 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Secondary Risks of Large Language Models
Jun 14, 2025



Ensuring the safety and alignment of Large Language Models is a significant challenge with their growing integration into critical applications and societal functions. While prior research has primarily focused on jailbreak attacks, less attention has been given to non-adversarial failures that subtly emerge during benign interactions. We introduce secondary risks a novel class of failure modes marked by harmful or misleading behaviors during benign prompts. Unlike adversarial attacks, these risks stem from imperfect generalization and often evade standard safety mechanisms. To enable systematic evaluation, we introduce two risk primitives verbose response and speculative advice that capture the core failure patterns. Building on these definitions, we propose SecLens, a black-box, multi-objective search framework that efficiently elicits secondary risk behaviors by optimizing task relevance, risk activation, and linguistic plausibility. To support reproducible evaluation, we release SecRiskBench, a benchmark dataset of 650 prompts covering eight diverse real-world risk categories. Experimental results from extensive evaluations on 16 popular models demonstrate that secondary risks are widespread, transferable across models, and modality independent, emphasizing the urgent need for enhanced safety mechanisms to address benign yet harmful LLM behaviors in real-world deployments.
OpenGT: A Comprehensive Benchmark For Graph Transformers
Jun 05, 2025Graph Transformers (GTs) have recently demonstrated remarkable performance across diverse domains. By leveraging attention mechanisms, GTs are capable of modeling long-range dependencies and complex structural relationships beyond local neighborhoods. However, their applicable scenarios are still underexplored, this highlights the need to identify when and why they excel. Furthermore, unlike GNNs, which predominantly rely on message-passing mechanisms, GTs exhibit a diverse design space in areas such as positional encoding, attention mechanisms, and graph-specific adaptations. Yet, it remains unclear which of these design choices are truly effective and under what conditions. As a result, the community currently lacks a comprehensive benchmark and library to promote a deeper understanding and further development of GTs. To address this gap, this paper introduces OpenGT, a comprehensive benchmark for Graph Transformers. OpenGT enables fair comparisons and multidimensional analysis by establishing standardized experimental settings and incorporating a broad selection of state-of-the-art GNNs and GTs. Our benchmark evaluates GTs from multiple perspectives, encompassing diverse tasks and datasets with varying properties. Through extensive experiments, our benchmark has uncovered several critical insights, including the difficulty of transferring models across task levels, the limitations of local attention, the efficiency trade-offs in several models, the application scenarios of specific positional encodings, and the preprocessing overhead of some positional encodings. We aspire for this work to establish a foundation for future graph transformer research emphasizing fairness, reproducibility, and generalizability. We have developed an easy-to-use library OpenGT for training and evaluating existing GTs. The benchmark code is available at https://github.com/eaglelab-zju/OpenGT.
Sounding that Object: Interactive Object-Aware Image to Audio Generation
Jun 04, 2025



Generating accurate sounds for complex audio-visual scenes is challenging, especially in the presence of multiple objects and sound sources. In this paper, we propose an {\em interactive object-aware audio generation} model that grounds sound generation in user-selected visual objects within images. Our method integrates object-centric learning into a conditional latent diffusion model, which learns to associate image regions with their corresponding sounds through multi-modal attention. At test time, our model employs image segmentation to allow users to interactively generate sounds at the {\em object} level. We theoretically validate that our attention mechanism functionally approximates test-time segmentation masks, ensuring the generated audio aligns with selected objects. Quantitative and qualitative evaluations show that our model outperforms baselines, achieving better alignment between objects and their associated sounds. Project page: https://tinglok.netlify.app/files/avobject/
Bridging the Gap: Self-Optimized Fine-Tuning for LLM-based Recommender Systems
