 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPO: Consistency-Aware Policy Optimization
Aug 06, 2025Reinforcement learning has significantly enhanced the reasoning capabilities of Large Language Models (LLMs) in complex problem-solving tasks. Recently, the introduction of DeepSeek R1 has inspired a surge of interest in leveraging rule-based rewards as a low-cost alternative for computing advantage functions and guiding policy optimization. However, a common challenge observed across many replication and extension efforts is that when multiple sampled responses under a single prompt converge to identical outcomes, whether correct or incorrect, the group-based advantage degenerates to zero. This leads to vanishing gradients and renders the corresponding samples ineffective for learning, ultimately limiting training efficiency and downstream performance. To address this issue, we propose a consistency-aware policy optimization framework that introduces a structured global reward based on outcome consistency, the global loss based on it ensures that, even when model outputs show high intra-group consistency, the training process still receives meaningful learning signals, which encourages the generation of correct and self-consistent reasoning paths from a global perspective. Furthermore, we incorporate an entropy-based soft blending mechanism that adaptively balances local advantage estimation with global optimization, enabling dynamic transitions between exploration and convergence throughout training. Our method introduces several key innovations in both reward design and optimization strategy. We validate its effectiveness through substantial performance gains on multiple mathematical reasoning benchmarks, highlighting the proposed framework's robustness and general applicability. Code of this work has been released at https://github.com/hijih/copo-code.git.
VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
May 06, 2025With the growing requirement for natural human-computer interaction, speech-based systems receive increasing attention as speech is one of the most common forms of daily communication. However, the existing speech models still experience high latency when generating the first audio token during streaming, which poses a significant bottleneck for deployment. To address this issue, we propose VITA-Audio, an end-to-end large speech model with fast audio-text token generation. Specifically, we introduce a lightweight Multiple Cross-modal Token Prediction (MCTP) module that efficiently generates multiple audio tokens within a single model forward pass, which not only accelerates the inference but also significantly reduces the latency for generating the first audio in streaming scenarios. In addition, a four-stage progressive training strategy is explored to achieve model acceleration with minimal loss of speech quality. To our knowledge, VITA-Audio is the first multi-modal large language model capable of generating audio output during the first forward pass, enabling real-time conversational capabilities with minimal latency. VITA-Audio is fully reproducible and is trained on open-source data only. Experimental results demonstrate that our model achieves an inference speedup of 3~5x at the 7B parameter scale, but also significantly outperforms open-source models of similar model size on multiple benchmarks for automatic speech recognition (ASR), text-to-speech (TTS), and spoken question answering (SQA) tasks.
Remote Photoplethysmography in Real-World and Extreme Lighting Scenarios
Mar 14, 2025Physiological activities can be manifested by the sensitive changes in facial imaging. While they are barely observable to our eyes, computer vision manners can, and the derived remote photoplethysmography (rPPG) has shown considerable promise. However, existing studies mainly rely on spatial skin recognition and temporal rhythmic interactions, so they focus on identifying explicit features under ideal light conditions, but perform poorly in-the-wild with intricate obstacles and extreme illumination exposure. In this paper, we propose an end-to-end video transformer model for rPPG. It strives to eliminate complex and unknown external time-varying interferences, whether they are sufficient to occupy subtle biosignal amplitudes or exist as periodic perturbations that hinder network training. In the specific implementation, we utilize global interference sharing, subject background reference, and self-supervised disentanglement to eliminate interference, and further guide learning based on spatiotemporal filtering, reconstruction guidance, and frequency domain and biological prior constraints to achieve effective rPPG. To the best of our knowledge, this is the first robust rPPG model for real outdoor scenarios based on natural face videos, and is lightweight to deploy. Extensive experiments show the competitiveness and performance of our model in rPPG prediction across datasets and scenes.
FlowAgent: Achieving Compliance and Flexibility for Workflow Agents
Feb 20, 2025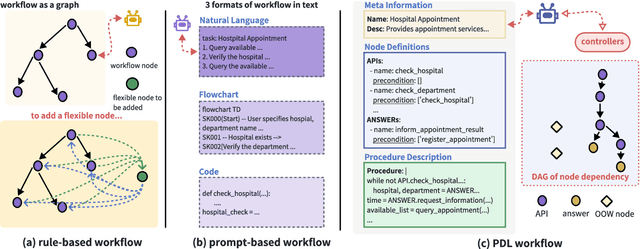

