 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Steerable Geometric Motion Policies for Robotic Dexterous Manipulation
May 20, 2026Robotic dexterous manipulation requires continuously reconciling objectives and constraints defined on heterogeneous geometric spaces: a robot controlled on a $\mathbb{R}^7$ configuration manifold may need to track end effector poses on $\mathrm{SE}(3)$ while satisfying obstacle avoidance margins in $\mathbb{R}$. We present Safe Pullback Bundle Dynamical Systems (SafePBDS), a geometrically consistent framework that computes optimal, certifiably safe configuration manifold accelerations from objectives and safety requirements on arbitrary task manifolds. SafePBDS builds on prior work that combines predefined task manifold dynamical systems to produce autonomous motion. Its first innovation is a pullback control barrier function construction, which converts task manifold safety conditions into linear constraints on configuration manifold accelerations. The second innovation is a task manifold action interface that allows a high-level policy to inject low dimensional residual motions; zero input recovers the autonomous behavior, while safety is preserved under arbitrary inputs. This lets high-level policies efficiently steer exploration while leaving precise motion to the autonomous behavior. We validate SafePBDS in simulation and on a 23-DOF Franka Panda-Allegro Hand platform. On dexterous grasping, SafePBDS achieves a $92.5\%$ success rate across 20 household objects and 120 trials. Using the action interface, the method can exclude any one of the four fingers during grasping via a one-dimensional action, achieving $94.4\%$ 3-finger grasp success across 3 objects and 36 trials. The efficient planning and safety guarantee of SafePBDS also enables the first model-based, fully actuated palm-down in-hand reorientation, exceeding $360^\circ$ of yaw rotation in both directions under varying object weight and wrist motion. Demo video and details: https://tml.stanford.edu/safe-pbds
Boundary Sampling to Learn Predictive Safety Filters via Pontryagin's Maximum Principle
Apr 14, 2026Safety filters provide a practical approach for enforcing safety constraints in autonomous systems. While learning-based tools scale to high-dimensional systems, their performance depends on informative data that includes states likely to lead to constraint violation, which can be difficult to efficiently sample in complex, high-dimensional systems. In this work, we characterize trajectories that barely avoid safety violations using the Pontryagin Maximum Principle. These boundary trajectories are used to guide data collection for learned Hamilton-Jacobi Reachability, concentrating learning efforts near safety-critical states to improve efficiency. The learned Control Barrier Value Function is then used directly for safety filtering. Simulations and experimental validation on a shared-control automotive racing application demonstrate PMP sampling improves learning efficiency, yielding faster convergence, reduced failure rates, and improved safe set reconstruction, with wall times around 3ms.
Vision-Conditioned Variational Bayesian Last Layer Dynamics Models
Jan 16, 2026Agile control of robotic systems often requires anticipating how the environment affects system behavior. For example, a driver must perceive the road ahead to anticipate available friction and plan actions accordingly. Achieving such proactive adaptation within autonomous frameworks remains a challenge, particularly under rapidly changing conditions. Traditional modeling approaches often struggle to capture abrupt variations in system behavior, while adaptive methods are inherently reactive and may adapt too late to ensure safety. We propose a vision-conditioned variational Bayesian last-layer dynamics model that leverages visual context to anticipate changes in the environment. The model first learns nominal vehicle dynamics and is then fine-tuned with feature-wise affine transformations of latent features, enabling context-aware dynamics prediction. The resulting model is integrated into an optimal controller for vehicle racing. We validate our method on a Lexus LC500 racing through water puddles. With vision-conditioning, the system completed all 12 attempted laps under varying conditions. In contrast, all baselines without visual context consistently lost control, demonstrating the importance of proactive dynamics adaptation in high-performance applications.
Rough Stochastic Pontryagin Maximum Principle and an Indirect Shooting Method
Feb 10, 2025We derive first-order Pontryagin optimality conditions for stochastic optimal control with deterministic controls for systems modeled by rough differential equations (RDE) driven by Gaussian rough paths. This Pontryagin Maximum Principle (PMP) applies to systems following stochastic differential equations (SDE) driven by Brownian motion, yet it does not rely on forward-backward SDEs and involves the same Hamiltonian as the deterministic PMP. The proof consists of first deriving various integrable error bounds for solutions to nonlinear and linear RDEs by leveraging recent results on Gaussian rough paths. The PMP then follows using standard techniques based on needle-like variations. As an application, we propose the first indirect shooting method for nonlinear stochastic optimal control and show that it converges 10x faster than a direct method on a stabilization task.
First, Learn What You Don't Know: Active Information Gathering for Driving at the Limits of Handling
Oct 31, 2024Combining data-driven models that adapt online and model predictive control (MPC) has enabled effective control of nonlinear systems. However, when deployed on unstable systems, online adaptation may not be fast enough to ensure reliable simultaneous learning and control. For example, controllers on a vehicle executing highly dynamic maneuvers may push the tires to their friction limits, destabilizing the vehicle and allowing modeling errors to quickly compound and cause a loss of control. In this work, we present a Bayesian meta-learning MPC framework. We propose an expressive vehicle dynamics model that leverages Bayesian last-layer meta-learning to enable rapid online adaptation. The model's uncertainty estimates are used to guide informative data collection and quickly improve the model prior to deployment. Experiments on a Toyota Supra show that (i) the framework enables reliable control in dynamic drifting maneuvers, (ii) online adaptation alone may not suffice for zero-shot control of a vehicle at the edge of stability, and (iii) active data collection helps achieve reliable performance.
