear. Second, such benchmarks are usually constructed with fixed input lengths, which limits their applicability across different models and fails to reveal when a model begins to break down. To address these issues, we introduce a length-controllable long-context benchmark and a novel metric that disentangles baseline knowledge from true long-context capabilities. Experiments demonstrate the superiority of our approach in effectively evaluating LLMs.
SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
Mar 19, 2025



Large language model (LLM) agents need to perform multi-turn interactions in real-world tasks. However, existing multi-turn RL algorithms for optimizing LLM agents fail to perform effective credit assignment over multiple turns while leveraging the generalization capabilities of LLMs and it remains unclear how to develop such algorithms. To study this, we first introduce a new benchmark, ColBench, where an LLM agent interacts with a human collaborator over multiple turns to solve realistic tasks in backend programming and frontend design. Building on this benchmark, we propose a novel RL algorithm, SWEET-RL (RL with Step-WisE Evaluation from Training-time information), that uses a carefully designed optimization objective to train a critic model with access to additional training-time information. The critic provides step-level rewards for improving the policy model. Our experiments demonstrate that SWEET-RL achieves a 6% absolute improvement in success and win rates on ColBench compared to other state-of-the-art multi-turn RL algorithms, enabling Llama-3.1-8B to match or exceed the performance of GPT4-o in realistic collaborative content creation.
NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions
Feb 18, 2025Scaling reasoning capabilities beyond traditional domains such as math and coding is hindered by the lack of diverse and high-quality questions. To overcome this limitation, we introduce a scalable approach for generating diverse and challenging reasoning questions, accompanied by reference answers. We present NaturalReasoning, a comprehensive dataset comprising 2.8 million questions that span multiple domains, including STEM fields (e.g., Physics, Computer Science), Economics, Social Sciences, and more. We demonstrate the utility of the questions in NaturalReasoning through knowledge distillation experiments which show that NaturalReasoning can effectively elicit and transfer reasoning capabilities from a strong teacher model. Furthermore, we demonstrate that NaturalReasoning is also effective for unsupervised self-training using external reward models or self-rewarding.