 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
VIP: Visual-guided Prompt Evolution for Efficient Dense Vision-Language Inference
May 13, 2026Pursuing training-free open-vocabulary semantic segmentation in an efficient and generalizable manner remains challenging due to the deep-seated spatial bias in CLIP. To overcome the limitations of existing solutions, this work moves beyond the CLIP-based paradigm and harnesses the recent spatially-aware dino$.$txt framework to facilitate more efficient and high-quality dense prediction. While dino$.$txt exhibits robust spatial awareness, we find that the semantic ambiguity of text queries gives rise to severe mismatch within its dense cross-modal interactions. To address this, we introduce Visual-guided Prompt evolution (VIP) to rectify the semantic expressiveness of text queries in dino$.$txt, unleashing its potential for fine-grained object perception. Towards this end, VIP integrates alias expansion with a visual-guided distillation mechanism to mine valuable semantic cues, which are robustly aggregated in a saliency-aware manner to yield a high-fidelity prediction. Extensive evaluations demonstrate that VIP: 1. surpasses the top-leading methods by 1.4%-8.4% average mIoU, 2. generalizes well to diverse challenging domains, and 3. requires marginal inference time and memory overhead.
Video-based Heart Rate Estimation with Angle-guided ROI Optimization and Graph Signal Denoising
Apr 13, 2026Remote photoplethysmography (rPPG) enables non-contact heart rate measurement from facial videos, but its performance is significantly degraded by facial motions such as speaking and head shaking. To address this issue, we propose two plug-and-play modules. The Angle-guided ROI Adaptive Optimization module quantifies ROI-Camera angles to refine motion-affected signals and capture global motion, while the Multi-region Joint Graph Signal Denoising module jointly models intra- and inter-regional ROI signals using graph signal processing to suppress motion artifacts. The modules are compatible with reflection model-based rPPG methods and validated on three public datasets. Results show that jointly use markedly reduces MAE, with an average decrease of 20.38\% over the baseline, while ablation studies confirm the effectiveness of each module. The work demonstrates the potential of angle-guided optimization and graph-based denoising to enhance rPPG performance in motion scenarios.
Development and multi-center evaluation of domain-adapted speech recognition for human-AI teaming in real-world gastrointestinal endoscopy
Apr 02, 2026Automatic speech recognition (ASR) is a critical interface for human-AI interaction in gastrointestinal endoscopy, yet its reliability in real-world clinical settings is limited by domain-specific terminology and complex acoustic conditions. Here, we present EndoASR, a domain-adapted ASR system designed for real-time deployment in endoscopic workflows. We develop a two-stage adaptation strategy based on synthetic endoscopy reports, targeting domain-specific language modeling and noise robustness. In retrospective evaluation across six endoscopists, EndoASR substantially improves both transcription accuracy and clinical usability, reducing character error rate (CER) from 20.52% to 14.14% and increasing medical term accuracy (Med ACC) from 54.30% to 87.59%. In a prospective multi-center study spanning five independent endoscopy centers, EndoASR demonstrates consistent generalization under heterogeneous real-world conditions. Compared with the baseline Paraformer model, CER is reduced from 16.20% to 14.97%, while Med ACC is improved from 61.63% to 84.16%, confirming its robustness in practical deployment scenarios. Notably, EndoASR achieves a real-time factor (RTF) of 0.005, significantly faster than Whisper-large-v3 (RTF 0.055), while maintaining a compact model size of 220M parameters, enabling efficient edge deployment. Furthermore, integration with large language models demonstrates that improved ASR quality directly enhances downstream structured information extraction and clinician-AI interaction. These results demonstrate that domain-adapted ASR can serve as a reliable interface for human-AI teaming in gastrointestinal endoscopy, with consistent performance validated across multi-center real-world clinical settings.
