 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptReverb: Multimodal Room Impulse Response Generation Through Latent Rectified Flow Matching
Oct 25, 2025Room impulse response (RIR) generation remains a critical challenge for creating immersive virtual acoustic environments. Current methods suffer from two fundamental limitations: the scarcity of full-band RIR datasets and the inability of existing models to generate acoustically accurate responses from diverse input modalities. We present PromptReverb, a two-stage generative framework that addresses these challenges. Our approach combines a variational autoencoder that upsamples band-limited RIRs to full-band quality (48 kHz), and a conditional diffusion transformer model based on rectified flow matching that generates RIRs from descriptions in natural language. Empirical evaluation demonstrates that PromptReverb produces RIRs with superior perceptual quality and acoustic accuracy compared to existing methods, achieving 8.8% mean RT60 error compared to -37% for widely used baselines and yielding more realistic room-acoustic parameters. Our method enables practical applications in virtual reality, architectural acoustics, and audio production where flexible, high-quality RIR synthesis is essential.
Diagnosing Visual Reasoning: Challenges, Insights, and a Path Forward
Oct 23, 2025Multimodal large language models (MLLMs) that integrate visual and textual reasoning leverage chain-of-thought (CoT) prompting to tackle complex visual tasks, yet continue to exhibit visual hallucinations and an over-reliance on textual priors. We present a systematic diagnosis of state-of-the-art vision-language models using a three-stage evaluation framework, uncovering key failure modes. To address these, we propose an agent-based architecture that combines LLM reasoning with lightweight visual modules, enabling fine-grained analysis and iterative refinement of reasoning chains. Our results highlight future visual reasoning models should focus on integrating a broader set of specialized tools for analyzing visual content. Our system achieves significant gains (+10.3 on MMMU, +6.0 on MathVista over a 7B baseline), matching or surpassing much larger models. We will release our framework and evaluation suite to facilitate future research.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025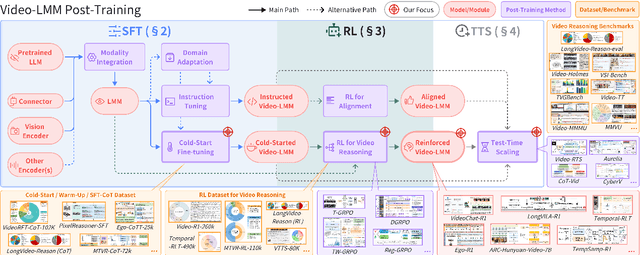
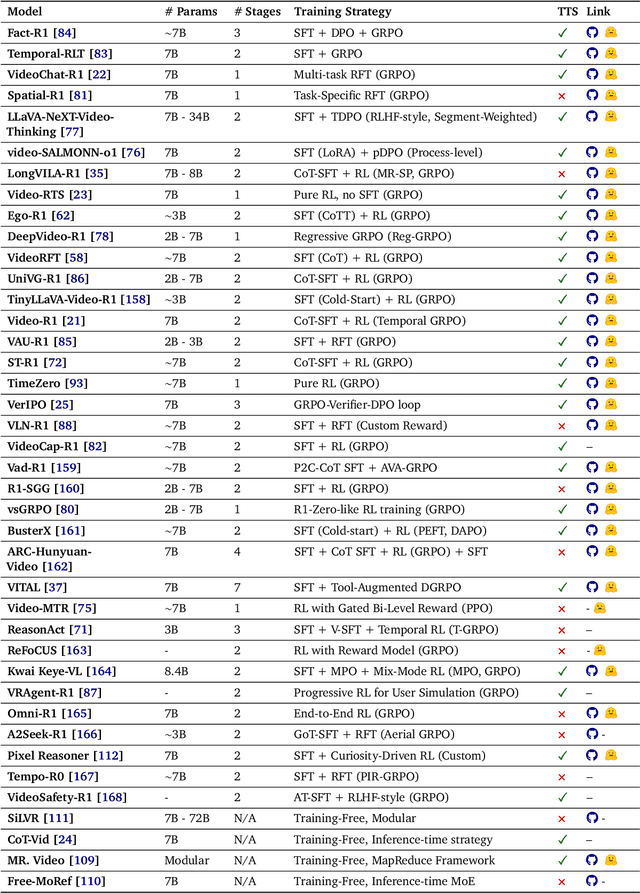
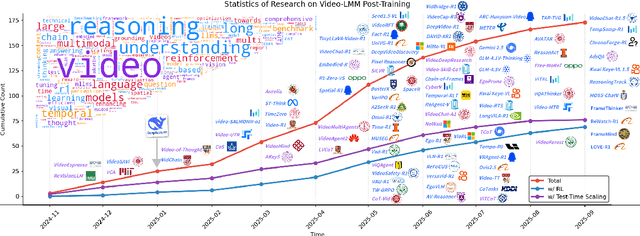
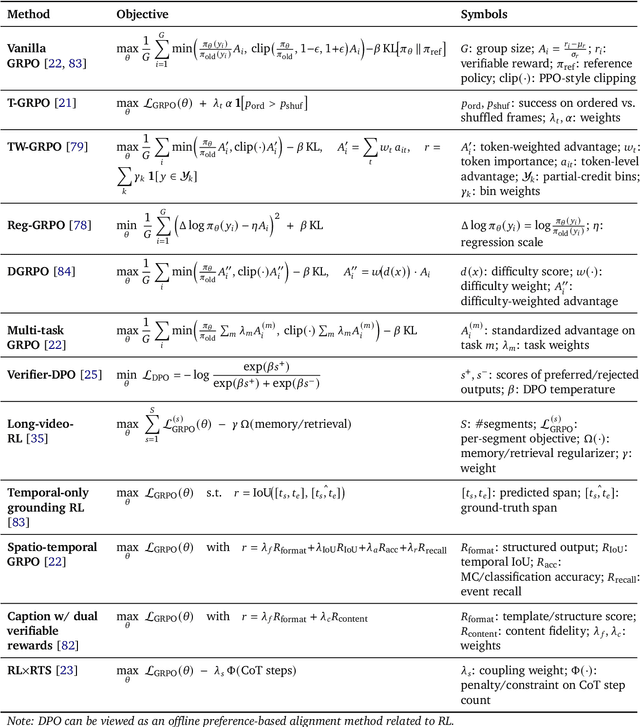
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
Can Sound Replace Vision in LLaVA With Token Substitution?
Jun 12, 2025While multimodal systems have achieved impressive advances, they typically rely on text-aligned representations rather than directly integrating audio and visual inputs. This reliance can limit the use of acoustic information in tasks requiring nuanced audio understanding. In response, SoundCLIP explores direct audio-visual integration within multimodal large language models (MLLMs) by substituting CLIP's visual tokens with audio representations and selecting sound-relevant patch tokens in models such as LLaVA. We investigate two configurations: (1) projecting audio features into CLIP's visual manifold via a multilayer perceptron trained with InfoNCE on paired audio-video segments, and (2) preserving raw audio embeddings with minimal dimensional adjustments. Experiments with five state-of-the-art audio encoders reveal a fundamental trade-off. While audio-to-video retrieval performance increases dramatically (up to 44 percentage points in Top-1 accuracy) when audio is projected into CLIP's space, text generation quality declines. Encoders pre-trained with text supervision (CLAP, Whisper, ImageBind) maintain stronger generative capabilities than those focused primarily on audiovisual alignment (Wav2CLIP, AudioCLIP), highlighting the value of language exposure for generation tasks. We introduce WhisperCLIP, an architecture that fuses intermediate representations from Whisper, as well as AudioVisual Event Evaluation (AVE-2), a dataset of 580,147 three-second audiovisual clips with fine-grained alignment annotations. Our findings challenge the assumption that stronger cross-modal alignment necessarily benefits all multimodal tasks; instead, a Pareto frontier emerges wherein optimal performance depends on balancing retrieval accuracy with text generation quality. Codes and datasets: https://github.com/ali-vosoughi/SoundCLIP.
MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness
May 26, 2025Understanding perspective is fundamental to human visual perception, yet the extent to which multimodal large language models (MLLMs) internalize perspective geometry remains unclear. We introduce MMPerspective, the first benchmark specifically designed to systematically evaluate MLLMs' understanding of perspective through 10 carefully crafted tasks across three complementary dimensions: Perspective Perception, Reasoning, and Robustness. Our benchmark comprises 2,711 real-world and synthetic image instances with 5,083 question-answer pairs that probe key capabilities, such as vanishing point perception and counting, perspective type reasoning, line relationship understanding in 3D space, invariance to perspective-preserving transformations, etc. Through a comprehensive evaluation of 43 state-of-the-art MLLMs, we uncover significant limitations: while models demonstrate competence on surface-level perceptual tasks, they struggle with compositional reasoning and maintaining spatial consistency under perturbations. Our analysis further reveals intriguing patterns between model architecture, scale, and perspective capabilities, highlighting both robustness bottlenecks and the benefits of chain-of-thought prompting. MMPerspective establishes a valuable testbed for diagnosing and advancing spatial understanding in vision-language systems. Resources available at: https://yunlong10.github.io/MMPerspective/
$I^2G$: Generating Instructional Illustrations via Text-Conditioned Diffusion
May 22, 2025



The effective communication of procedural knowledge remains a significant challenge in natural language processing (NLP), as purely textual instructions often fail to convey complex physical actions and spatial relationships. We address this limitation by proposing a language-driven framework that translates procedural text into coherent visual instructions. Our approach models the linguistic structure of instructional content by decomposing it into goal statements and sequential steps, then conditioning visual generation on these linguistic elements. We introduce three key innovations: (1) a constituency parser-based text encoding mechanism that preserves semantic completeness even with lengthy instructions, (2) a pairwise discourse coherence model that maintains consistency across instruction sequences, and (3) a novel evaluation protocol specifically designed for procedural language-to-image alignment. Our experiments across three instructional datasets (HTStep, CaptainCook4D, and WikiAll) demonstrate that our method significantly outperforms existing baselines in generating visuals that accurately reflect the linguistic content and sequential nature of instructions. This work contributes to the growing body of research on grounding procedural language in visual content, with applications spanning education, task guidance, and multimodal language understanding.
