 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaAnimator: Personalized Motion Transfer from Unconstrained Videos
Aug 27, 2025Recent advances in motion generation show remarkable progress. However, several limitations remain: (1) Existing pose-guided character motion transfer methods merely replicate motion without learning its style characteristics, resulting in inexpressive characters. (2) Motion style transfer methods rely heavily on motion capture data, which is difficult to obtain. (3) Generated motions sometimes violate physical laws. To address these challenges, this paper pioneers a new task: Video-to-Video Motion Personalization. We propose a novel framework, PersonaAnimator, which learns personalized motion patterns directly from unconstrained videos. This enables personalized motion transfer. To support this task, we introduce PersonaVid, the first video-based personalized motion dataset. It contains 20 motion content categories and 120 motion style categories. We further propose a Physics-aware Motion Style Regularization mechanism to enforce physical plausibility in the generated motions. Extensive experiments show that PersonaAnimator outperforms state-of-the-art motion transfer methods and sets a new benchmark for the Video-to-Video Motion Personalization task.
MCCD: Multi-Agent Collaboration-based Compositional Diffusion for Complex Text-to-Image Generation
May 05, 2025Diffusion models have shown excellent performance in text-to-image generation. Nevertheless, existing methods often suffer from performance bottlenecks when handling complex prompts that involve multiple objects, characteristics, and relations. Therefore, we propose a Multi-agent Collaboration-based Compositional Diffusion (MCCD) for text-to-image generation for complex scenes. Specifically, we design a multi-agent collaboration-based scene parsing module that generates an agent system comprising multiple agents with distinct tasks, utilizing MLLMs to extract various scene elements effectively. In addition, Hierarchical Compositional diffusion utilizes a Gaussian mask and filtering to refine bounding box regions and enhance objects through region enhancement, resulting in the accurate and high-fidelity generation of complex scenes. Comprehensive experiments demonstrate that our MCCD significantly improves the performance of the baseline models in a training-free manner, providing a substantial advantage in complex scene generation.
VLM-based Prompts as the Optimal Assistant for Unpaired Histopathology Virtual Staining
Apr 22, 2025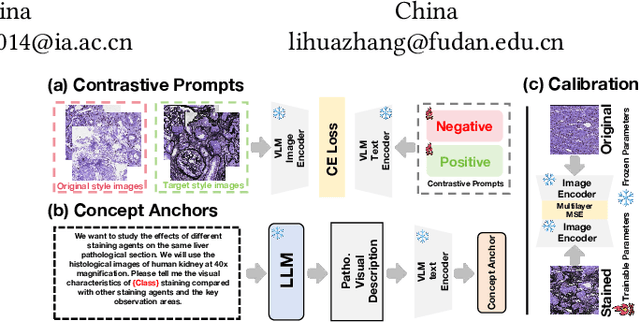



In histopathology, tissue sections are typically stained using common H&E staining or special stains (MAS, PAS, PASM, etc.) to clearly visualize specific tissue structures. The rapid advancement of deep learning offers an effective solution for generating virtually stained images, significantly reducing the time and labor costs associated with traditional histochemical staining. However, a new challenge arises in separating the fundamental visual characteristics of tissue sections from the visual differences induced by staining agents. Additionally, virtual staining often overlooks essential pathological knowledge and the physical properties of staining, resulting in only style-level transfer. To address these issues, we introduce, for the first time in virtual staining tasks, a pathological vision-language large model (VLM) as an auxiliary tool. We integrate contrastive learnable prompts, foundational concept anchors for tissue sections, and staining-specific concept anchors to leverage the extensive knowledge of the pathological VLM. This approach is designed to describe, frame, and enhance the direction of virtual staining. Furthermore, we have developed a data augmentation method based on the constraints of the VLM. This method utilizes the VLM's powerful image interpretation capabilities to further integrate image style and structural information, proving beneficial in high-precision pathological diagnostics. Extensive evaluations on publicly available multi-domain unpaired staining datasets demonstrate that our method can generate highly realistic images and enhance the accuracy of downstream tasks, such as glomerular detection and segmentation. Our code is available at: https://github.com/CZZZZZZZZZZZZZZZZZ/VPGAN-HARBOR
Toward Robust Incomplete Multimodal Sentiment Analysis via Hierarchical Representation Learning
Nov 05, 2024



Multimodal Sentiment Analysis (MSA) is an important research area that aims to understand and recognize human sentiment through multiple modalities. The complementary information provided by multimodal fusion promotes better sentiment analysis compared to utilizing only a single modality. Nevertheless, in real-world applications, many unavoidable factors may lead to situations of uncertain modality missing, thus hindering the effectiveness of multimodal modeling and degrading the model's performance. To this end, we propose a Hierarchical Representation Learning Framework (HRLF) for the MSA task under uncertain missing modalities. Specifically, we propose a fine-grained representation factorization module that sufficiently extracts valuable sentiment information by factorizing modality into sentiment-relevant and modality-specific representations through crossmodal translation and sentiment semantic reconstruction. Moreover, a hierarchical mutual information maximization mechanism is introduced to incrementally maximize the mutual information between multi-scale representations to align and reconstruct the high-level semantics in the representations. Ultimately, we propose a hierarchical adversarial learning mechanism that further aligns and adapts the latent distribution of sentiment-relevant representations to produce robust joint multimodal representations. Comprehensive experiments on three datasets demonstrate that HRLF significantly improves MSA performance under uncertain modality missing cases.
Faster Diffusion Action Segmentation
Aug 04, 2024



