 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Vision Transformer with Enhanced Spatial Priors
Apr 20, 2026In recent years, the Vision Transformer (ViT) has garnered significant attention within the computer vision community. However, the core component of ViT, Self-Attention, lacks explicit spatial priors and suffers from quadratic computational complexity, limiting its applicability. To address these issues, we have proposed RMT, a robust vision backbone with explicit spatial priors for general purposes. RMT utilizes Manhattan distance decay to introduce spatial information and employs a horizontal and vertical decomposition attention method to model global information. Building on the strengths of RMT, Euclidean enhanced Vision Transformer (EVT) is an expanded version that incorporates several key improvements. Firstly, EVT uses a more reasonable Euclidean distance decay to enhance the modeling of spatial information, allowing for a more accurate representation of spatial relationships compared to the Manhattan distance used in RMT. Secondly, EVT abandons the decomposed attention mechanism featured in RMT and instead adopts a simpler spatially-independent grouping approach, providing the model with greater flexibility in controlling the number of tokens within each group. By addressing these modifications, EVT offers a more sophisticated and adaptable approach to incorporating spatial priors into the Self-Attention mechanism, thus overcoming some of the limitations associated with RMT and further enhancing its applicability in various computer vision tasks. Extensive experiments on Image Classification, Object Detection, Instance Segmentation, and Semantic Segmentation demonstrate that EVT exhibits exceptional performance. Without additional training data, EVT achieves 86.6% top1-acc on ImageNet-1k.
DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
Mar 27, 2026Data-centric training has emerged as a promising direction for improving large language models (LLMs) by optimizing not only model parameters but also the selection, composition, and weighting of training data during optimization. However, existing approaches to data selection, data mixture optimization, and data reweighting are often developed in isolated codebases with inconsistent interfaces, hindering reproducibility, fair comparison, and practical integration. In this paper, we present DataFlex, a unified data-centric dynamic training framework built upon LLaMA-Factory. DataFlex supports three major paradigms of dynamic data optimization: sample selection, domain mixture adjustment, and sample reweighting, while remaining fully compatible with the original training workflow. It provides extensible trainer abstractions and modular components, enabling a drop-in replacement for standard LLM training, and unifies key model-dependent operations such as embedding extraction, inference, and gradient computation, with support for large-scale settings including DeepSpeed ZeRO-3. We conduct comprehensive experiments across multiple data-centric methods. Dynamic data selection consistently outperforms static full-data training on MMLU across both Mistral-7B and Llama-3.2-3B. For data mixture, DoReMi and ODM improve both MMLU accuracy and corpus-level perplexity over default proportions when pretraining Qwen2.5-1.5B on SlimPajama at 6B and 30B token scales. DataFlex also achieves consistent runtime improvements over original implementations. These results demonstrate that DataFlex provides an effective, efficient, and reproducible infrastructure for data-centric dynamic training of LLMs.
Think 360°: Evaluating the Width-centric Reasoning Capability of MLLMs Beyond Depth
Mar 24, 2026In this paper, we present a holistic multimodal benchmark that evaluates the reasoning capabilities of MLLMs with an explicit focus on reasoning width, a complementary dimension to the more commonly studied reasoning depth. Specifically, reasoning depth measures the model's ability to carry out long-chain, sequential reasoning in which each step is tightly and rigorously linked to the next. Reasoning width tends to focus more on the model's capacity for broad trial-and-error search or multi-constrained optimization: it must systematically traverse many possible and parallelized reasoning paths, apply diverse constraints to prune unpromising branches, and identify valid solution routes for efficient iteration or backtracking. To achieve it, we carefully curate 1200+ high-quality multimodal cases spanning heterogeneous domains, and propose a fine-grained tree-of-thought evaluation protocol that jointly quantifies reasoning width and depth. We evaluate 12 major model families (over 30 advanced MLLMs) across difficulty tiers, question types, and required skills. Results show that while current models exhibit strong performance on general or common-sense VQA tasks, they still struggle to combine deep sequential thought chains with wide exploratory search to perform genuine insight-based reasoning. Finally, we analyze characteristic failure modes to provide possible directions for building MLLMs that reason not only deeper but also wider.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025

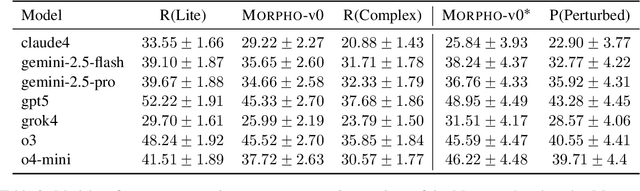
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025



Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
HAD: Hybrid Architecture Distillation Outperforms Teacher in Genomic Sequence Modeling
May 27, 2025Inspired by the great success of Masked Language Modeling (MLM) in the natural language domain, the paradigm of self-supervised pre-training and fine-tuning has also achieved remarkable progress in the field of DNA sequence modeling. However, previous methods often relied on massive pre-training data or large-scale base models with huge parameters, imposing a significant computational burden. To address this, many works attempted to use more compact models to achieve similar outcomes but still fell short by a considerable margin. In this work, we propose a Hybrid Architecture Distillation (HAD) approach, leveraging both distillation and reconstruction tasks for more efficient and effective pre-training. Specifically, we employ the NTv2-500M as the teacher model and devise a grouping masking strategy to align the feature embeddings of visible tokens while concurrently reconstructing the invisible tokens during MLM pre-training. To validate the effectiveness of our proposed method, we conducted comprehensive experiments on the Nucleotide Transformer Benchmark and Genomic Benchmark. Compared to models with similar parameters, our model achieved excellent performance. More surprisingly, it even surpassed the distillation ceiling-teacher model on some sub-tasks, which is more than 500 $\times$ larger. Lastly, we utilize t-SNE for more intuitive visualization, which shows that our model can gain a sophisticated understanding of the intrinsic representation pattern in genomic sequences.