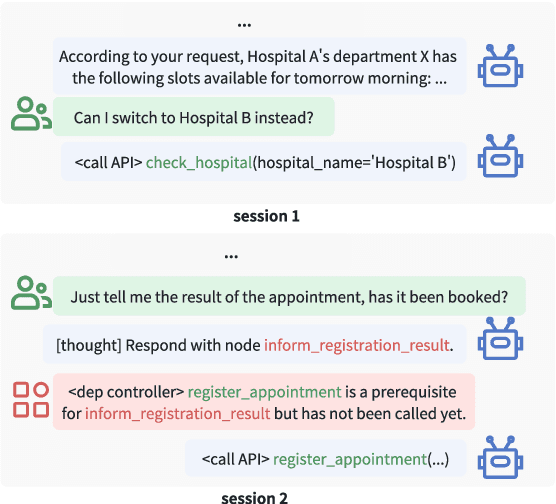
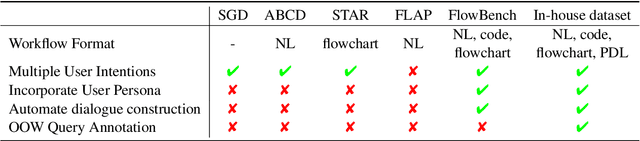
The integration of workflows with large language models (LLMs) enables LLM-based agents to execute predefined procedures, enhancing automation in real-world applications. Traditional rule-based methods tend to limit the inherent flexibility of LLMs, as their predefined execution paths restrict the models' action space, particularly when the unexpected, out-of-workflow (OOW) queries are encountered. Conversely, prompt-based methods allow LLMs to fully control the flow, which can lead to diminished enforcement of procedural compliance. To address these challenges, we introduce FlowAgent, a novel agent framework designed to maintain both compliance and flexibility. We propose the Procedure Description Language (PDL), which combines the adaptability of natural language with the precision of code to formulate workflows. Building on PDL, we develop a comprehensive framework that empowers LLMs to manage OOW queries effectively, while keeping the execution path under the supervision of a set of controllers. Additionally, we present a new evaluation methodology to rigorously assess an LLM agent's ability to handle OOW scenarios, going beyond routine flow compliance tested in existing benchmarks. Experiments on three datasets demonstrate that FlowAgent not only adheres to workflows but also effectively manages OOW queries, highlighting its dual strengths in compliance and flexibility. The code is available at https://github.com/Lightblues/FlowAgent.
LUCY: Linguistic Understanding and Control Yielding Early Stage of Her
Jan 27, 2025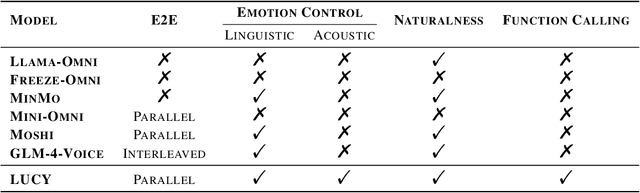
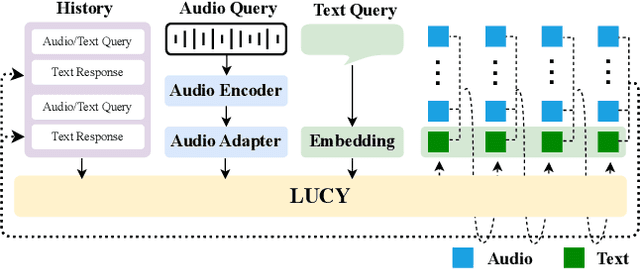
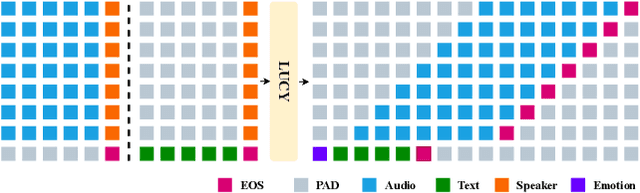
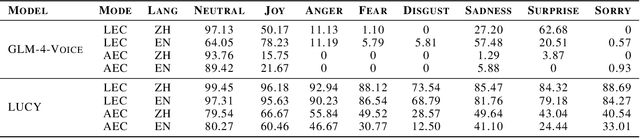
The film Her features Samantha, a sophisticated AI audio agent who is capable of understanding both linguistic and paralinguistic information in human speech and delivering real-time responses that are natural, informative and sensitive to emotional subtleties. Moving one step toward more sophisticated audio agent from recent advancement in end-to-end (E2E) speech systems, we propose LUCY, a E2E speech model that (1) senses and responds to user's emotion, (2) deliver responses in a succinct and natural style, and (3) use external tool to answer real-time inquiries. Experiment results show that LUCY is better at emotion control than peer models, generating emotional responses based on linguistic emotional instructions and responding to paralinguistic emotional cues. Lucy is also able to generate responses in a more natural style, as judged by external language models, without sacrificing much performance on general question answering. Finally, LUCY can leverage function calls to answer questions that are out of its knowledge scope.
Leveraging Open Knowledge for Advancing Task Expertise in Large Language Models
Aug 28, 2024