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
VERIFY: A Benchmark of Visual Explanation and Reasoning for Investigating Multimodal Reasoning Fidelity
Mar 14, 2025Visual reasoning is central to human cognition, enabling individuals to interpret and abstractly understand their environment. Although recent Multimodal Large Language Models (MLLMs) have demonstrated impressive performance across language and vision-language tasks, existing benchmarks primarily measure recognition-based skills and inadequately assess true visual reasoning capabilities. To bridge this critical gap, we introduce VERIFY, a benchmark explicitly designed to isolate and rigorously evaluate the visual reasoning capabilities of state-of-the-art MLLMs. VERIFY compels models to reason primarily from visual information, providing minimal textual context to reduce reliance on domain-specific knowledge and linguistic biases. Each problem is accompanied by a human-annotated reasoning path, making it the first to provide in-depth evaluation of model decision-making processes. Additionally, we propose novel metrics that assess visual reasoning fidelity beyond mere accuracy, highlighting critical imbalances in current model reasoning patterns. Our comprehensive benchmarking of leading MLLMs uncovers significant limitations, underscoring the need for a balanced and holistic approach to both perception and reasoning. For more teaser and testing, visit our project page (https://verify-eqh.pages.dev/).
Quality Over Quantity? LLM-Based Curation for a Data-Efficient Audio-Video Foundation Model
Mar 12, 2025Integrating audio and visual data for training multimodal foundational models remains challenging. We present Audio-Video Vector Alignment (AVVA), which aligns audiovisual (AV) scene content beyond mere temporal synchronization via a Large Language Model (LLM)-based data curation pipeline. Specifically, AVVA scores and selects high-quality training clips using Whisper (speech-based audio foundation model) for audio and DINOv2 for video within a dual-encoder contrastive learning framework. Evaluations on AudioCaps, VALOR, and VGGSound demonstrate that this approach can achieve significant accuracy gains with substantially less curated data. For instance, AVVA yields a 7.6% improvement in top-1 accuracy for audio-to-video retrieval on VGGSound compared to ImageBind, despite training on only 192 hours of carefully filtered data (vs. 5800+ hours). Moreover, an ablation study highlights that trading data quantity for data quality improves performance, yielding respective top-3 accuracy increases of 47.8, 48.4, and 58.0 percentage points on AudioCaps, VALOR, and VGGSound over uncurated baselines. While these results underscore AVVA's data efficiency, we also discuss the overhead of LLM-driven curation and how it may be scaled or approximated in larger domains. Overall, AVVA provides a viable path toward more robust, text-free audiovisual learning with improved retrieval accuracy.
Enhancing Graph Attention Neural Network Performance for Marijuana Consumption Classification through Large-scale Augmented Granger Causality (lsAGC) Analysis of Functional MR Images
Oct 24, 2024In the present research, the effectiveness of large-scale Augmented Granger Causality (lsAGC) as a tool for gauging brain network connectivity was examined to differentiate between marijuana users and typical controls by utilizing resting-state functional Magnetic Resonance Imaging (fMRI). The relationship between marijuana consumption and alterations in brain network connectivity is a recognized fact in scientific literature. This study probes how lsAGC can accurately discern these changes. The technique used integrates dimension reduction with the augmentation of source time-series in a model that predicts time-series, which helps in estimating the directed causal relationships among fMRI time-series. As a multivariate approach, lsAGC uncovers the connection of the inherent dynamic system while considering all other time-series. A dataset of 60 adults with an ADHD diagnosis during childhood, drawn from the Addiction Connectome Preprocessed Initiative (ACPI), was used in the study. The brain connections assessed by lsAGC were utilized as classification attributes. A Graph Attention Neural Network (GAT) was chosen to carry out the classification task, particularly for its ability to harness graph-based data and recognize intricate interactions between brain regions, making it appropriate for fMRI-based brain connectivity data. The performance was analyzed using a five-fold cross-validation system. The average accuracy achieved by the correlation coefficient method was roughly 52.98%, with a 1.65 standard deviation, whereas the lsAGC approach yielded an average accuracy of 61.47%, with a standard deviation of 1.44. The suggested method enhances the body of knowledge in the field of neuroimaging-based classification and emphasizes the necessity to consider directed causal connections in brain network connectivity analysis when studying marijuana's effects on the brain.