 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
JetViT: Efficient High-Resolution Vision Transformer with Post-Training Attention Search
May 26, 2026We introduce JetViT, a novel family of hybrid-architecture Vision Transformer (ViT) models that match the accuracy of state-of-the-art full-attention vision foundation models while achieving substantially higher inference efficiency on high-resolution images. At the core of our approach is Post-Training Attention Search, a post-training acceleration framework that converts pre-trained full-attention ViTs into efficient hybrid-attention variants by identifying and replacing redundant full-attention blocks with linear or window-attention blocks. By inheriting the MLP and attention weights from the base model, Post-Training Attention Search efficiently explores the architectural design space through three key steps: (1) optimizing the linear-attention block design; (2) finding the best combination of linear-attention and window-attention blocks; and (3) identifying and preserving critical full-attention blocks. We evaluate JetViT on two representative high-resolution vision foundation models, DINOv3 and DepthAnythingV2. On the NVIDIA H100 GPU, JetViT achieves up to 1.79x higher throughput and up to 44.81% lower latency without sacrificing accuracy. We will release our code and accelerated ViT models soon.
ConFit v3: Improving Resume-Job Matching with LLM-based Re-Ranking
May 10, 2026A reliable resume-job matching system helps a company find suitable candidates from a pool of resumes and helps a job seeker find relevant jobs from a list of job posts. While recent advances in embedding-based methods such as ConFit and ConFit v2 can efficiently retrieve candidates at scale, the lack of controllability and explainability limits their real-world adaptations. LLM-based re-rankers can address these limitations through reasoning, but existing training recipes are developed on short-document benchmarks and do not account for noise in real-world recruiting data. In this work, we first conduct a systematic analysis over the LLM re-ranker training pipeline for person-job fit, covering inference algorithm design, RL algorithm selection, data processing, and SFT distillation. We find that using multi-pass re-ranking, training with listwise RL objectives, removing noisy samples, and distilling from a stronger LLM before RL significantly improves re-ranking performance. We then aggregate these findings to train ConFit v3 with Qwen3-8B and Qwen3-32B on real-world person-job fit datasets, and find significant improvements over existing best person-job fit systems as well as strong LLMs such as GPT-5 and Claude Opus-4.5. We hope our findings provide useful insights for future research on adapting LLM-based re-rankers to person-job fit systems.
CuraLight: Debate-Guided Data Curation for LLM-Centered Traffic Signal Control
Apr 07, 2026Traffic signal control (TSC) is a core component of intelligent transportation systems (ITS), aiming to reduce congestion, emissions, and travel time. Recent approaches based on reinforcement learning (RL) and large language models (LLMs) have improved adaptivity, but still suffer from limited interpretability, insufficient interaction data, and weak generalization to heterogeneous intersections. This paper proposes CuraLight, an LLM-centered framework where an RL agent assists the fine-tuning of an LLM-based traffic signal controller. The RL agent explores traffic environments and generates high-quality interaction trajectories, which are converted into prompt-response pairs for imitation fine-tuning. A multi-LLM ensemble deliberation system further evaluates candidate signal timing actions through structured debate, providing preference-aware supervision signals for training. Experiments conducted in SUMO across heterogeneous real-world networks from Jinan, Hangzhou, and Yizhuang demonstrate that CuraLight consistently outperforms state-of-the-art baselines, reducing average travel time by 5.34 percent, average queue length by 5.14 percent, and average waiting time by 7.02 percent. The results highlight the effectiveness of combining RL-assisted exploration with deliberation-based data curation for scalable and interpretable traffic signal control.
