 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoorSim-to-OutdoorReal: Learning to Navigate Outdoors without any Outdoor Experience
May 10, 2023We present IndoorSim-to-OutdoorReal (I2O), an end-to-end learned visual navigation approach, trained solely in simulated short-range indoor environments, and demonstrates zero-shot sim-to-real transfer to the outdoors for long-range navigation on the Spot robot. Our method uses zero real-world experience (indoor or outdoor), and requires the simulator to model no predominantly-outdoor phenomenon (sloped grounds, sidewalks, etc). The key to I2O transfer is in providing the robot with additional context of the environment (i.e., a satellite map, a rough sketch of a map by a human, etc.) to guide the robot's navigation in the real-world. The provided context-maps do not need to be accurate or complete -- real-world obstacles (e.g., trees, bushes, pedestrians, etc.) are not drawn on the map, and openings are not aligned with where they are in the real-world. Crucially, these inaccurate context-maps provide a hint to the robot about a route to take to the goal. We find that our method that leverages Context-Maps is able to successfully navigate hundreds of meters in novel environments, avoiding novel obstacles on its path, to a distant goal without a single collision or human intervention. In comparison, policies without the additional context fail completely. Lastly, we test the robustness of the Context-Map policy by adding varying degrees of noise to the map in simulation. We find that the Context-Map policy is surprisingly robust to noise in the provided context-map. In the presence of significantly inaccurate maps (corrupted with 50% noise, or entirely blank maps), the policy gracefully regresses to the behavior of a policy with no context. Videos are available at https://www.joannetruong.com/projects/i2o.html
Learning and Adapting Agile Locomotion Skills by Transferring Experience
Apr 19, 2023



Legged robots have enormous potential in their range of capabilities, from navigating unstructured terrains to high-speed running. However, designing robust controllers for highly agile dynamic motions remains a substantial challenge for roboticists. Reinforcement learning (RL) offers a promising data-driven approach for automatically training such controllers. However, exploration in these high-dimensional, underactuated systems remains a significant hurdle for enabling legged robots to learn performant, naturalistic, and versatile agility skills. We propose a framework for training complex robotic skills by transferring experience from existing controllers to jumpstart learning new tasks. To leverage controllers we can acquire in practice, we design this framework to be flexible in terms of their source -- that is, the controllers may have been optimized for a different objective under different dynamics, or may require different knowledge of the surroundings -- and thus may be highly suboptimal for the target task. We show that our method enables learning complex agile jumping behaviors, navigating to goal locations while walking on hind legs, and adapting to new environments. We also demonstrate that the agile behaviors learned in this way are graceful and safe enough to deploy in the real world.
Continuous Versatile Jumping Using Learned Action Residuals
Apr 17, 2023