GI-Bench: A Panoramic Benchmark Revealing the Knowledge-Experience Dissociation of Multimodal Large Language Models in Gastrointestinal Endoscopy Against Clinical Standards
Jan 13, 2026Multimodal Large Language Models (MLLMs) show promise in gastroenterology, yet their performance against comprehensive clinical workflows and human benchmarks remains unverified. To systematically evaluate state-of-the-art MLLMs across a panoramic gastrointestinal endoscopy workflow and determine their clinical utility compared with human endoscopists. We constructed GI-Bench, a benchmark encompassing 20 fine-grained lesion categories. Twelve MLLMs were evaluated across a five-stage clinical workflow: anatomical localization, lesion identification, diagnosis, findings description, and management. Model performance was benchmarked against three junior endoscopists and three residency trainees using Macro-F1, mean Intersection-over-Union (mIoU), and multi-dimensional Likert scale. Gemini-3-Pro achieved state-of-the-art performance. In diagnostic reasoning, top-tier models (Macro-F1 0.641) outperformed trainees (0.492) and rivaled junior endoscopists (0.727; p>0.05). However, a critical "spatial grounding bottleneck" persisted; human lesion localization (mIoU >0.506) significantly outperformed the best model (0.345; p<0.05). Furthermore, qualitative analysis revealed a "fluency-accuracy paradox": models generated reports with superior linguistic readability compared with humans (p<0.05) but exhibited significantly lower factual correctness (p<0.05) due to "over-interpretation" and hallucination of visual features.GI-Bench maintains a dynamic leaderboard that tracks the evolving performance of MLLMs in clinical endoscopy. The current rankings and benchmark results are available at https://roterdl.github.io/GIBench/.
TEA: Temporal Adaptive Satellite Image Semantic Segmentation
Jan 08, 2026Crop mapping based on satellite images time-series (SITS) holds substantial economic value in agricultural production settings, in which parcel segmentation is an essential step. Existing approaches have achieved notable advancements in SITS segmentation with predetermined sequence lengths. However, we found that these approaches overlooked the generalization capability of models across scenarios with varying temporal length, leading to markedly poor segmentation results in such cases. To address this issue, we propose TEA, a TEmporal Adaptive SITS semantic segmentation method to enhance the model's resilience under varying sequence lengths. We introduce a teacher model that encapsulates the global sequence knowledge to guide a student model with adaptive temporal input lengths. Specifically, teacher shapes the student's feature space via intermediate embedding, prototypes and soft label perspectives to realize knowledge transfer, while dynamically aggregating student model to mitigate knowledge forgetting. Finally, we introduce full-sequence reconstruction as an auxiliary task to further enhance the quality of representations across inputs of varying temporal lengths. Through extensive experiments, we demonstrate that our method brings remarkable improvements across inputs of different temporal lengths on common benchmarks. Our code will be publicly available.
One-shot synthesis of rare gastrointestinal lesions improves diagnostic accuracy and clinical training
Dec 30, 2025Rare gastrointestinal lesions are infrequently encountered in routine endoscopy, restricting the data available for developing reliable artificial intelligence (AI) models and training novice clinicians. Here we present EndoRare, a one-shot, retraining-free generative framework that synthesizes diverse, high-fidelity lesion exemplars from a single reference image. By leveraging language-guided concept disentanglement, EndoRare separates pathognomonic lesion features from non-diagnostic attributes, encoding the former into a learnable prototype embedding while varying the latter to ensure diversity. We validated the framework across four rare pathologies (calcifying fibrous tumor, juvenile polyposis syndrome, familial adenomatous polyposis, and Peutz-Jeghers syndrome). Synthetic images were judged clinically plausible by experts and, when used for data augmentation, significantly enhanced downstream AI classifiers, improving the true positive rate at low false-positive rates. Crucially, a blinded reader study demonstrated that novice endoscopists exposed to EndoRare-generated cases achieved a 0.400 increase in recall and a 0.267 increase in precision. These results establish a practical, data-efficient pathway to bridge the rare-disease gap in both computer-aided diagnostics and clinical education.