Temporal Action Segmentation (TAS) is an essential task in video analysis, aiming to segment and classify continuous frames into distinct action segments. However, the ambiguous boundaries between actions pose a significant challenge for high-precision segmentation. Recent advances in diffusion models have demonstrated substantial success in TAS tasks due to their stable training process and high-quality generation capabilities. However, the heavy sampling steps required by diffusion models pose a substantial computational burden, limiting their practicality in real-time applications. Additionally, most related works utilize Transformer-based encoder architectures. Although these architectures excel at capturing long-range dependencies, they incur high computational costs and face feature-smoothing issues when processing long video sequences. To address these challenges, we propose EffiDiffAct, an efficient and high-performance TAS algorithm. Specifically, we develop a lightweight temporal feature encoder that reduces computational overhead and mitigates the rank collapse phenomenon associated with traditional self-attention mechanisms. Furthermore, we introduce an adaptive skip strategy that allows for dynamic adjustment of timestep lengths based on computed similarity metrics during inference, thereby further enhancing computational efficiency. Comprehensive experiments on the 50Salads, Breakfast, and GTEA datasets demonstrated the effectiveness of the proposed algorithm.
SMCD: High Realism Motion Style Transfer via Mamba-based Diffusion
May 05, 2024



Motion style transfer is a significant research direction in multimedia applications. It enables the rapid switching of different styles of the same motion for virtual digital humans, thus vastly increasing the diversity and realism of movements. It is widely applied in multimedia scenarios such as movies, games, and the Metaverse. However, most of the current work in this field adopts the GAN, which may lead to instability and convergence issues, making the final generated motion sequence somewhat chaotic and unable to reflect a highly realistic and natural style. To address these problems, we consider style motion as a condition and propose the Style Motion Conditioned Diffusion (SMCD) framework for the first time, which can more comprehensively learn the style features of motion. Moreover, we apply Mamba model for the first time in the motion style transfer field, introducing the Motion Style Mamba (MSM) module to handle longer motion sequences. Thirdly, aiming at the SMCD framework, we propose Diffusion-based Content Consistency Loss and Content Consistency Loss to assist the overall framework's training. Finally, we conduct extensive experiments. The results reveal that our method surpasses state-of-the-art methods in both qualitative and quantitative comparisons, capable of generating more realistic motion sequences.
Correlation-Decoupled Knowledge Distillation for Multimodal Sentiment Analysis with Incomplete Modalities
Apr 25, 2024



Multimodal sentiment analysis (MSA) aims to understand human sentiment through multimodal data. Most MSA efforts are based on the assumption of modality completeness. However, in real-world applications, some practical factors cause uncertain modality missingness, which drastically degrades the model's performance. To this end, we propose a Correlation-decoupled Knowledge Distillation (CorrKD) framework for the MSA task under uncertain missing modalities. Specifically, we present a sample-level contrastive distillation mechanism that transfers comprehensive knowledge containing cross-sample correlations to reconstruct missing semantics. Moreover, a category-guided prototype distillation mechanism is introduced to capture cross-category correlations using category prototypes to align feature distributions and generate favorable joint representations. Eventually, we design a response-disentangled consistency distillation strategy to optimize the sentiment decision boundaries of the student network through response disentanglement and mutual information maximization. Comprehensive experiments on three datasets indicate that our framework can achieve favorable improvements compared with several baselines.
Can LLMs' Tuning Methods Work in Medical Multimodal Domain?
Mar 11, 2024



While large language models (LLMs) excel in world knowledge understanding, adapting them to specific subfields requires precise adjustments. Due to the model's vast scale, traditional global fine-tuning methods for large models can be computationally expensive and impact generalization. To address this challenge, a range of innovative Parameters-Efficient Fine-Tuning (PEFT) methods have emerged and achieved remarkable success in both LLMs and Large Vision-Language Models (LVLMs). In the medical domain, fine-tuning a medical Vision-Language Pretrained (VLP) model is essential for adapting it to specific tasks. Can the fine-tuning methods for large models be transferred to the medical field to enhance transfer learning efficiency? In this paper, we delve into the fine-tuning methods of LLMs and conduct extensive experiments to investigate the impact of fine-tuning methods for large models on existing multimodal models in the medical domain from the training data level and the model structure level. We show the different impacts of fine-tuning methods for large models on medical VLMs and develop the most efficient ways to fine-tune medical VLP models. We hope this research can guide medical domain researchers in optimizing VLMs' training costs, fostering the broader application of VLMs in healthcare fields. Code and dataset will be released upon acceptance.
HandGCAT: Occlusion-Robust 3D Hand Mesh Reconstruction from Monocular Images
Feb 27, 2024



We propose a robust and accurate method for reconstructing 3D hand mesh from monocular images. This is a very challenging problem, as hands are often severely occluded by objects. Previous works often have disregarded 2D hand pose information, which contains hand prior knowledge that is strongly correlated with occluded regions. Thus, in this work, we propose a novel 3D hand mesh reconstruction network HandGCAT, that can fully exploit hand prior as compensation information to enhance occluded region features. Specifically, we designed the Knowledge-Guided Graph Convolution (KGC) module and the Cross-Attention Transformer (CAT) module. KGC extracts hand prior information from 2D hand pose by graph convolution. CAT fuses hand prior into occluded regions by considering their high correlation. Extensive experiments on popular datasets with challenging hand-object occlusions, such as HO3D v2, HO3D v3, and DexYCB demonstrate that our HandGCAT reaches state-of-the-art performance. The code is available at https://github.com/heartStrive/HandGCAT.
* 6 pages, 4 figures, ICME-2023 conference paper