Jumping is essential for legged robots to traverse through difficult terrains. In this work, we propose a hierarchical framework that combines optimal control and reinforcement learning to learn continuous jumping motions for quadrupedal robots. The core of our framework is a stance controller, which combines a manually designed acceleration controller with a learned residual policy. As the acceleration controller warm starts policy for efficient training, the trained policy overcomes the limitation of the acceleration controller and improves the jumping stability. In addition, a low-level whole-body controller converts the body pose command from the stance controller to motor commands. After training in simulation, our framework can be deployed directly to the real robot, and perform versatile, continuous jumping motions, including omni-directional jumps at up to 50cm high, 60cm forward, and jump-turning at up to 90 degrees. Please visit our website for more results: https://sites.google.com/view/learning-to-jump.
On Designing a Learning Robot: Improving Morphology for Enhanced Task Performance and Learning
Mar 23, 2023As robots become more prevalent, optimizing their design for better performance and efficiency is becoming increasingly important. However, current robot design practices overlook the impact of perception and design choices on a robot's learning capabilities. To address this gap, we propose a comprehensive methodology that accounts for the interplay between the robot's perception, hardware characteristics, and task requirements. Our approach optimizes the robot's morphology holistically, leading to improved learning and task execution proficiency. To achieve this, we introduce a Morphology-AGnostIc Controller (MAGIC), which helps with the rapid assessment of different robot designs. The MAGIC policy is efficiently trained through a novel PRIvileged Single-stage learning via latent alignMent (PRISM) framework, which also encourages behaviors that are typical of robot onboard observation. Our simulation-based results demonstrate that morphologies optimized holistically improve the robot performance by 15-20% on various manipulation tasks, and require 25x less data to match human-expert made morphology performance. In summary, our work contributes to the growing trend of learning-based approaches in robotics and emphasizes the potential in designing robots that facilitate better learning.
Mnemosyne: Learning to Train Transformers with Transformers
Feb 02, 2023Training complex machine learning (ML) architectures requires a compute and time consuming process of selecting the right optimizer and tuning its hyper-parameters. A new paradigm of learning optimizers from data has emerged as a better alternative to hand-designed ML optimizers. We propose Mnemosyne optimizer, that uses Performers: implicit low-rank attention Transformers. It can learn to train entire neural network architectures including other Transformers without any task-specific optimizer tuning. We show that Mnemosyne: (a) generalizes better than popular LSTM optimizer, (b) in particular can successfully train Vision Transformers (ViTs) while meta--trained on standard MLPs and (c) can initialize optimizers for faster convergence in Robotics applications. We believe that these results open the possibility of using Transformers to build foundational optimization models that can address the challenges of regular Transformer training. We complement our results with an extensive theoretical analysis of the compact associative memory used by Mnemosyne.
Efficient Learning of Voltage Control Strategies via Model-based Deep Reinforcement Learning
Dec 06, 2022This article proposes a model-based deep reinforcement learning (DRL) method to design emergency control strategies for short-term voltage stability problems in power systems. Recent advances show promising results in model-free DRL-based methods for power systems, but model-free methods suffer from poor sample efficiency and training time, both critical for making state-of-the-art DRL algorithms practically applicable. DRL-agent learns an optimal policy via a trial-and-error method while interacting with the real-world environment. And it is desirable to minimize the direct interaction of the DRL agent with the real-world power grid due to its safety-critical nature. Additionally, state-of-the-art DRL-based policies are mostly trained using a physics-based grid simulator where dynamic simulation is computationally intensive, lowering the training efficiency. We propose a novel model-based-DRL framework where a deep neural network (DNN)-based dynamic surrogate model, instead of a real-world power-grid or physics-based simulation, is utilized with the policy learning framework, making the process faster and sample efficient. However, stabilizing model-based DRL is challenging because of the complex system dynamics of large-scale power systems. We solved these issues by incorporating imitation learning to have a warm start in policy learning, reward-shaping, and multi-step surrogate loss. Finally, we achieved 97.5% sample efficiency and 87.7% training efficiency for an application to the IEEE 300-bus test system.
Robotic Table Wiping via Reinforcement Learning and Whole-body Trajectory Optimization
Oct 19, 2022
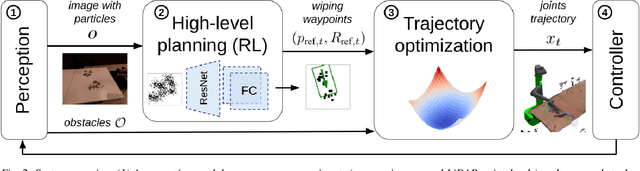

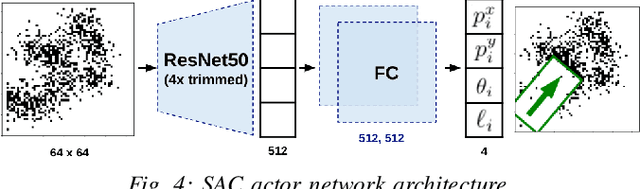
We propose a framework to enable multipurpose assistive mobile robots to autonomously wipe tables to clean spills and crumbs. This problem is challenging, as it requires planning wiping actions while reasoning over uncertain latent dynamics of crumbs and spills captured via high-dimensional visual observations. Simultaneously, we must guarantee constraints satisfaction to enable safe deployment in unstructured cluttered environments. To tackle this problem, we first propose a stochastic differential equation to model crumbs and spill dynamics and absorption with a robot wiper. Using this model, we train a vision-based policy for planning wiping actions in simulation using reinforcement learning (RL). To enable zero-shot sim-to-real deployment, we dovetail the RL policy with a whole-body trajectory optimization framework to compute base and arm joint trajectories that execute the desired wiping motions while guaranteeing constraints satisfaction. We extensively validate our approach in simulation and on hardware. Video: https://youtu.be/inORKP4F3EI
Learning Model Predictive Controllers with Real-Time Attention for Real-World Navigation
Sep 24, 2022
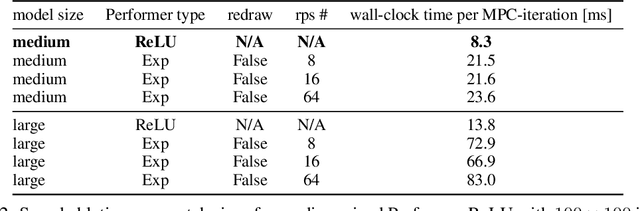


Despite decades of research, existing navigation systems still face real-world challenges when deployed in the wild, e.g., in cluttered home environments or in human-occupied public spaces. To address this, we present a new class of implicit control policies combining the benefits of imitation learning with the robust handling of system constraints from Model Predictive Control (MPC). Our approach, called Performer-MPC, uses a learned cost function parameterized by vision context embeddings provided by Performers -- a low-rank implicit-attention Transformer. We jointly train the cost function and construct the controller relying on it, effectively solving end-to-end the corresponding bi-level optimization problem. We show that the resulting policy improves standard MPC performance by leveraging a few expert demonstrations of the desired navigation behavior in different challenging real-world scenarios. Compared with a standard MPC policy, Performer-MPC achieves >40% better goal reached in cluttered environments and >65% better on social metrics when navigating around humans.
PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations
Jul 27, 2022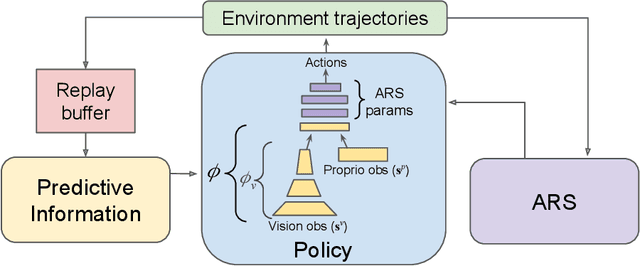