Artificial intelligence for representing and characterizing quantum systems
Sep 05, 2025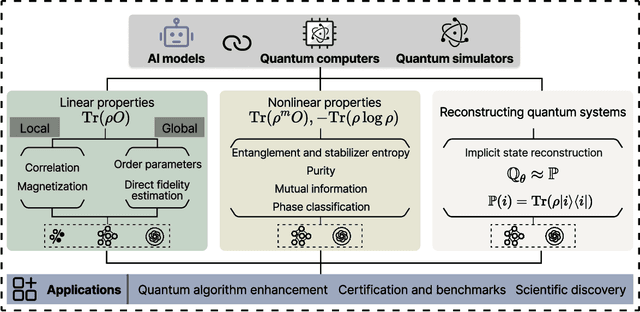

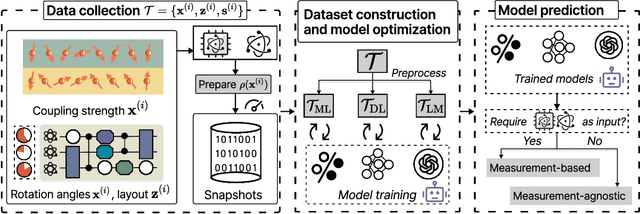
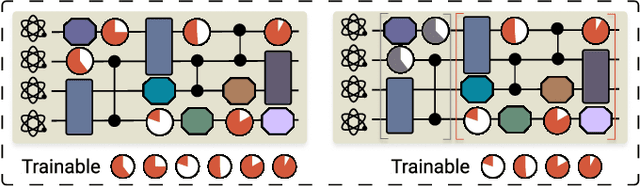
Efficient characterization of large-scale quantum systems, especially those produced by quantum analog simulators and megaquop quantum computers, poses a central challenge in quantum science due to the exponential scaling of the Hilbert space with respect to system size. Recent advances in artificial intelligence (AI), with its aptitude for high-dimensional pattern recognition and function approximation, have emerged as a powerful tool to address this challenge. A growing body of research has leveraged AI to represent and characterize scalable quantum systems, spanning from theoretical foundations to experimental realizations. Depending on how prior knowledge and learning architectures are incorporated, the integration of AI into quantum system characterization can be categorized into three synergistic paradigms: machine learning, and, in particular, deep learning and language models. This review discusses how each of these AI paradigms contributes to two core tasks in quantum systems characterization: quantum property prediction and the construction of surrogates for quantum states. These tasks underlie diverse applications, from quantum certification and benchmarking to the enhancement of quantum algorithms and the understanding of strongly correlated phases of matter. Key challenges and open questions are also discussed, together with future prospects at the interface of AI and quantum science.
EndoFinder: Online Lesion Retrieval for Explainable Colorectal Polyp Diagnosis Leveraging Latent Scene Representations
Jul 23, 2025Colorectal cancer (CRC) remains a leading cause of cancer-related mortality, underscoring the importance of timely polyp detection and diagnosis. While deep learning models have improved optical-assisted diagnostics, they often demand extensive labeled datasets and yield "black-box" outputs with limited interpretability. In this paper, we propose EndoFinder, an online polyp retrieval framework that leverages multi-view scene representations for explainable and scalable CRC diagnosis. First, we develop a Polyp-aware Image Encoder by combining contrastive learning and a reconstruction task, guided by polyp segmentation masks. This self-supervised approach captures robust features without relying on large-scale annotated data. Next, we treat each polyp as a three-dimensional "scene" and introduce a Scene Representation Transformer, which fuses multiple views of the polyp into a single latent representation. By discretizing this representation through a hashing layer, EndoFinder enables real-time retrieval from a compiled database of historical polyp cases, where diagnostic information serves as interpretable references for new queries. We evaluate EndoFinder on both public and newly collected polyp datasets for re-identification and pathology classification. Results show that EndoFinder outperforms existing methods in accuracy while providing transparent, retrieval-based insights for clinical decision-making. By contributing a novel dataset and a scalable, explainable framework, our work addresses key challenges in polyp diagnosis and offers a promising direction for more efficient AI-driven colonoscopy workflows. The source code is available at https://github.com/ku262/EndoFinder-Scene.
Endo-CLIP: Progressive Self-Supervised Pre-training on Raw Colonoscopy Records
May 14, 2025



Pre-training on image-text colonoscopy records offers substantial potential for improving endoscopic image analysis, but faces challenges including non-informative background images, complex medical terminology, and ambiguous multi-lesion descriptions. We introduce Endo-CLIP, a novel self-supervised framework that enhances Contrastive Language-Image Pre-training (CLIP) for this domain. Endo-CLIP's three-stage framework--cleansing, attunement, and unification--addresses these challenges by (1) removing background frames, (2) leveraging large language models to extract clinical attributes for fine-grained contrastive learning, and (3) employing patient-level cross-attention to resolve multi-polyp ambiguities. Extensive experiments demonstrate that Endo-CLIP significantly outperforms state-of-the-art pre-training methods in zero-shot and few-shot polyp detection and classification, paving the way for more accurate and clinically relevant endoscopic analysis.