Solving a Nonlinear Blind Inverse Problem for Tagged MRI with Physics and Deep Generative Priors
Mar 01, 2026Tagged MRI enables tracking internal tissue motion non-invasively. It encodes motion by modulating anatomy with periodic tags, which deform along with tissue. However, the entanglement between anatomy, tags and motion poses significant challenges for post-processing. The existence of tags and imaging blur hinders downstream tasks such as segmenting anatomy. Tag fading, due to T1-relaxation, disrupts the brightness constancy assumption for motion tracking. For decades, these challenges have been handled in isolation and sub-optimally. In contrast, we introduce a blind and nonlinear inverse framework for tagged MRI that, for the first time, unifies these tasks: anatomical image recovery, high-resolution cine image synthesis, and motion estimation. At its core, the synergy of MR physics and generative priors enables us to blindly estimate the unknown forward imaging models and high-resolution underlying anatomy, while simultaneously tracking 3D diffeomorphic Lagrangian motion over time. Experiments on tagged brain MRI demonstrate that our approach yields high-resolution anatomy images, cine images, and more accurate motion than specialized methods.
Transformer-based CoVaR: Systemic Risk in Textual Information
Feb 13, 2026Conditional Value-at-Risk (CoVaR) quantifies systemic financial risk by measuring the loss quantile of one asset, conditional on another asset experiencing distress. We develop a Transformer-based methodology that integrates financial news articles directly with market data to improve CoVaR estimates. Unlike approaches that use predefined sentiment scores, our method incorporates raw text embeddings generated by a large language model (LLM). We prove explicit error bounds for our Transformer CoVaR estimator, showing that accurate CoVaR learning is possible even with small datasets. Using U.S. market returns and Reuters news items from 2006--2013, our out-of-sample results show that textual information impacts the CoVaR forecasts. With better predictive performance, we identify a pronounced negative dip during market stress periods across several equity assets when comparing the Transformer-based CoVaR to both the CoVaR without text and the CoVaR using traditional sentiment measures. Our results show that textual data can be used to effectively model systemic risk without requiring prohibitively large data sets.
BPDQ: Bit-Plane Decomposition Quantization on a Variable Grid for Large Language Models
Feb 04, 2026Large language model (LLM) inference is often bounded by memory footprint and memory bandwidth in resource-constrained deployments, making quantization a fundamental technique for efficient serving. While post-training quantization (PTQ) maintains high fidelity at 4-bit, it deteriorates at 2-3 bits. Fundamentally, existing methods enforce a shape-invariant quantization grid (e.g., the fixed uniform intervals of UINT2) for each group, severely restricting the feasible set for error minimization. To address this, we propose Bit-Plane Decomposition Quantization (BPDQ), which constructs a variable quantization grid via bit-planes and scalar coefficients, and iteratively refines them using approximate second-order information while progressively compensating quantization errors to minimize output discrepancy. In the 2-bit regime, BPDQ enables serving Qwen2.5-72B on a single RTX 3090 with 83.85% GSM8K accuracy (vs. 90.83% at 16-bit). Moreover, we provide theoretical analysis showing that the variable grid expands the feasible set, and that the quantization process consistently aligns with the optimization objective in Hessian-induced geometry. Code: github.com/KingdalfGoodman/BPDQ.
Deep classifier kriging for probabilistic spatial prediction of air quality index
Dec 29, 2025Accurate spatial interpolation of the air quality index (AQI), computed from concentrations of multiple air pollutants, is essential for regulatory decision-making, yet AQI fields are inherently non-Gaussian and often exhibit complex nonlinear spatial structure. Classical spatial prediction methods such as kriging are linear and rely on Gaussian assumptions, which limits their ability to capture these features and to provide reliable predictive distributions. In this study, we propose \textit{deep classifier kriging} (DCK), a flexible, distribution-free deep learning framework for estimating full predictive distribution functions for univariate and bivariate spatial processes, together with a \textit{data fusion} mechanism that enables modeling of non-collocated bivariate processes and integration of heterogeneous air pollution data sources. Through extensive simulation experiments, we show that DCK consistently outperforms conventional approaches in predictive accuracy and uncertainty quantification. We further apply DCK to probabilistic spatial prediction of AQI by fusing sparse but high-quality station observations with spatially continuous yet biased auxiliary model outputs, yielding spatially resolved predictive distributions that support downstream tasks such as exceedance and extreme-event probability estimation for regulatory risk assessment and policy formulation.