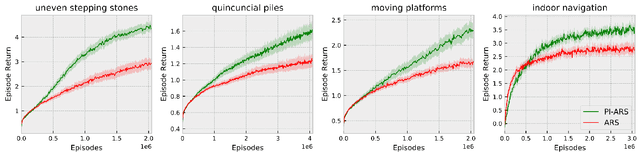

Evolution Strategy (ES) algorithms have shown promising results in training complex robotic control policies due to their massive parallelism capability, simple implementation, effective parameter-space exploration, and fast training time. However, a key limitation of ES is its scalability to large capacity models, including modern neural network architectures. In this work, we develop Predictive Information Augmented Random Search (PI-ARS) to mitigate this limitation by leveraging recent advancements in representation learning to reduce the parameter search space for ES. Namely, PI-ARS combines a gradient-based representation learning technique, Predictive Information (PI), with a gradient-free ES algorithm, Augmented Random Search (ARS), to train policies that can process complex robot sensory inputs and handle highly nonlinear robot dynamics. We evaluate PI-ARS on a set of challenging visual-locomotion tasks where a quadruped robot needs to walk on uneven stepping stones, quincuncial piles, and moving platforms, as well as to complete an indoor navigation task. Across all tasks, PI-ARS demonstrates significantly better learning efficiency and performance compared to the ARS baseline. We further validate our algorithm by demonstrating that the learned policies can successfully transfer to a real quadruped robot, for example, achieving a 100% success rate on the real-world stepping stone environment, dramatically improving prior results achieving 40% success.
Learning Semantics-Aware Locomotion Skills from Human Demonstration
Jun 27, 2022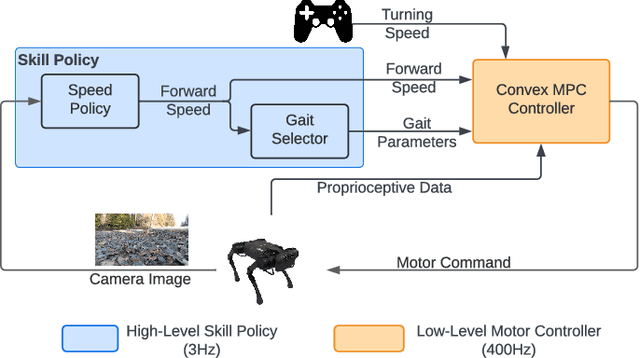
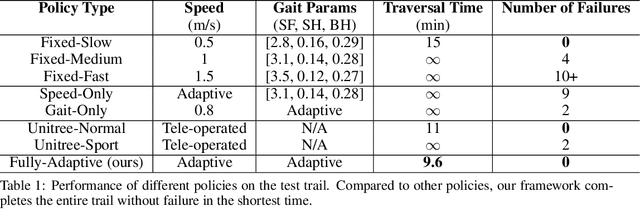
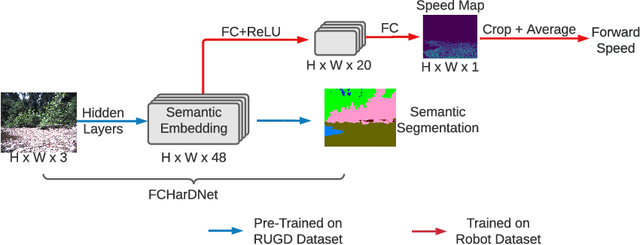
The semantics of the environment, such as the terrain type and property, reveals important information for legged robots to adjust their behaviors. In this work, we present a framework that learns semantics-aware locomotion skills from perception for quadrupedal robots, such that the robot can traverse through complex offroad terrains with appropriate speeds and gaits using perception information. Due to the lack of high-fidelity outdoor simulation, our framework needs to be trained directly in the real world, which brings unique challenges in data efficiency and safety. To ensure sample efficiency, we pre-train the perception model with an off-road driving dataset. To avoid the risks of real-world policy exploration, we leverage human demonstration to train a speed policy that selects a desired forward speed from camera image. For maximum traversability, we pair the speed policy with a gait selector, which selects a robust locomotion gait for each forward speed. Using only 40 minutes of human demonstration data, our framework learns to adjust the speed and gait of the robot based on perceived terrain semantics, and enables the robot to walk over 6km without failure at close-to-optimal speed.