May 27, 2025Recent years have witnessed extensive exploration of Large Language Models (LLMs) on the field of Recommender Systems (RS). There are currently two commonly used strategies to enable LLMs to have recommendation capabilities: 1) The "Guidance-Only" strategy uses in-context learning to exploit and amplify the inherent semantic understanding and item recommendation capabilities of LLMs; 2) The "Tuning-Only" strategy uses supervised fine-tuning (SFT) to fine-tune LLMs with the aim of fitting them to real recommendation data. However, neither of these strategies can effectively bridge the gap between the knowledge space of LLMs and recommendation, and their performance do not meet our expectations. To better enable LLMs to learn recommendation knowledge, we combine the advantages of the above two strategies and proposed a novel "Guidance+Tuning" method called Self-Optimized Fine-Tuning (SOFT), which adopts the idea of curriculum learning. It first employs self-distillation to construct an auxiliary easy-to-learn but meaningful dataset from a fine-tuned LLM. Then it further utilizes a self-adaptive curriculum scheduler to enable LLMs to gradually learn from simpler data (self-distilled data) to more challenging data (real RS data). Extensive experiments demonstrate that SOFT significantly enhances the recommendation accuracy (37.59\% on average) of LLM-based methods. The code is available via https://anonymous.4open.science/r/Self-Optimized-Fine-Tuning-264E
Field Matters: A lightweight LLM-enhanced Method for CTR Prediction
May 20, 2025



Click-through rate (CTR) prediction is a fundamental task in modern recommender systems. In recent years, the integration of large language models (LLMs) has been shown to effectively enhance the performance of traditional CTR methods. However, existing LLM-enhanced methods often require extensive processing of detailed textual descriptions for large-scale instances or user/item entities, leading to substantial computational overhead. To address this challenge, this work introduces LLaCTR, a novel and lightweight LLM-enhanced CTR method that employs a field-level enhancement paradigm. Specifically, LLaCTR first utilizes LLMs to distill crucial and lightweight semantic knowledge from small-scale feature fields through self-supervised field-feature fine-tuning. Subsequently, it leverages this field-level semantic knowledge to enhance both feature representation and feature interactions. In our experiments, we integrate LLaCTR with six representative CTR models across four datasets, demonstrating its superior performance in terms of both effectiveness and efficiency compared to existing LLM-enhanced methods. Our code is available at https://anonymous.4open.science/r/LLaCTR-EC46.
MCCD: Multi-Agent Collaboration-based Compositional Diffusion for Complex Text-to-Image Generation
May 05, 2025Diffusion models have shown excellent performance in text-to-image generation. Nevertheless, existing methods often suffer from performance bottlenecks when handling complex prompts that involve multiple objects, characteristics, and relations. Therefore, we propose a Multi-agent Collaboration-based Compositional Diffusion (MCCD) for text-to-image generation for complex scenes. Specifically, we design a multi-agent collaboration-based scene parsing module that generates an agent system comprising multiple agents with distinct tasks, utilizing MLLMs to extract various scene elements effectively. In addition, Hierarchical Compositional diffusion utilizes a Gaussian mask and filtering to refine bounding box regions and enhance objects through region enhancement, resulting in the accurate and high-fidelity generation of complex scenes. Comprehensive experiments demonstrate that our MCCD significantly improves the performance of the baseline models in a training-free manner, providing a substantial advantage in complex scene generation.
MSL: Not All Tokens Are What You Need for Tuning LLM as a Recommender
Apr 05, 2025Large language models (LLMs), known for their comprehension capabilities and extensive knowledge, have been increasingly applied to recommendation systems (RS). Given the fundamental gap between the mechanism of LLMs and the requirement of RS, researchers have focused on fine-tuning LLMs with recommendation-specific data to enhance their performance. Language Modeling Loss (LML), originally designed for language generation tasks, is commonly adopted. However, we identify two critical limitations of LML: 1) it exhibits significant divergence from the recommendation objective; 2) it erroneously treats all fictitious item descriptions as negative samples, introducing misleading training signals. To address these limitations, we propose a novel Masked Softmax Loss (MSL) tailored for fine-tuning LLMs on recommendation. MSL improves LML by identifying and masking invalid tokens that could lead to fictitious item descriptions during loss computation. This strategy can effectively avoid the interference from erroneous negative signals and ensure well alignment with the recommendation objective supported by theoretical guarantees. During implementation, we identify a potential challenge related to gradient vanishing of MSL. To overcome this, we further introduce the temperature coefficient and propose an Adaptive Temperature Strategy (ATS) that adaptively adjusts the temperature without requiring extensive hyperparameter tuning. Extensive experiments conducted on four public datasets further validate the effectiveness of MSL, achieving an average improvement of 42.24% in NDCG@10. The code is available at https://github.com/WANGBohaO-jpg/MSL.