Retrieval Augmented Generation-Enhanced Distributed LLM Agents for Generalizable Traffic Signal Control with Emergency Vehicles
Oct 30, 2025



With increasing urban traffic complexity, Traffic Signal Control (TSC) is essential for optimizing traffic flow and improving road safety. Large Language Models (LLMs) emerge as promising approaches for TSC. However, they are prone to hallucinations in emergencies, leading to unreliable decisions that may cause substantial delays for emergency vehicles. Moreover, diverse intersection types present substantial challenges for traffic state encoding and cross-intersection training, limiting generalization across heterogeneous intersections. Therefore, this paper proposes Retrieval Augmented Generation (RAG)-enhanced distributed LLM agents with Emergency response for Generalizable TSC (REG-TSC). Firstly, this paper presents an emergency-aware reasoning framework, which dynamically adjusts reasoning depth based on the emergency scenario and is equipped with a novel Reviewer-based Emergency RAG (RERAG) to distill specific knowledge and guidance from historical cases, enhancing the reliability and rationality of agents' emergency decisions. Secondly, this paper designs a type-agnostic traffic representation and proposes a Reward-guided Reinforced Refinement (R3) for heterogeneous intersections. R3 adaptively samples training experience from diverse intersections with environment feedback-based priority and fine-tunes LLM agents with a designed reward-weighted likelihood loss, guiding REG-TSC toward high-reward policies across heterogeneous intersections. On three real-world road networks with 17 to 177 heterogeneous intersections, extensive experiments show that REG-TSC reduces travel time by 42.00%, queue length by 62.31%, and emergency vehicle waiting time by 83.16%, outperforming other state-of-the-art methods.
Deep learning-derived arterial input function
May 30, 2025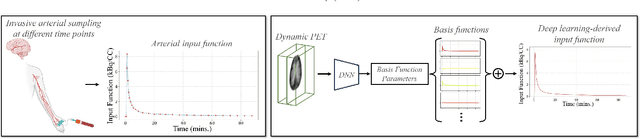

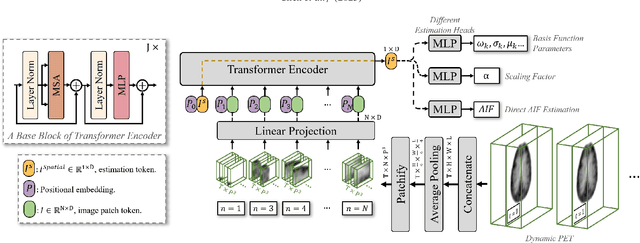
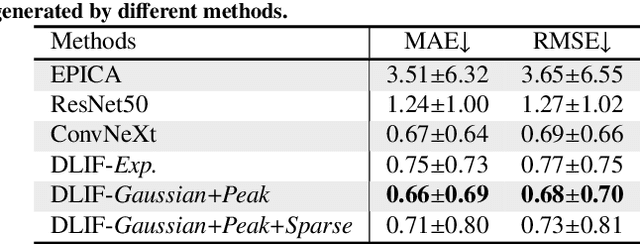
Dynamic positron emission tomography (PET) imaging combined with radiotracer kinetic modeling is a powerful technique for visualizing biological processes in the brain, offering valuable insights into brain functions and neurological disorders such as Alzheimer's and Parkinson's diseases. Accurate kinetic modeling relies heavily on the use of a metabolite-corrected arterial input function (AIF), which typically requires invasive and labor-intensive arterial blood sampling. While alternative non-invasive approaches have been proposed, they often compromise accuracy or still necessitate at least one invasive blood sampling. In this study, we present the deep learning-derived arterial input function (DLIF), a deep learning framework capable of estimating a metabolite-corrected AIF directly from dynamic PET image sequences without any blood sampling. We validated DLIF using existing dynamic PET patient data. We compared DLIF and resulting parametric maps against ground truth measurements. Our evaluation shows that DLIF achieves accurate and robust AIF estimation. By leveraging deep learning's ability to capture complex temporal dynamics and incorporating prior knowledge of typical AIF shapes through basis functions, DLIF provides a rapid, accurate, and entirely non-invasive alternative to traditional AIF measurement methods.