Risk-Averse Model Predictive Control for Racing in Adverse Conditions
Oct 22, 2024



Model predictive control (MPC) algorithms can be sensitive to model mismatch when used in challenging nonlinear control tasks. In particular, the performance of MPC for vehicle control at the limits of handling suffers when the underlying model overestimates the vehicle's capabilities. In this work, we propose a risk-averse MPC framework that explicitly accounts for uncertainty over friction limits and tire parameters. Our approach leverages a sample-based approximation of an optimal control problem with a conditional value at risk (CVaR) constraint. This sample-based formulation enables planning with a set of expressive vehicle dynamics models using different tire parameters. Moreover, this formulation enables efficient numerical resolution via sequential quadratic programming and GPU parallelization. Experiments on a Lexus LC 500 show that risk-averse MPC unlocks reliable performance, while a deterministic baseline that plans using a single dynamics model may lose control of the vehicle in adverse road conditions.
Risk-Averse Trajectory Optimization via Sample Average Approximation
Jul 06, 2023Trajectory optimization under uncertainty underpins a wide range of applications in robotics. However, existing methods are limited in terms of reasoning about sources of epistemic and aleatoric uncertainty, space and time correlations, nonlinear dynamics, and non-convex constraints. In this work, we first introduce a continuous-time planning formulation with an average-value-at-risk constraint over the entire planning horizon. Then, we propose a sample-based approximation that unlocks an efficient, general-purpose, and time-consistent algorithm for risk-averse trajectory optimization. We prove that the method is asymptotically optimal and derive finite-sample error bounds. Simulations demonstrate the high speed and reliability of the approach on problems with stochasticity in nonlinear dynamics, obstacle fields, interactions, and terrain parameters.
Exact Characterization of the Convex Hulls of Reachable Sets
Mar 30, 2023We study the convex hulls of reachable sets of nonlinear systems with bounded disturbances. Reachable sets play a critical role in control, but remain notoriously challenging to compute, and existing over-approximation tools tend to be conservative or computationally expensive. In this work, we exactly characterize the convex hulls of reachable sets as the convex hulls of solutions of an ordinary differential equation from all possible initial values of the disturbances. This finite-dimensional characterization unlocks a tight estimation algorithm to over-approximate reachable sets that is significantly faster and more accurate than existing methods. We present applications to neural feedback loop analysis and robust model predictive control.
A System-Level View on Out-of-Distribution Data in Robotics
Dec 28, 2022When testing conditions differ from those represented in training data, so-called out-of-distribution (OOD) inputs can mar the reliability of black-box learned components in the modern robot autonomy stack. Therefore, coping with OOD data is an important challenge on the path towards trustworthy learning-enabled open-world autonomy. In this paper, we aim to demystify the topic of OOD data and its associated challenges in the context of data-driven robotic systems, drawing connections to emerging paradigms in the ML community that study the effect of OOD data on learned models in isolation. We argue that as roboticists, we should reason about the overall system-level competence of a robot as it performs tasks in OOD conditions. We highlight key research questions around this system-level view of OOD problems to guide future research toward safe and reliable learning-enabled autonomy.
Robotic Table Wiping via Reinforcement Learning and Whole-body Trajectory Optimization
Oct 19, 2022
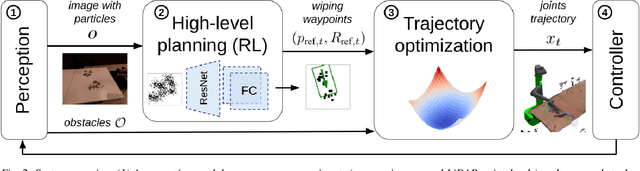

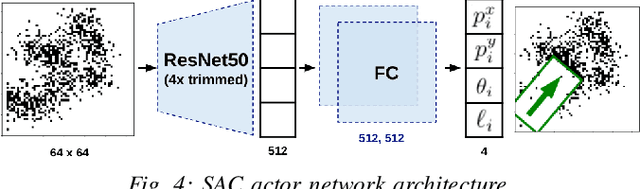
We propose a framework to enable multipurpose assistive mobile robots to autonomously wipe tables to clean spills and crumbs. This problem is challenging, as it requires planning wiping actions while reasoning over uncertain latent dynamics of crumbs and spills captured via high-dimensional visual observations. Simultaneously, we must guarantee constraints satisfaction to enable safe deployment in unstructured cluttered environments. To tackle this problem, we first propose a stochastic differential equation to model crumbs and spill dynamics and absorption with a robot wiper. Using this model, we train a vision-based policy for planning wiping actions in simulation using reinforcement learning (RL). To enable zero-shot sim-to-real deployment, we dovetail the RL policy with a whole-body trajectory optimization framework to compute base and arm joint trajectories that execute the desired wiping motions while guaranteeing constraints satisfaction. We extensively validate our approach in simulation and on hardware. Video: https://youtu.be/inORKP4F3EI