The cultivation of expertise for large language models (LLMs) to solve tasks of specific areas often requires special-purpose tuning with calibrated behaviors on the expected stable outputs. To avoid huge cost brought by manual preparation of instruction datasets and training resources up to hundreds of hours, the exploitation of open knowledge including a wealth of low rank adaptation (LoRA) models and instruction datasets serves as a good starting point. However, existing methods on model and data selection focus on the performance of general-purpose capabilities while neglecting the knowledge gap exposed in domain-specific deployment. In the present study, we propose to bridge such gap by introducing few human-annotated samples (i.e., K-shot) for advancing task expertise of LLMs with open knowledge. Specifically, we develop an efficient and scalable pipeline to cost-efficiently produce task experts where K-shot data intervene in selecting the most promising expert candidates and the task-relevant instructions. A mixture-of-expert (MoE) system is built to make the best use of individual-yet-complementary knowledge between multiple experts. We unveil the two keys to the success of a MoE system, 1) the abidance by K-shot, and 2) the insistence on diversity. For the former, we ensure that models that truly possess problem-solving abilities on K-shot are selected rather than those blind guessers. Besides, during data selection, instructions that share task-relevant contexts with K-shot are prioritized. For the latter, we highlight the diversity of constituting experts and that of the fine-tuning instructions throughout the model and data selection process. Extensive experimental results confirm the superiority of our approach over existing methods on utilization of open knowledge across various tasks. Codes and models will be released later.
Unleashing the Power of Data Tsunami: A Comprehensive Survey on Data Assessment and Selection for Instruction Tuning of Language Models
Aug 07, 2024



Instruction tuning plays a critical role in aligning large language models (LLMs) with human preference. Despite the vast amount of open instruction datasets, naively training a LLM on all existing instructions may not be optimal and practical. To pinpoint the most beneficial datapoints, data assessment and selection methods have been proposed in the fields of natural language processing (NLP) and deep learning. However, under the context of instruction tuning, there still exists a gap in knowledge on what kind of data evaluation metrics can be employed and how they can be integrated into the selection mechanism. To bridge this gap, we present a comprehensive review on existing literature of data assessment and selection especially for instruction tuning of LLMs. We systematically categorize all applicable methods into quality-based, diversity-based, and importance-based ones where a unified, fine-grained taxonomy is structured. For each category, representative methods are elaborated to describe the landscape of relevant research. In addition, comparison between latest methods is conducted on their officially reported results to provide in-depth discussions on their limitations. Finally, we summarize the open challenges and propose the promosing avenues for future studies. All related contents are available at https://github.com/yuleiqin/fantastic-data-engineering.
CLAQ: Pushing the Limits of Low-Bit Post-Training Quantization for LLMs
May 27, 2024Parameter quantization for Large Language Models (LLMs) has attracted increasing attentions recently in reducing memory costs and improving computational efficiency. Early approaches have been widely adopted. However, the existing methods suffer from poor performance in low-bit (such as 2 to 3 bits) scenarios. In this paper, we present a novel and effective Column-Level Adaptive weight Quantization (CLAQ) framework by introducing three different types of adaptive strategies for LLM quantization. Firstly, a K-Means clustering based algorithm is proposed that allows dynamic generation of quantization centroids for each column of a parameter matrix. Secondly, we design an outlier-guided adaptive precision search strategy which can dynamically assign varying bit-widths to different columns. Finally, a dynamic outlier reservation scheme is developed to retain some parameters in their original float point precision, in trade off of boosted model performance. Experiments on various mainstream open source LLMs including LLaMA-1, LLaMA-2 and Yi demonstrate that our methods achieve the state-of-the-art results across different bit settings, especially in extremely low-bit scenarios. Code will be released soon.
One-Shot Sensitivity-Aware Mixed Sparsity Pruning for Large Language Models
Oct 14, 2023



Various Large Language Models(LLMs) from the Generative Pretrained Transformer~(GPT) family have achieved outstanding performances in a wide range of text generation tasks. However, the enormous model sizes have hindered their practical use in real-world applications due to high inference latency. Therefore, improving the efficiencies of LLMs through quantization, pruning, and other means has been a key issue in LLM studies. In this work, we propose a method based on Hessian sensitivity-aware mixed sparsity pruning to prune LLMs to at least 50\% sparsity without the need of any retraining. It allocates sparsity adaptively based on sensitivity, allowing us to reduce pruning-induced error while maintaining the overall sparsity level. The advantages of the proposed method exhibit even more when the sparsity is extremely high. Furthermore, our method is compatible with quantization, enabling further compression of LLMs.
A Novel Convolutional Neural Network Architecture with a Continuous Symmetry
Aug 09, 2023



This paper introduces a new Convolutional Neural Network (ConvNet) architecture inspired by a class of partial differential equations (PDEs) called quasi-linear hyperbolic systems. With comparable performance on the image classification task, it allows for the modification of the weights via a continuous group of symmetry. This is a significant shift from traditional models where the architecture and weights are essentially fixed. We wish to promote the (internal) symmetry as a new desirable property for a neural network, and to draw attention to the PDE perspective in analyzing and interpreting ConvNets in the broader Deep Learning community.