ShortV: Efficient Multimodal Large Language Models by Freezing Visual Tokens in Ineffective Layers
Apr 01, 2025Multimodal Large Language Models (MLLMs) suffer from high computational costs due to their massive size and the large number of visual tokens. In this paper, we investigate layer-wise redundancy in MLLMs by introducing a novel metric, Layer Contribution (LC), which quantifies the impact of a layer's transformations on visual and text tokens, respectively. The calculation of LC involves measuring the divergence in model output that results from removing the layer's transformations on the specified tokens. Our pilot experiment reveals that many layers of MLLMs exhibit minimal contribution during the processing of visual tokens. Motivated by this observation, we propose ShortV, a training-free method that leverages LC to identify ineffective layers, and freezes visual token updates in these layers. Experiments show that ShortV can freeze visual token in approximately 60\% of the MLLM layers, thereby dramatically reducing computational costs related to updating visual tokens. For example, it achieves a 50\% reduction in FLOPs on LLaVA-NeXT-13B while maintaining superior performance. The code will be publicly available at https://github.com/icip-cas/ShortV
Recent Advances on Generalizable Diffusion-generated Image Detection
Feb 27, 2025The rise of diffusion models has significantly improved the fidelity and diversity of generated images. With numerous benefits, these advancements also introduce new risks. Diffusion models can be exploited to create high-quality Deepfake images, which poses challenges for image authenticity verification. In recent years, research on generalizable diffusion-generated image detection has grown rapidly. However, a comprehensive review of this topic is still lacking. To bridge this gap, we present a systematic survey of recent advances and classify them into two main categories: (1) data-driven detection and (2) feature-driven detection. Existing detection methods are further classified into six fine-grained categories based on their underlying principles. Finally, we identify several open challenges and envision some future directions, with the hope of inspiring more research work on this important topic. Reviewed works in this survey can be found at https://github.com/zju-pi/Awesome-Diffusion-generated-Image-Detection.
FlowAgent: Achieving Compliance and Flexibility for Workflow Agents
Feb 20, 2025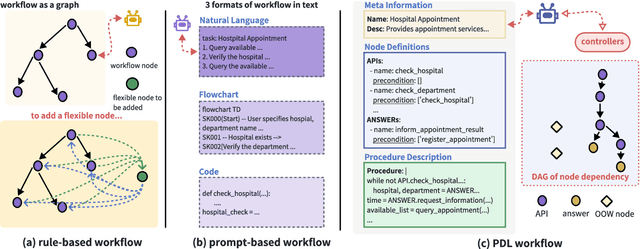

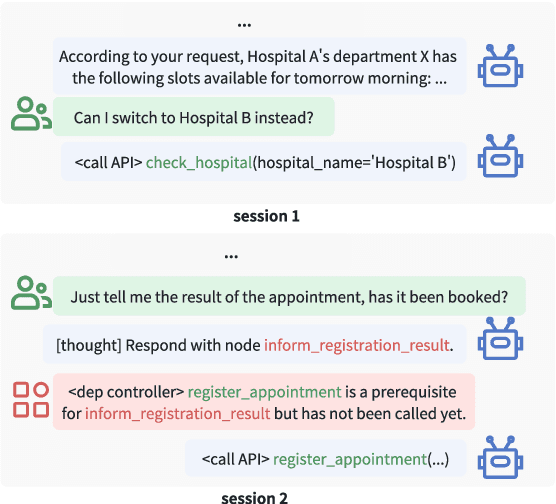
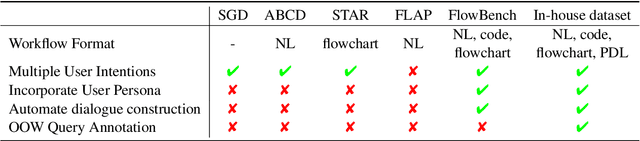
The integration of workflows with large language models (LLMs) enables LLM-based agents to execute predefined procedures, enhancing automation in real-world applications. Traditional rule-based methods tend to limit the inherent flexibility of LLMs, as their predefined execution paths restrict the models' action space, particularly when the unexpected, out-of-workflow (OOW) queries are encountered. Conversely, prompt-based methods allow LLMs to fully control the flow, which can lead to diminished enforcement of procedural compliance. To address these challenges, we introduce FlowAgent, a novel agent framework designed to maintain both compliance and flexibility. We propose the Procedure Description Language (PDL), which combines the adaptability of natural language with the precision of code to formulate workflows. Building on PDL, we develop a comprehensive framework that empowers LLMs to manage OOW queries effectively, while keeping the execution path under the supervision of a set of controllers. Additionally, we present a new evaluation methodology to rigorously assess an LLM agent's ability to handle OOW scenarios, going beyond routine flow compliance tested in existing benchmarks. Experiments on three datasets demonstrate that FlowAgent not only adheres to workflows but also effectively manages OOW queries, highlighting its dual strengths in compliance and flexibility. The code is available at https://github.com/Lightblues/FlowAgent.